Advanced workflows with parallel steps
Create complex workflows in Codefresh with step dependencies
Codefresh is very flexible when it comes to pipeline complexity and depth.
You can easily create:
- Sequential pipelines where step order is the same as the listing order in YAML (simple)
- Sequential pipelines that have some parallel parts (intermediate)
- Parallel pipelines where step order is explicitly defined (advanced)
With the parallel execution mode, you can define complex pipelines with fan-in/out configurations capable of matching even the most complicated workflows within an organization.
NOTE
In Codefresh, parallel execution is unrelated to stages. Stages are only a way to visually organize your pipeline steps. The actual execution is independent from the visual layout in the logs view.
Before going any further make sure that you are familiar with the basics of Codefresh pipelines.
Codefresh offers two modes of execution:
- Sequential mode (which is the default)
- Parallel mode
Sequential execution mode
The sequential mode is very easy to understand and visualize.
In sequential mode, the Codefresh execution engine starts from the first step defined at the top of the codefresh.yml file, and executes all steps one by one going down to the end of the file. A step is either executed or skipped according to its conditions.
NOTE
The condition for each step is only examined once.
YAML
version: '1.0'
mode: sequential
steps:
MyAppDockerImage:
title: Building Docker Image
type: build
image_name: sample-python-image
working_directory: ./
tag: ${{CF_BRANCH_TAG_NORMALIZED}}
dockerfile: Dockerfile
MyUnitTests:
title: Running Unit tests
image: ${{MyAppDockerImage}}
commands:
- python setup.py testHere we have two steps, one that creates a Docker image and a second one that runs unit tests inside it. The order of execution is identical to the order of the steps in the YAML file. This means that unit tests will always run after the Docker image creation.
Notice that the line mode: sequential is shown only for illustration purposes. Sequential mode is the default, and therefore this line can be omitted.
Inserting parallel steps in a sequential pipeline
You don’t have to activate parallel execution mode for the whole pipeline if only a part of it needs to run in parallel. Codefresh allows you insert a parallel phase inside a sequential pipeline with the following syntax:
YAML
version: '1.0'
steps:
my_task1:
title: My Task 1
[...]
my_parallel_tasks:
type: parallel
steps:
my_task2a:
title: My Task 2A
[...]
my_task2b:
title: My Task 2B
[...]
my_task3:
title: My Task3
[...] In this case tasks 2A and 2B will run in parallel.
The step name that defines the parallel phase (my_parallel_tasks in the example above), is completely arbitrary.
The final order of execution will be
- Task 1
- Task 2A and Task2B at the same time
- Task 3
This is the recommended way to start using parallelism in your Codefresh pipelines. It is sufficient for most scenarios that require parallelism.
NOTE
The names of the parallel steps must be unique within the same pipeline. The parent and child steps should NOT share the same name.
Add timeouts for parallel steps
You can add timeoutsfor parallel steps either by defining a parent timeout inherited by the other parallel steps, or by defining individual timeouts for every step.
NOTES
Thetimeoutfield in thedeployandpending-approvalsteps has a specialized syntax and behavior to match the requirements of these steps.
When both parent and step-specific timeouts are defined for parallel steps, the step-specific timeouts override the parent timeout.
version: '1.0'
steps:
parallel:
type: parallel
timeout: 1m
steps:
first:
image: alpine
second:
image: alpine
timeout: 2m
third:
image: alpine
timeout: null Example: pushing multiple Docker images in parallel
Let’s see an example where a Docker image is created and then we push it to more than one registry. This is a perfect candidate for parallelization. Here is the codefresh.yml:
YAML
version: '1.0'
stages:
- build
- push
steps:
MyAppDockerImage:
title: Building Docker Image
stage: 'build'
type: build
image_name: trivialgoweb
working_directory: ./
tag: '${{CF_BRANCH_TAG_NORMALIZED}}'
dockerfile: Dockerfile
PushingToRegistries:
type: parallel
stage: 'push'
steps:
jfrog_PushingTo_jfrog_BintrayRegistry:
type: push
title: jfrog_Pushing To Bintray Registry
candidate: ${{MyAppDockerImage}}
tag: '${{CF_SHORT_REVISION}}'
registry: bintray
PushingToGoogleRegistry:
type: push
title: Pushing To Google Registry
candidate: ${{MyAppDockerImage}}
tag: '${{CF_SHORT_REVISION}}'
registry: gcr
PushingToDockerRegistry:
type: push
title: Pushing To Dockerhub Registry
candidate: ${{MyAppDockerImage}}
tag: '${{CF_SHORT_REVISION}}'
image_name: kkapelon/trivialgoweb
registry: dockerhub The order of execution is the following:
- MyAppDockerImage (build step)
- jfrog_PushingTo_jfrog_BintrayRegistry, PushingToGoogleRegistry, PushingToDockerRegistry (push steps)
The pipeline view for this yaml file is the following.
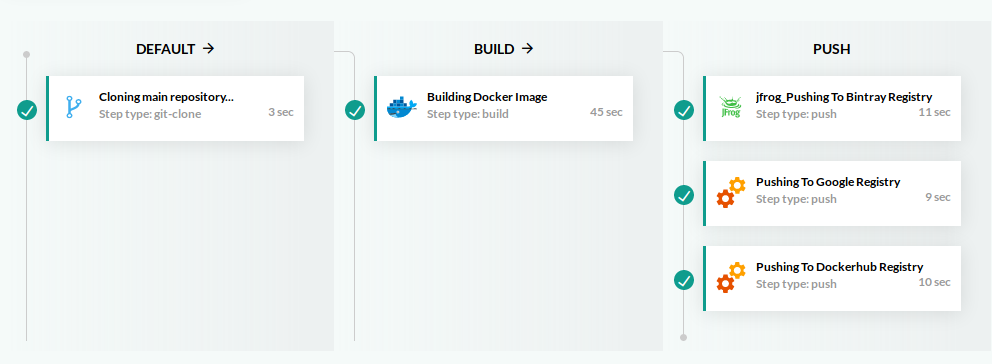
As you can see we have also marked the steps with stages so that we get a visualization that matches the execution.
Example: Running multiple test suites in parallel
All types of steps can by placed inside a parallel phase. Another common use case would be the parallel execution of freestyle steps for unit/integration tests.
Let’s say that you have a Docker image with a Python back-end and a JavaScript front-end. You could run both types of tests in parallel with the following yaml syntax:
YAML
version: '1.0'
steps:
MyAppDockerImage:
title: Building Docker Image
type: build
image_name: my-full-stack-app
working_directory: ./
tag: '${{CF_BRANCH_TAG_NORMALIZED}}'
dockerfile: Dockerfile
MyTestingPhases:
type: parallel
steps:
my_back_end_tests:
title: Running Back end tests
image: ${{MyAppDockerImage}}
commands:
- python setup.py test
my_front_end_tests:
title: Running Front End tests
image: ${{MyAppDockerImage}}
commands:
- npm run testRunning different types of tests (unit/integration/load/acceptance) in parallel is a very common use case for parallelism inside an otherwise sequential pipeline.
Defining success criteria for a parallel step
By default, any failed step in a Codefresh pipeline will fail the whole pipeline. You can change the default execution behavior through the fail_fast field, but specifically for parallel steps you can define exactly when the whole step succeeds or fails.
You can define steps that will be used to decide if a parallel step succeeds with this syntax:
second_step:
title: Second step
success_criteria:
steps:
only:
- my_unit_tests
type: parallel
steps:
my_unit_tests:
title: Running Back end tests
image: node
commands:
- npm run test
my_integration_tests:
title: Running Integration tests
image: node
commands:
- npm run int-test
my_acceptance_tests:
title: Running Acceptance tests
image: node
commands:
- npm run acceptance-test In the example above, if integration and/or acceptance tests fail, the whole pipeline will continue, because we have defined that only the results of unit test matter for the whole parallel step.
The reverse relationship (i.e., defining steps to be ignored) can be defined with the following syntax
second_step:
title: Second step
success_criteria:
steps:
ignore:
- my_integration_tests
- my_acceptance_tests
type: parallel
steps:
my_unit_tests:
title: Running Back end tests
image: node
commands:
- npm run test
my_integration_tests:
title: Running Integration tests
image: node
commands:
- npm run int-test
my_acceptance_tests:
title: Running Acceptance tests
image: node
commands:
- npm run acceptance-test In the example above we have explicitly defined that even if the integration or acceptance tests fail the whole pipeline will continue.
Shared Codefresh volume and race conditions
In any pipeline step, Codefresh automatically attaches a shared volume that is used to transfer artifacts between steps. The same volume is also shared between steps that run in parallel.
Here is an example where two parallel steps are writing two files. After they finish execution, we list the contents of the project folder.
YAML
version: '1.0'
steps:
WritingInParallel:
type: parallel
steps:
writing_file_1:
title: Step1A
image: alpine
commands:
- echo "Step1A" > first.txt
writing_file_2:
title: Step1B
image: alpine
commands:
- echo "Step1B" > second.txt
MyListing:
title: Listing of files
image: alpine
commands:
- ls The results from the MyListing step is the following:
first.txt second.txt
This illustrates the side effects for both parallel steps that were executed on the same volume.
NOTE
It is your responsibility to make sure that steps that run in parallel play nicely with each other. Currently, Codefresh performs no conflict detection at all. If there are race conditions between your parallel steps, (e.g. multiple steps writing in the same files), the final behavior is undefined. It is best to start with a fully sequential pipeline, and use parallelism in a gradual manner if you are unsure about the side effects of your steps.
Implicit parallel steps
NOTE
If you use implicit parallel steps, you cannot use parallel pipeline mode.
In all the previous examples, all parallel steps have been defined explicitly in a pipeline. This works well for a small number of steps, but in some cases it can be cumbersome to write such a pipeline, especially when the parallel steps are similar.
Codefresh offers two handy ways to lessen the amount of YAML you have to write and get automatic parallelization with minimum effort.
- The
scalesyntax allows you to quickly create parallel steps that are mostly similar (but still differ) - The
matrixsyntax allows you to quickly create parallel steps for multiple combinations of properties
Scale parallel steps (one dimension)
If you look back at the parallel docker push example you will see that all push steps are the same. The only thing that changes is the registry that they push to.
YAML
version: '1.0'
stages:
- build
- push
steps:
MyAppDockerImage:
title: Building Docker Image
stage: 'build'
type: build
image_name: trivialgoweb
working_directory: ./
tag: '${{CF_BRANCH_TAG_NORMALIZED}}'
dockerfile: Dockerfile
PushingToRegistries:
type: parallel
stage: 'push'
steps:
jfrog_PushingTo_jfrog_BintrayRegistry:
type: push
title: jfrog_Pushing To Bintray Registry
candidate: ${{MyAppDockerImage}}
tag: '${{CF_SHORT_REVISION}}'
registry: bintray
PushingToGoogleRegistry:
type: push
title: Pushing To Google Registry
candidate: ${{MyAppDockerImage}}
tag: '${{CF_SHORT_REVISION}}'
registry: gcr
PushingToDockerRegistry:
type: push
title: Pushing To Dockerhub Registry
candidate: ${{MyAppDockerImage}}
tag: '${{CF_SHORT_REVISION}}'
image_name: kkapelon/trivialgoweb
registry: dockerhub This pipeline can be simplified by using the special scale syntax to create a common parent step with all similarities:
YAML
version: '1.0'
stages:
- build
- push
steps:
MyAppDockerImage:
title: Building Docker Image
stage: 'build'
type: build
image_name: trivialgoweb
working_directory: ./
tag: '${{CF_BRANCH_TAG_NORMALIZED}}'
dockerfile: Dockerfile
PushingToRegistries:
stage: 'push'
type: push
tag: '${{CF_SHORT_REVISION}}'
candidate: ${{MyAppDockerImage}}
scale:
jfrog_PushingTo_jfrog_BintrayRegistry:
registry: bintray
PushingToGoogleRegistry:
registry: gcr
PushingToDockerRegistry:
image_name: kkapelon/trivialgoweb
registry: dockerhub You can see now that all common properties are defined once in the parent step (PushingToRegistries) while each push step only contains what differs. Codefresh will automatically create parallel steps when it encounters the scale syntax.
The resulting pipeline is more concise but runs in the same manner as the original YAML. For a big number of parallel steps, the scale syntax is very helpful for making the pipeline definition more clear.
You can use the scale syntax with all kinds of steps in Codefresh and not just push steps. Another classic example would be running tests in parallel with different environment variables.
YAML
run_tests_in_parallel:
stage: 'Microservice A'
working_directory: './my-front-end-code'
image: node:latest
commands:
- npm run test
scale:
first:
environment:
- TEST_NODE=0
second:
environment:
- TEST_NODE=1
third:
environment:
- TEST_NODE=2
fourth:
environment:
- TEST_NODE=3 This pipeline will automatically create 4 parallel freestyle steps. All of them will use the same Docker image and executed the same command (npm run test) but each one will receive a different value for the environment variable called TEST_NODE.
Notice that if you define environment variables on the parent step (run_tests_in_parallel in the example above), they will also be available on the children parallel steps. And if those define, environment variables as well, all environment variables will be available.
Matrix parallel steps (multiple dimensions)
The scale syntax allows you to easily create multiple parallel steps that differ only in a single dimension. If you have multiple dimensions of properties that differ and you want to run all possible combinations (Cartesian product) then the matrix syntax will do that for you automatically.
YAML
version: '1.0'
stages:
- prepare
- test
steps:
main_clone:
title: Cloning main repository...
type: git-clone
repo: 'codefreshdemo/cf-example-unit-test'
revision: 'master'
git: github
stage: prepare
run_my_tests_before_build:
stage: test
working_directory: './golang-app-A'
commands:
- go test -v
matrix:
image:
- golang:1.11
- golang:1.12
- golang:1.13
environment:
- [CGO_ENABLED=1]
- [CGO_ENABLED=0] Here we want run unit tests with 3 different versions of GO and also try with CGO enabled or not. Instead of manually writing 6 parallel steps in your pipeline with all possible combinations, we can simply use the matrix syntax to create the following parallel steps:
- Go 1.11 with CGO enabled
- Go 1.11 with CGO disabled
- Go 1.12 with CGO enabled
- Go 1.12 with CGO disabled
- Go 1.13 with CGO enabled
- Go 1.13 with CGO disabled
The resulting Codefresh YAML is much more compact. Notice that because the environment property in Codefresh is already an array on its own, when we use it with the matrix syntax we need to enclose its value with [] (array of arrays).
You can add more dimensions to a matrix build (and not just two as shown in the example). Here is another example with 3 dimensions:
YAML
version: '1.0'
stages:
- prepare
- test
steps:
main_clone:
title: Cloning main repository...
stage: prepare
type: git-clone
repo: 'codefresh-contrib/spring-boot-2-sample-app'
revision: master
git: github
MyUnitTests:
stage: test
matrix:
image:
- 'maven:3.5.2-jdk-8-alpine'
- 'maven:3.6.2-jdk-11-slim'
- 'maven:3-jdk-8'
commands:
- ["mvn --version", "mvn -Dmaven.repo.local=/codefresh/volume/m2_repository test"]
- ["mvn --version", "mvn -Dmaven.test.skip -Dmaven.repo.local=/codefresh/volume/m2_repository package"]
environment:
- [MAVEN_OPTS=-Xms1024m]
- [MAVEN_OPTS=-Xms512m] This pipeline creates 3 x 2 x 2 = 12 parallel steps with all the possible combinations of:
- Maven version
- Running or disabling tests
- Using 1GB or 512MBs of memory.
Remember that all parallel steps run within the same pipeline executor so make sure that you have enough resources as the number of matrix variations can quickly grow if you add too many dimensions.
Notice that, as with the scale syntax, the defined values/properties are merged between parent step (MyUnitTests in the example above) and children steps. For example, if you set an environment variable on the parent and also on child matrix steps , the result will a merged environment where all values are available.
Parallel pipeline execution
NOTE
If you use parallel execution mode for pipelines, you cannot use implicit parallel steps.
To activate advanced parallel mode for the whole pipeline, you need to declare it explicitly at the root of the codefresh.yml file:
version: '1.0'
mode: parallel
steps:
[...]
In full parallel mode, the order of steps inside the codefresh.yml does not affect the order of execution at all. The Codefresh pipeline engine instead:
- Evaluates all step-conditions at the same time
- Executes those that have their requirements met
- Starts over with the remaining steps
- Stops when there are no more steps to evaluate
This means that in parallel mode the conditions of a step are evaluated multiple times as the Codefresh execution engine tries to find which steps it should run next. This implication is very important when you try to understand the order of step execution.
Notice also that in parallel mode, if you don’t define any step conditions, Codefresh will try to run all steps at once, which is probably not what you want in most cases.
With parallel mode you are expected to define the order of steps in the yaml file, and the Codefresh engine will create a graph of execution that satisfies your instructions. This means that writing the codefresh.yml file requires more effort on your part, but on the other hand allows you to define the step order in ways not possible with the sequential mode. You also need to define which steps should depend on the automatic cloning of the pipeline (which is special step named main_clone).
In the next sections we describe how you can define the steps dependencies in a parallel pipeline.
Single step dependencies
At the most basic level, you can define that a step depends on the execution of another step. This dependency is very flexible as Codefresh allows you run a second step once:
- The first step is finished with success
- The first step is finished with failure
- The first completes (regardless of exit) status
The syntax for this is the following post-condition:
second_step:
title: Second step
when:
steps:
- name: first_step
on:
- successIf you want to run the second step only if the first one fails the syntax is:
second_step:
title: Second step
when:
steps:
- name: first_step
on:
- failureFinally, if you don’t care about the completion status the syntax is:
second_step:
title: Second step
when:
steps:
- name: first_step
on:
- finishedNotice that success is the default behavior so if you omit the last two lines (i.e., the on: part) the second step
will wait for the next step to run successfully.
NOTE
The namemain_cloneis reserved for the automatic clone that takes place in the beginning of pipelines that are linked to a git repository. You need to define which steps depend on it (probably the start of your graph) so thatgit checkouthappens before the other steps.
As an example, let’s assume that you have the following steps in a pipeline:
- A build step that creates a Docker image
- A freestyle step that runs unit tests inside the Docker image
- A freestyle step that runs integrations tests After the unit tests, even if they fail
- A cleanup step that runs after unit tests if they fail
Here is the full pipeline. Notice the explicit dependency to the main_clone step that checks out the code.
YAML
version: '1.0'
mode: parallel
steps:
MyAppDockerImage:
title: Building Docker Image
type: build
image_name: my-node-js-app
working_directory: ./
tag: '${{CF_BRANCH_TAG_NORMALIZED}}'
dockerfile: Dockerfile
when:
steps:
- name: main_clone
on:
- success
MyUnitTests:
title: Running unit tests
image: ${{MyAppDockerImage}}
fail_fast: false
commands:
- npm run test
when:
steps:
- name: MyAppDockerImage
on:
- success
MyIntegrationTests:
title: Running integration tests
image: ${{MyAppDockerImage}}
commands:
- npm run integration-test
when:
steps:
- name: MyUnitTests
on:
- finished
MyCleanupPhase:
title: Cleanup unit test results
image: alpine
commands:
- ./cleanup.sh
when:
steps:
- name: MyUnitTests
on:
- failure If you run the pipeline you will see that Codefresh automatically understands that MyIntegrationTests and MyCleanupPhase can run in parallel right after the unit tests finish.
Also notice the fail_fast: false line in the unit tests.
By default, if any step fails in a pipeline, the whole pipeline is marked as a failure. With fail_fast set to false as in the example, we can allow the pipeline to continue and complete execution.
Multiple step dependencies
A pipeline step can also depend on multiple other steps.
The syntax is:
third_step:
title: Third step
when:
steps:
all:
- name: first_step
on:
- success
- name: second_step
on:
- finished In this case, the third step will run only when BOTH first and second are finished (and first is actually a success)
ALL is the default behavior so it can be omitted if this is what you need. The example above is example the same as below:
third_step:
title: Third step
when:
steps:
- name: first_step
on:
- success
- name: second_step
on:
- finished Codefresh also allows you to define ANY behavior in an explicit manner:
third_step:
title: Third step
when:
steps:
any:
- name: first_step
on:
- success
- name: second_step
on:
- finished Here the third step will run when either the first one OR the second one have finished.
As an example let’s assume this time that we have:
- A build step that creates a docker image
- Unit tests that will run when the docker image is ready
- Integration tests that run either after unit tests or if the docker image is ready (contrived example)
- A cleanup step that runs when both kinds of tests are finished
Here is the full pipeline
YAML
version: '1.0'
mode: parallel
steps:
MyAppDockerImage:
title: Building Docker Image
type: build
image_name: my-node-js-app
working_directory: ./
tag: '${{CF_BRANCH_TAG_NORMALIZED}}'
dockerfile: Dockerfile
MyUnitTests:
title: Running unit tests
image: ${{MyAppDockerImage}}
fail_fast: false
commands:
- npm run test
when:
steps:
- name: MyAppDockerImage
on:
- success
MyIntegrationTests:
title: Running integration tests
image: ${{MyAppDockerImage}}
commands:
- npm run integration-test
when:
steps:
any:
- name: MyUnitTests
on:
- finished
- name: MyAppDockerImage
on:
- success
MyCleanupPhase:
title: Cleanup unit test results
image: alpine
commands:
- ./cleanup.sh
when:
steps:
all:
- name: MyUnitTests
on:
- finished
- name: MyIntegrationTests
on:
- finished In this case Codefresh will make sure that cleanup happens only when both unit and integration tests are finished.
Custom step dependencies
For maximum flexibility you can define a custom condition for a step.
It is hard to describe all possible cases, because Codefresh supports a mini DSL for conditions. All examples mentioned in conditional execution are still valid in parallel pipelines.
For example, run this step only if a PR is opened against the production branch:
my_step:
title: My step
when:
condition:
all:
validateTargetBranch: '"${{CF_PULL_REQUEST_TARGET}}" == "production"'
validatePRAction: '''${{CF_PULL_REQUEST_ACTION}}'' == ''opened'''Run this step only for the master branch and when the commit message does not include “skip ci”:
my_step:
title: My step
when:
condition:
all:
noSkipCiInCommitMessage: 'includes(lower("${{CF_COMMIT_MESSAGE}}"), "skip ci") == false'
masterBranch: '"${{CF_BRANCH}}" == "master"'You can now add extra conditions regarding the completion state of specific steps. A global object called steps contains all steps by name along with a result property with the following possible completion states:
- Success
- Failure
- Skipped (only valid in sequential mode)
- Finished (regardless of status)
- Pending
- Running
Finished is a shorthand for success or failure or skipped. It is only valid when used in step dependencies, and cannot be used in custom conditions.
You can mix and match completion states from any other step in your pipeline. Here are some examples:
my_step:
title: My step
when:
condition:
all:
myCondition: steps.MyUnitTests.result == 'failure' || steps.MyIntegrationTests.result == 'failure'my_step:
title: My step
when:
condition:
any:
myCondition: steps.MyLoadTesting.result == 'success'
myOtherCondition: steps.MyCleanupStep.result == 'success'You can also use conditions in the success criteria for a parallel step. Here is an example
version: '1.0'
stages:
- start
- tests
- cleanup
steps:
MyAppDockerImage:
stage: 'start'
title: Building Docker Image
type: build
image_name: my-full-stack-app
working_directory: ./01_sequential/
tag: '${{CF_BRANCH_TAG_NORMALIZED}}'
dockerfile: Dockerfile
MyTestingPhases:
type: parallel
stage: 'tests'
success_criteria:
condition:
all:
myCondition: ${{steps.my_back_end_tests.result}} === 'success' && ${{steps.my_front_end_tests.result}} === 'success'
steps:
my_back_end_tests:
title: Running Back end tests
image: ${{MyAppDockerImage}}
commands:
- exit 1
my_front_end_tests:
title: Running Front End tests
image: ${{MyAppDockerImage}}
commands:
- echo "Second"
MyCleanupPhase:
stage: 'cleanup'
title: Cleanup unit test results
image: alpine
commands:
- echo "Finished"Handling error conditions in a pipeline
It is important to understand the capabilities offered by Codefresh when it comes to error handling. You have several options at different levels of granularity to select what constitutes a failure and what not.
By default, any failed step in a pipeline will abort the whole pipeline and mark it as failure.
fail_fast with strict_fail_fast
You can use the flag fail_fast: false`:
- In a specific step to ignore it if it fails and continue execution
- At the root level of the pipeline if you want to apply it to all steps
If a parallel step has fail_fast: false in its definition, adding strict_fail_fast: true does not change the Build status returned even if a child step fails. This is because the parallel step itself is considered successful regardless of errors in child steps.
Therefore, if you want your pipeline to keep running to completion regardless of errors, you can add the following:
version: '1.0'
fail_fast: false
steps:
[...]
You also have the capability to define special steps that will run when the whole pipeline has a special completion status. Codefresh offers a special object called workflow that represents the whole pipeline and allows you to evaluate its status in a step.
For example, you can have a cleanup step that will run only if the workflow fails (regardless of the actual step that created the error) with the following syntax:
my_cleanup_step:
title: My Pipeline Cleanup
when:
condition:
all:
myCondition: workflow.result == 'failure'As another example we have a special step that will send an email if the pipeline succeeds or if load-tests fail:
my_email_step:
title: My Email step
when:
condition:
any:
myCondition: workflow.result == 'success'
myTestCondition: steps.MyLoadTesting.result == 'failure'Notice that both examples assume that fail_fast: false is at the root of the codefresh.yaml file.
The possible values for workflow.result are:
runningterminatedfailurepending-approvalsuccess