Hooks in pipelines
Execute commands before/after each pipeline or step
Hooks in pipelines allow you to run specific actions at the end and the beginning of the pipeline, as well as before or after a step.
Hooks can be a freestyle step, as you need to define:
- A Docker image that will be used to run specific commands.
- One or more commands to run within the context of that Docker image.
For simple commands we suggest you use a small image such as alpine, but any Docker image can be used in hooks.
Pipeline hooks
Codefresh allows you to run a specific step before each pipeline as well as after it has finished.
Running a step at the end of the pipeline
You can easily run a step at the end of the pipeline, which will be executed, even if one of the steps have failed and pipeline execution is stopped:
codefresh.yml
version: "1.0"
hooks:
on_finish:
exec:
image: alpine:3.9
commands:
- echo "cleanup after end of pipeline"
steps:
step1:
title: "Step 1"
type: "freestyle"
image: node:10-buster
commands:
- echo "Hello world"
step2:
title: "Step 2"
type: "freestyle"
image: node:10-buster
commands:
- echo "There was an error"
- exit 1 In the example above we define a hook for the whole pipeline that will run a step (the exec keyword) inside alpine:3.9 and will simply execute an echo command. Because we have used the on_finish keyword, this step will execute even if the whole pipeline fails.
This scenario is very common if you have a cleanup step or a notification step that you always want to run at the end of the pipeline. You will see the cleanup logs in the top pipeline step.
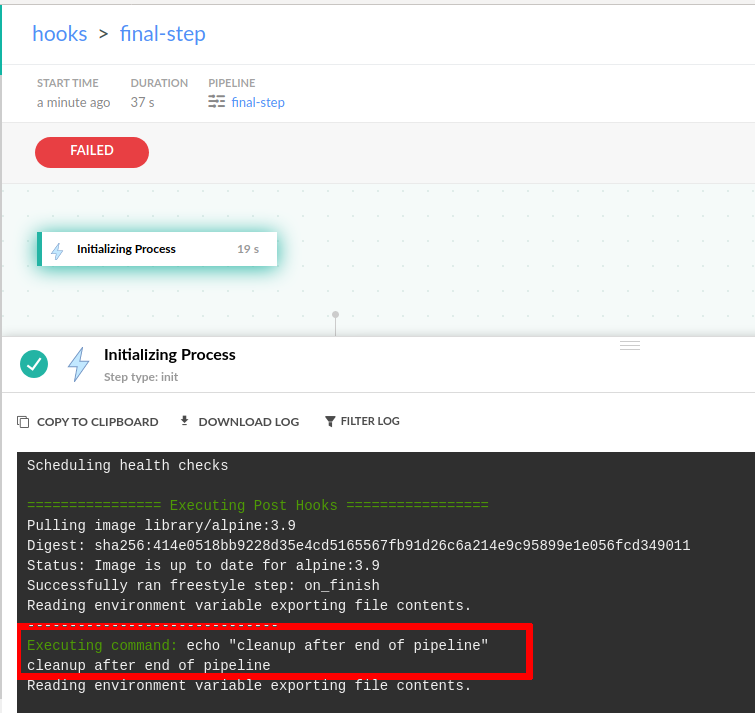
Apart from the on_finish keyword you can also use on_success and on_fail if you want the step to only execute according to a specific result of the pipeline. It is also possible to use multiple hooks at the same time:
codefresh.yml
version: "1.0"
hooks:
on_finish:
exec:
image: alpine:3.9
commands:
- echo "cleanup after end of pipeline"
on_success:
exec:
image: alpine:3.9
commands:
- echo "Send a notification only if pipeline was successful"
on_fail:
exec:
image: alpine:3.9
commands:
- echo "Send a notification only if pipeline has failed"
steps:
step1:
title: "Step 1"
type: "freestyle"
image: node:10-buster
commands:
- echo "Hello world"
step2:
title: "Step 2"
type: "freestyle"
image: node:10-buster
commands:
- echo "There was an error"
- exit 1 #Comment this line out to see how hooks changeNote that if you have multiple hooks like the example above, the on_finish segment will always execute after any on_success/on_fail segments (if they are applicable).
Running a step at the start of the pipeline
Similar to the end of the pipeline, you can also execute a step at the beginning of the pipeline with the on_elected keyword:
codefresh.yml
version: "1.0"
hooks:
on_elected:
exec:
image: alpine:3.9
commands:
- echo "Creating an adhoc test environment"
on_finish:
exec:
image: alpine:3.9
commands:
- echo "Destroying test environment"
steps:
step1:
title: "Step 1"
type: "freestyle"
image: node:10-buster
commands:
- echo "Running Integration tests on test environment"
step2:
title: "Step 2"
type: "freestyle"
image: node:10-buster
commands:
- echo "Running acceptance tests on test environment"All pipeline hooks will be shown in the “initializing process” logs:
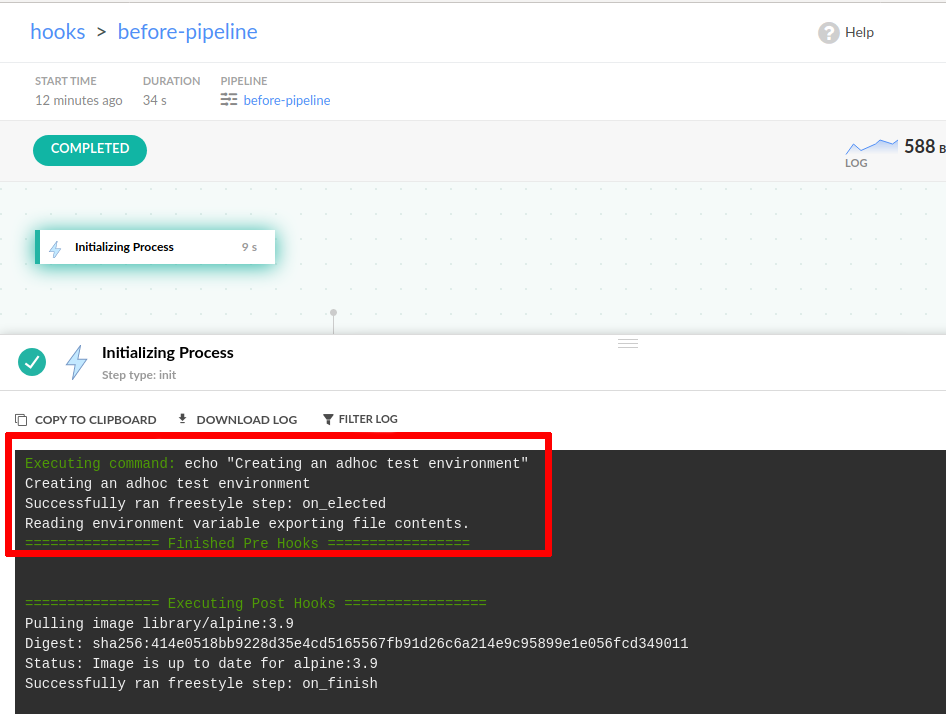
It is possible to define all possible hooks (on_elected, on_finish, on_success, on_fail) in a single pipeline, if this is required by your development process.
Step hooks
You can also define hooks for individual steps inside a pipeline. This capability allows you to enforce more granular control on defining prepare/cleanup phases for specific steps.
The syntax for step hooks is the same as pipeline hooks: on_elected, on_finish, on_success, on_fail. The only difference is that you need to add the respective segment within a step instead of the at the root of the pipeline.
For example, this pipeline will always run a cleanup step after integration tests (even if the tests themselves fail).
codefresh.yml
version: "1.0"
steps:
step1:
title: "Compile application"
type: "freestyle"
image: node:10-buster
commands:
- echo "Building application"
step2:
title: "Unit testing"
type: "freestyle"
image: node:10-buster
commands:
- echo "Running unit tests"
hooks:
on_finish:
exec:
image: alpine:3.9
commands:
- echo "Create test report"
step3:
title: "Uploading artifact"
type: "freestyle"
image: node:10-buster
commands:
- echo "Upload to artifactory"Logs for steps hooks are displayed in the log window of the step itself.
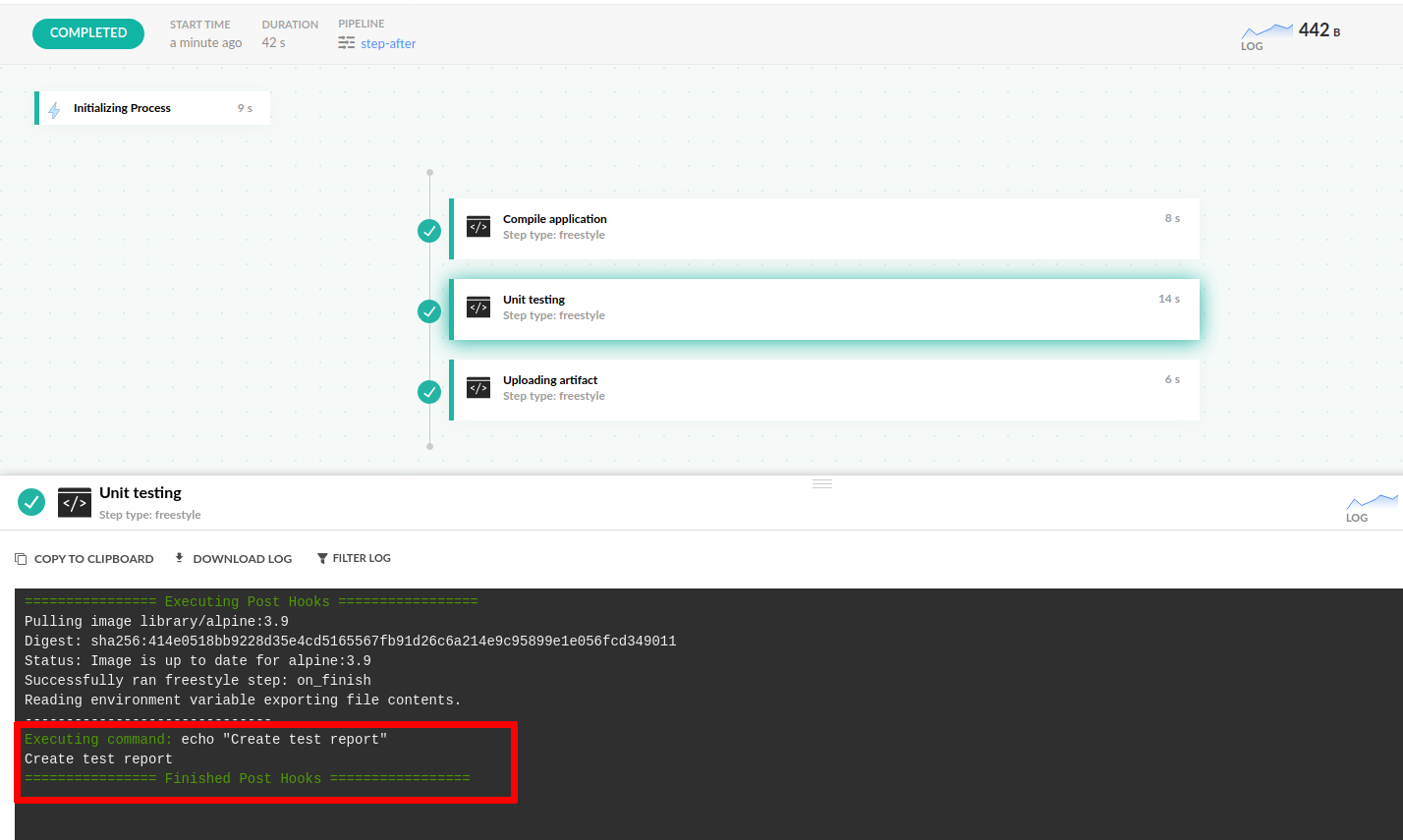
As with pipeline hooks, you can also define multiple hook conditions for each step.
codefresh.yml
version: "1.0"
steps:
step1:
title: "Compile application"
type: "freestyle"
image: node:10-buster
commands:
- echo "Building application"
step2:
title: "Security scanning"
type: "freestyle"
image: node:10-buster
commands:
- echo "Running Security scan"
hooks:
on_elected:
exec:
image: alpine:3.9
commands:
- echo "Authenticating to security scanning service"
on_finish:
exec:
image: alpine:3.9
commands:
- echo "Uploading security scan report"
on_fail:
exec:
image: alpine:3.9
commands:
- echo "Sending slack notification" The order of events in the example above is the following:
- The
on_electedsegment executes first (authentication) - The
Security Scanningstep itself executes the security scan - The
on_failsegment executes only if the step throws an error code - The
on_finishsegment always executes at the end
Running steps/plugins in hooks
Hooks can use steps/plugins.
With plugins you have to specify:
- The type field for the step/plugin
- The arguments needed for the step/plugin
codefresh.yml
version: "1.0"
hooks: #run slack-notifier hook on build completion
on_finish:
steps:
exec:
type: slack-notifier:0.0.8
arguments:
SLACK_HOOK_URL: '${{SLACK_WEBHOOK_URL}}'
SLACK_TEXT: '${{SLACK_TEXT}}'
steps:
step1:
title: "Freestyle step"
type: "freestyle"
image: alpine
commands:
- echo "Codefresh"
hooks: #run slack-notifier hook on step completion
on_finish:
steps:
exec:
type: slack-notifier:0.0.8
arguments:
SLACK_HOOK_URL: '${{SLACK_WEBHOOK_URL}}'
SLACK_TEXT: '${{SLACK_TEXT}}' Controlling errors inside pipeline/step hooks
By default, if a step fails within a pipeline, pipeline execution is terminated and the pipeline is marked as failed.
on_electedsegments
Ifon_electedsegments fail, regardless of the position of the segment in a pipeline or step, the whole pipeline will fail.on_success,on_failandon_finishsegments
on_success,on_failandon_finishsegments do not affect the pipeline outcome. A pipeline will continue execution even if one of these segments fails.
Pipeline execution example with on_elected segment
The following pipeline will fail right away, because the pipeline hook fails at the beginning.
codefresh.yml
version: "1.0"
hooks:
on_elected:
exec:
image: alpine:3.9
commands:
- echo "failing on purpose"
- exit 1
steps:
step1:
title: "Step 1"
type: "freestyle"
image: node:10-buster
commands:
- echo "Running Integration tests on test environment"You can change this behavior by using the existing fail_fast property inside an on_elected hook.
codefresh.yml
version: "1.0"
hooks:
on_elected:
exec:
image: alpine:3.9
fail_fast: false
commands:
- echo "failing on purpose"
- exit 1
steps:
step1:
title: "Step 1"
type: "freestyle"
image: node:10-buster
commands:
- echo "Running Integration tests on test environment"This pipeline will now execute successfully and step1 will still run as normal, because we have used the fail_fast property. You can also use the fail_fast property on step hooks as well:
codefresh.yml
version: "1.0"
steps:
step1:
title: "Step 1"
type: "freestyle"
image: node:10-buster
commands:
- echo "Running Integration tests on test environment"
hooks:
on_elected:
exec:
image: alpine:3.9
fail_fast: false
commands:
- echo "failing on purpose"
- exit 1 NOTE
Thefail_fastproperty is only available foron_electedhooks. The other types of hooks (on_finish,on_success,on_fail) do not affect the outcome of the pipeline in any way. Even if they fail, the pipeline will continue running to completion. This behavior is not configurable.
Using multiple steps for hooks
In all the previous examples, each hook was a single step running on a single Docker image. You can also define multiple steps for each hook. This is possible by inserting an extra steps keyword inside the hook and listing multiple Docker images under it:
codefresh.yml
version: "1.0"
hooks:
on_finish:
steps:
mycleanup:
image: alpine:3.9
commands:
- echo "echo cleanup step"
mynotification:
image: cloudposse/slack-notifier
commands:
- echo "Notify slack"
steps:
step1:
title: "Step 1"
type: "freestyle"
image: node:10-buster
commands:
- echo "Running Integration tests on test environment"By default all steps in a single hook segment are executed one after the other. But you can also run them in parallel:
codefresh.yml
version: "1.0"
steps:
step1:
title: "Compile application"
type: "freestyle"
image: node:10-buster
commands:
- echo "Building application"
step2:
title: "Unit testing"
type: "freestyle"
image: node:10-buster
commands:
- echo "Running Integration tests"
- exit 1
hooks:
on_fail:
mode: parallel
steps:
upload-my-artifact:
image: maven:3.5.2-jdk-8-alpine
commands:
- echo "uploading artifact"
my-report:
image: alpine:3.9
commands:
- echo "creating test report" You can use multiple steps in a hook in both the pipeline and the step level.
Hooks in parallel steps
Hooks are not supported in parallel step types.
However, you can add hooks to any other step type, even if the step is nested within a parallel step, as in the example below.
version: "1.0"
steps:
root_parallel_step:
type: parallel
steps:
child_step_a:
image: alpine
commands:
- exit 0
hooks:
on_finish:
exec:
image: alpine
commands:
- echo "✅ This is a hook in the 'child_step_a' step nested within 'root_parallel_step'. The hook will work because 'child_step_a' is a 'freestyle' step"
child_step_b:
image: alpine
commands:
- exit 0
hooks:
on_finish:
exec:
image: alpine
commands:
- echo "✅ This is a hook in the `child_step_b' step which is also nested within 'root_parallel_step'. The hook will work because 'child_step_b' is a 'freestyle' step"
Referencing the ‘working_directory’ in step hooks
To access the working_directory of a regular step through a hook, use the prefix parentSteps.<step-name> For example, to access the working_directory of the clone step, use ${{parentSteps.clone}} .
Using annotations and labels in hooks
The hook syntax can also be used as a unified interface for encompassing the existing syntax of build annotations and metadata.
codefresh.yml
version: "1.0"
hooks:
on_elected:
exec:
image: alpine:3.9
commands:
- echo "Creating an adhoc test environment"
annotations:
set:
- entity_type: build
annotations:
- my_annotation_example1: 10.45
- my_string_annotation: Hello World
steps:
clone:
title: Cloning source code
type: git-clone
arguments:
repo: 'codefresh-contrib/golang-sample-app'
revision: master
build-image:
type: build
image_name: my-golang-image
working_directory: '${{clone}}'
tag: master
hooks:
on_success:
exec:
image: alpine:3.9
commands:
- echo "Scanning docker image"
metadata: # setting metadata
set:
- '${{build-image.imageId}}':
- status: 'Success' Note however, that if you decide to use annotations and metadata inside hooks, you cannot mix and max the old syntax with the new syntax.
The following pipeline is NOT valid:
invalid-codefresh.yml
version: "1.0"
steps:
test:
image: alpine
on_success: # you cannot use old style together with hooks
annotations:
set:
- entity_type: build
annotations:
- status: 'success'
commands:
- echo block
hooks:
on_success:
annotations:
set:
- entity_type: build
annotations:
- status: 'success' The pipeline is not correct, because the first segment of annotations is directly under on_success (the old syntax), while the second segment is under hooks/on_success (the new syntax).
Syntactic sugar syntax
We offer the following options to simplify the syntax for hooks.
Not using metadata or annotations in your hook
Omit the keyword exec:
codefresh.yml
version: "1.0"
hooks:
on_finish: # no exec keyword
image: notifications:master
commands:
- ./send_workflow_finished.js
steps:
build:
type: build
image_name: my_image
tag: master
hooks:
on_fail: # no exec keyword
image: notifications:master
commands:
- ./send_build_failed.jsNot specifying the Docker image
If you do not want to specify the Docker image you can simply omit it. Codefresh will use the alpine image in that case to run the hook:
codefresh.yml
version: "1.0"
hooks:
on_elected:
exec: # no image keyword - alpine image will be used
- echo "Pipeline starting"
steps:
build:
type: build
image_name: my_image
tag: master
hooks:
on_success: # no image keyword - alpine image will be used
exec:
- echo "Docker image was built successfully"
annotations:
set:
- entity_type: build
annotations:
- status: 'Success'Using Type Steps/Plugins in hooks
You can use a type step / plugins in hooks. With this you will need to change exec into steps with the information needed for the step.
Below is an example pipeline hook using the slack-notifier step/plugin for when the pipeline starts.
hooks:
on_elected:
exec:
steps:
slack_pending:
type: slack-notifier:0.0.8
arguments:
SLACK_HOOK_URL: '${{SLACK_WEBHOOK_URL}}'
SLACK_TEXT: '*Build Started* now'Limitations of pipeline/step hooks
The current implementation of hooks has the following limitations:
- The debugger cannot inspect commands inside hook segments.
- Storage integrations don’t resolve in hooks (for example, test reports).
Related articles
Conditional execution of steps
Working directories
Build step in pipelines
Annotations in pipelines