Building microservices
Create pipelines specifically for microservice applications
Now that you know how to build your app and create Docker images, we can see how Codefresh works with microservice applications.
Organizing pipelines for monolithic applications
In the past, pipelines for monolithic applications tended to share the same characteristics of the application they were building. Each project had a single pipeline which was fairly complex, and different projects had completely different pipelines. Each pipeline was almost always connected to a single Git repository.
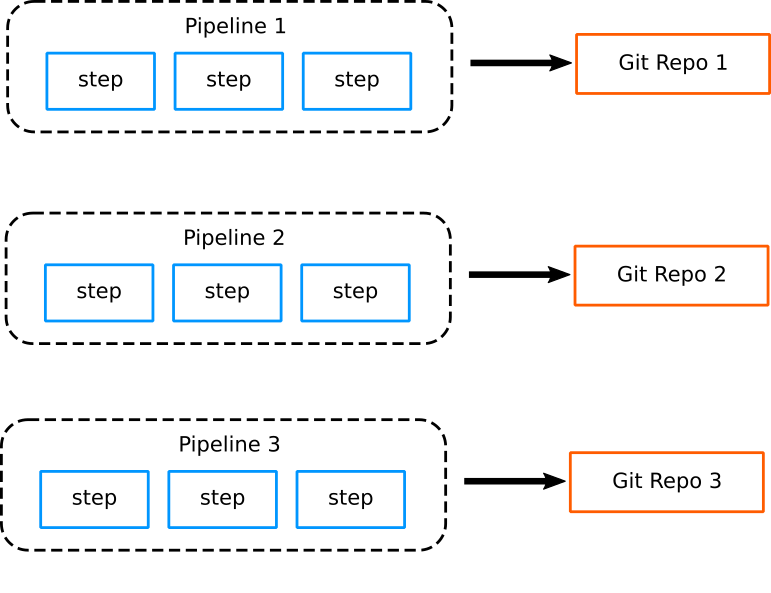
The complexity of each pipeline was detrimental to easy maintenance. Pipelines were typically controlled by a small team of gurus, familiar with both the internals of the application as well as the deployment environment.
For each software project, operators handle the pipeline structure, while developers only work with the source code (going against the DevOps paradigm where all teams should share responsibility for common infrastructure and collaborate on shared problems).
Pipeline size and complexity is often a huge pain point. Even though several tools exist for the continuous integration part of a monolithic application, continuous deployment being a different matter completely, forced a lot of companies to create their own custom in-house scripts to take care of deployment.
Scalability issues with microservice pipelines
Microservices have of course several advantages regarding deployment and development, but they also come with their own challenges. Management of microservice repositories and pipelines becomes much harder as the number of applications grows.
While a company might have to deal with 1–5 pipelines in the case of monolith applications (assuming 1–5 projects), the number quickly jumps to 25 if each monolith is divided into 5 microservices.
These numbers are different per organization. It is perfectly normal for an application to have 10 microservices. So at a big organization that has 50 applications, the operator team is suddenly tasked with the management of 500+ pipelines.
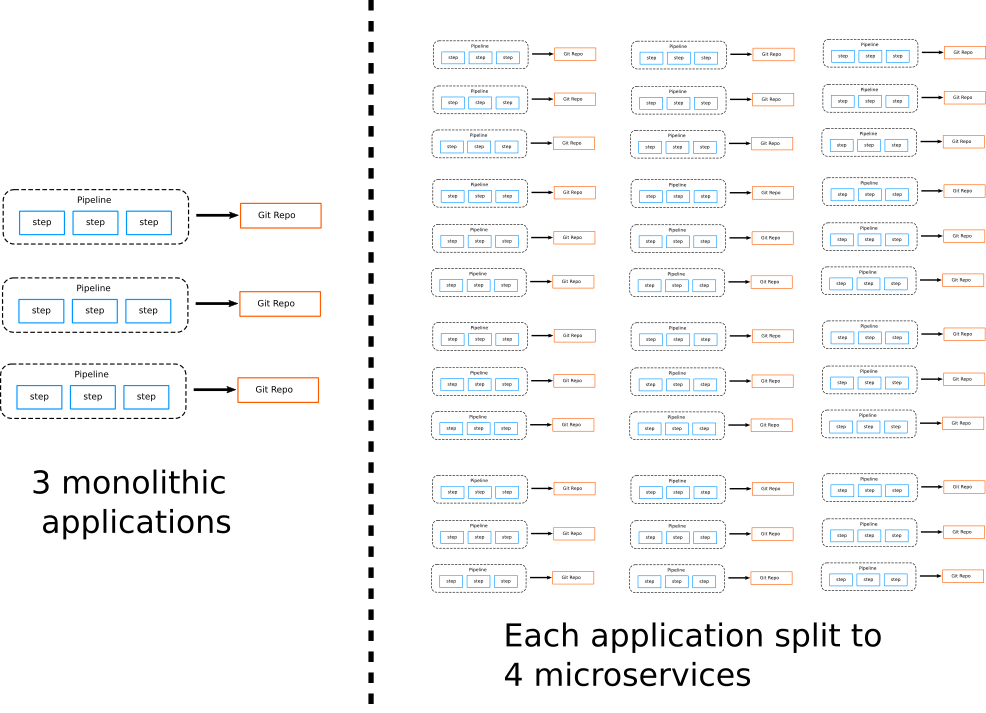
This sudden explosion in numbers prohibits working manually with pipelines anymore. Several CI solutions do not have the capacity to work with such a high number of pipelines.
Here is where we reach the biggest pitfall regarding pipeline management in the era of microservices. Several companies tried to solve the problem of microservice pipelines using shared pipeline segments.
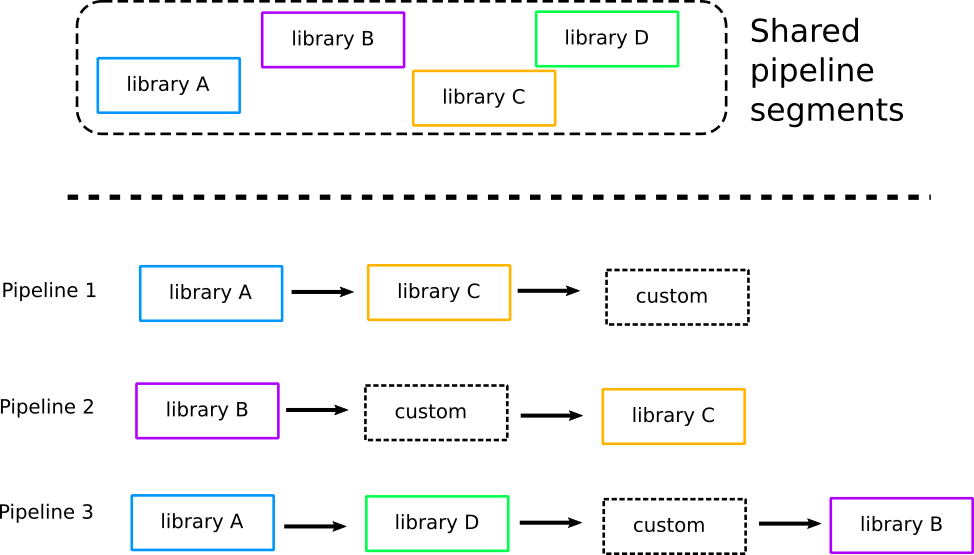
In theory, this sounds like a good idea:
- Operators locate the common parts of pipelines with applications
- A shared pipeline segment registry is created to hold all those common parts
- Pipelines in existing projects are re-engineered to depend on the common segments
- New projects must first examine the library of common pipeline segments and choose what is already there
The final result is that a single pipeline is actually composed of two types of steps, those common to other pipelines, and those that are specific to that project only.
This has lead to the development of several solutions which attempt to centralize common pipeline parts and re-use them in the form of “libraries” within software projects. The issue here is that this approach requires a very large time investment as well as a disciplined team that can communicate and cooperates on the following factors:
- Detecting which pipeline segments are indeed common,
- Keeping the library of common pipeline segments up-to-date,
- Disallowing copy-pasting of pipelines,
- Development of brand new pipelines when needed,
- Initial setup and pipeline bootstrap for each new project created.
Unfortunately, in practice, as the number of microservice applications grows, teams find it very hard to keep all these principles in mind when creating new projects.
Reusing pipelines for microservice applications
Codefresh is the first CI/CD solution for microservices and containers. Because we are not burdened with any legacy decisions, we are free to define a new model for Codefresh pipelines which is focused on microservices.
The basic idea is that all microservices of a single application have almost always the same lifecycle. They are compiled, packaged, and deployed in a similar manner. Once this realization is in place, we can see that instead of having multiple pipelines for each microservice, where each one is tied to a Git repository, we have instead a single pipeline shared by all microservices.
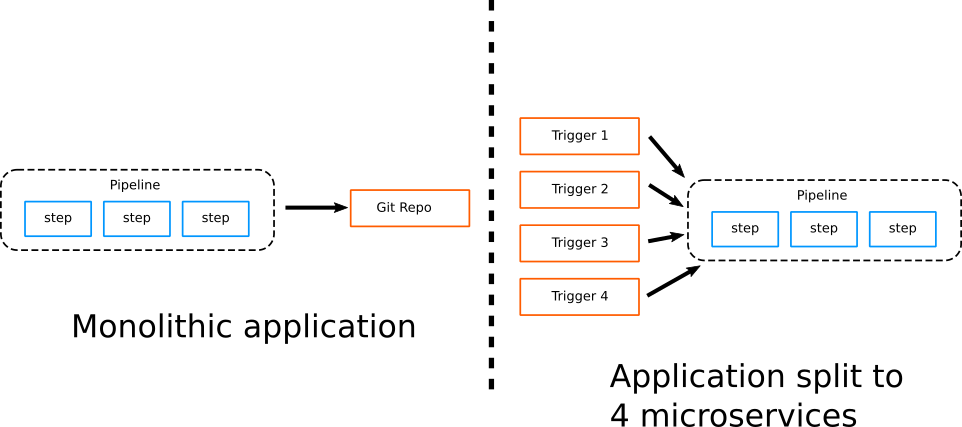
The impact of this design cannot be understated. First of all, it should be clear that there is no need for sharing pipeline segments anymore. The whole pipeline is essentially the re-usable unit.
This makes pipeline construction very simple.
The biggest advantage, however, is the way new projects are created. When a new microservice is added in an application, the pipeline is already there and only a new trigger is added for that microservice. Notice that the pipeline is not connected to any specific Git repository anymore. All information for a repository is coming from the git trigger that started this pipeline.
As an operator you can bootstrap a new project by quickly adding a new trigger on an existing pipeline:

This is the fastest way possible to bootstrap a new project. As the number of microservices is growing, the only thing that is growing is the list of triggers. All pipelines are exactly the same.
Creating reusable pipelines
When working with microservices you need to remember that:
- In Codefresh a pipeline can stand on its own. It is not connected by default to any Git repository.
- You can write Codefresh pipelines in a generic manner so that they can work with multiple applications.
- If you connect multiple triggers to a single pipeline, all microservices will share that pipeline.
- You can create multiple pipelines for each project if you have microservices with slightly different architecture.
To create a reusable pipeline use the generic form of the clone step:
codefresh.yml
version: "1.0"
steps:
clone:
title: "Cloning repository"
type: "git-clone"
repo: '${{CF_REPO_OWNER}}/${{CF_REPO_NAME}}'
revision: '${{CF_REVISION}}'
compile:
title: "Create JAR"
type: "freestyle"
image: 'maven:3.5.2-jdk-8-alpine'
working_directory: "${{clone}}"
commands:
- 'mvn -Dmaven.repo.local=/codefresh/volume/m2_repository package' This pipeline uses variables in the clone step. These variables are automatically populated by the respective trigger. So you can connect this pipeline to any number of Java repositories and it will work on all of them (assuming they use Maven).
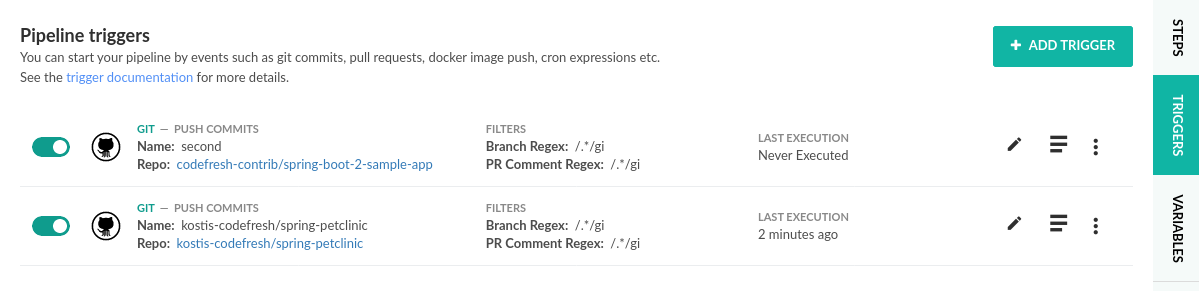
Any time you run the pipeline you can select which trigger/branch you will use. So in the first case the values will be like this:
CF_REPO_OWNER=kostis-codefreshCF_REPO_NAME=spring-petclinicCF_REVISION=another-branch
In the second case the values will be replaced like this:
CF_REPO_OWNER=codefresh-contribCF_REPO_NAME=spring-boot-2-sample-appCF_REVISION=master
You can follow the same pattern for any other kind of application (NodeJS, Python, Ruby etc.)
Adding a new microservice to an existing application
As an example, let’s say that you have an application with five microservices. Two of them use Java and three use NodeJs. You can easily create two pipelines for the whole application, one for each programming language.
However, if you take advantage of multistage Docker builds, you could even have a single pipeline for all five services:
codefresh.yml
version: "1.0"
steps:
clone:
title: "Cloning repository"
type: "git-clone"
repo: '${{CF_REPO_OWNER}}/${{CF_REPO_NAME}}'
revision: '${{CF_REVISION}}'
build_app_image:
title: Building Docker Image
type: build
stage: build
image_name: '${{CF_REPO_NAME}}'
working_directory: ./
tag: 'multi-stage'
dockerfile: Dockerfile
deploy_to_k8s:
title: Deploy to cluster
type: deploy
kind: kubernetes
cluster: 'production-gke'
namespace: default
service: '${{CF_REPO_NAME}}'
candidate:
image: '${{build_app_image}}' This pipeline:
- Checks out source code from any connected trigger
- Creates a Docker image (assumes a multistage Dockerfile)
- Deploys the image to a Kubernetes cluster
Now, if you add another microservice to the application, you can simply add a new trigger making the addition as easy as possible:
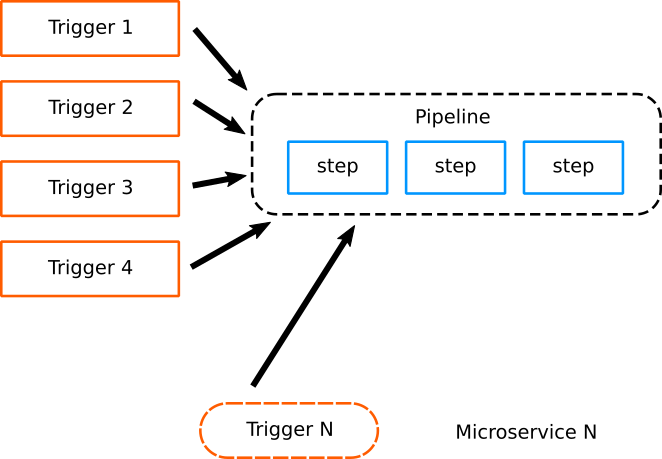
This is just an example pipeline. You might have another generic pipeline for Helm deployments, FTP uploads, VM images and so on.
Related articles
Creating pipelines
Git triggers in pipelines
Codefresh YAML for pipeline definitions
Steps in pipelines