Article Content
What Is Software Deployment (Application Deployment)?
Software or application deployment is the process required to make new or updated software available to its users. Most organizations today automate at least some of the steps involved in deploying new applications. Many organizations are adopting a deployment model known as continuous delivery, in which software releases are constantly in a deployable state and can be deployed to production fully automatically at the click of a button.
Software deployment typically includes activities such as provisioning environments, installing, and testing software. Deployment should also include ongoing monitoring of the health and performance of newly deployed environments, and the ability to roll back a deployment if something goes wrong.
Software deployment and software release may seem synonymous, but they serve two different functions. Software release is an iterative process of developing an application, while software deployment is the process of rolling out an application. A new release can include additional functionality, bug fixes, or security patches. Software deployment involves pushing software to an IT environment or delivering it to end-users.
This is part of an extensive series of guides about CI/CD
Software Deployment Checklist
While each software deployment model operates differently, there are several phases each deployment process should follow. This is a quick checklist for effective deployments:
Preparation
Here are important steps to implement during the planning phase:
- Notify all stakeholders—it is critical to inform all users about the upcoming deployment and teach users how to use the new features rolled out.
- Identify collaborators—the software development lifecycle (SDLC) is a collaborative process that can involve disparate teams. You should identify and inform all collaborators to minimize friction between development, operations, and security teams.
- List third-party tools—identifying all tools and requirements involved in the deployment process can help you ensure all collaborators know how to use them effectively and minimize any issues related to these tools.
- Set up a testing environment—always test your software before rolling out the new product to end users.
- Design a clear deployment process—communicate with the team to ensure the deployment process is clear to all involved and everyone is on the same page.
- Create a rollback plan—use this plan if critical problems arise during the deployment. Progressive delivery strategies make it possible to roll back deployments seamlessly and automatically (learn more below).
- Identify performance metrics—common metrics include memory and CPU usage and query response times. You can use these basic metrics and custom KPIs to measure the effectiveness of a deployment. In progressive delivery, you can even use these metrics to automatically determine whether the deployment succeeded or failed.
Testing
The testing phase validates your software before deployment. Here are important aspects to cover during this phase:
- Write unit tests—the goal is to test a small portion of the software to verify its behavior independently from the other portions. A unit test passes when the result is consistent with requirements and fails if it gives an inconsistent result.
- Integrate tests with the CI process—integrate your unit tests into a shared repository to automatically build and verify each portion. Doing this before deployment enables you to fix and remove bugs more easily than fixing in production.
- Deploy tests in a staging environment—create an exact reproduction of the targeted production environment and use it to test updates, code, and other aspects to ensure the software works as intended before deployment.
- Run end-to-end tests to look for regression—the goal is to test an application’s workflow from start to end, going through all the operations it can perform to check how it works with other components like network connectivity and hardware.
- Acceptance testing—this final step of the testing process verifies the software with stakeholders or real users. Their feedback helps determine whether the software is ready for production or not. In a continuous delivery process, this can be handled by the concept of acceptance gates, in which an automated deployment waits for manual approval and then proceeds.
- Use smoke tests—create a dedicated test suite for running it in production AFTER the deployment to verify that the software that was just released doesn’t have any regressions.
Deployment and Release Process
This final phase covers important aspects of implementing the deployment and involves:
- Deploy to production—push the update to the production environment where users interact with the software.
- Monitor product performance—use your predetermined KPIs to monitor the product’s performance, checking for aspects like HTTP errors and database performance.
- Monitor environment health—use monitoring tools to identify potential issues related to the software environment, like the operating system, database system, and compiler.
- Perform automated rollbacks—use smoke tests and metrics to decide if the release was successful or not and automatically go to the previous release if there are issues.
- Track logs—you can use logs to gain visibility into how the software runs on infrastructure components, investigate errors, and identify security threats.
- Document release versioning and notes—keeping copies of new versions created when you make changes to the product helps maintain consistency.
Learn more in our detailed guide to environment promotion

VP of Open Source, Octopus Deploy
Dan is a seasoned leader in the tech industry with a strong focus on open source initiatives. Currently serving as VP of Open Source at Octopus Deploy, contributing as an Argo maintainer, co-creator of Open GitOps, and leveraging extensive experience as a co-founder of Codefresh, now part of Octopus Deploy.
TIPS FROM THE EXPERT
- Adopt GitOps for deployment management: By using Git as the source of truth for your deployments (e.g., with tools like Argo CD), you can streamline your CI/CD pipeline, improve auditability, and automate rollbacks.
- Implement infrastructure as code (IaC): Using tools like Terraform or CloudFormation to manage your infrastructure can ensure consistency and enable automated, repeatable deployments.
- Implement dark launches: Release new features to a small subset of users without making them publicly visible. This allows for real-world testing and feedback while minimizing risk.
- Enhance observability with distributed tracing: Use tools like Jaeger or Zipkin to trace requests across your microservices, providing insights into performance bottlenecks and aiding in debugging complex issues.
- Optimize database deployment strategies: Automate database schema changes with tools like Flyway or Liquibase, and ensure your deployment strategy includes thorough data migration testing and rollback procedures to handle any failures seamlessly.
Software Deployment Strategies
Here are some of the main software deployment strategies:
1. Basic Deployment
A basic deployment involves updating every node in the target environment simultaneously to introduce a new version. This strategy is vulnerable to outages and makes it harder to roll back an update. While basic deployment is fast, simple, and cost-effective, It carries the highest risk and is thus unsuitable for business-critical application services.
2. Rolling Deployment
rolling deployment involves updating a subset of application instances (instead of the full update of a basic deployment). The window size refers to the number of instances updated at a time. The larger the cluster, the larger the window size should be.
Rolling updates offer flexibility in scaling up the new version before scaling down the old version (i.e., surge upgrade) and limiting the application instances remaining unavailable during the scale-up.
This approach eliminates downtime because it only redirects traffic to the new version when it is ready. It also reduces the deployment risk because flawed updates affect a limited number of users. However, rollback can be slow as it also requires a gradual approach. New deployments must be backward compatible because they coexist with old versions. It is also important to ensure the load balancer supports sticky sessions if the application requires sessions to persist.
Learn more in our detailed guide to rolling deployment
3. Multi-Service Deployment
A multi-service deployment simultaneously updates every node in the target environment with multiple services. This approach is similar to basic deployment but carries less risk and is useful for applications with version or service dependencies. While multi-service deployments are fast and cost-effective, they are vulnerable to outages and slow to roll back. This strategy can also make testing, verifying, and managing service dependencies harder.
4. Blue/Green Deployment
A blue/green deployment involves deploying two versions of the application simultaneously. The current version (blue) and the new version (green) run in separate environments, with only one live version at any time. The blue version continues to run while the green version undergoes testing. When the new deployment is ready, it is safe to switch the traffic, either decommissioning the old version or retaining it for future rollback. In some cases, the blue environment becomes green for the next update.
Blue/green deployments eliminate downtime and allow instant rollbacks. The isolation of blue and green environments protects the live deployment from bugs during the testing phase. However, while this deployment strategy is less risky, it is more expensive to implement because the operational overhead must cover two environments.
Ensuring backward compatibility is essential for enabling seamless rollbacks. During the cutover, it is preferable to allow connection draining on current sessions to enable existing requests to complete.
Learn more in the detailed guide to Blue green deployment in Kubernetes
5. Canary Deployment
A canary deployment involves releasing a service or application in increments. In the first stage, the update is rolled out to a small subset of users (for example, 2%). The rollout gradually continues, increasing the scope to larger user subsets until it reaches 100%.
This approach carries the least risk of any deployment strategy, allowing teams to control and test live updates. It enables the assessment of performance in the real-world production environment rather than a simulated staging environment. It also eliminates downtime and enables fast rollbacks.
A possible drawback of canary deployments is their slow rollout. Each release increment takes time, requiring monitoring for at least several hours. Another challenge is maintaining observability over the application stack and infrastructure—monitoring often requires effort. As with other deployment strategies, it is crucial to ensure session stickiness and backward compatibility to ensure a smooth transition.
Learn more in our detailed guide to canary deployment
6. A/B Testing
A/B testing involves routing a small subset of users to the new functionality to collect statistics and help inform business decisions. While not strictly a deployment strategy, it is a testing approach that builds on the canary deployment strategy. Companies use A/B testing to determine which feature version has the best conversion rate.
This technique is the best way to measure the effectiveness of an application’s functionality. It helps ensure safe software releases and predictable rollbacks. The target audience sample is easy to manage and helps provide user engagement and behavior statistics. However, setting up an A/B test is complex, requiring representative audience samples, and it may be difficult to guarantee the validity of the test results. Another challenge is maintaining observability across multiple A/B tests.
7. Shadow Deployment
A shadow deployment involves releasing two parallel versions of the software, forking the incoming requests to the current version, and sending them to the new version. This approach helps test how new features handle production load without affecting traffic. When the new version meets the performance and stability requirements, it is safe to roll out the application.
While this strategy is highly specialized and complex to set up, it eliminates impact on production, using traffic duplication to test bugs using shadow data. The tests are highly accurate because they use production load to create realistic conditions. Shadow deployment is considered a low-risk approach and is often combined with other secure strategies like canary deployment.
However, traffic shadowing can produce unwanted side effects, such as duplicating payment transactions. Virtualization tools and stubs can help reduce this risk for services mutating state or interacting with third-party systems. Another drawback is the cost of implementation due to the expertise required and the need to run two environments simultaneously.
What Is Progressive Delivery?
Progressive delivery is a software development paradigm that provides better control over the delivery of software updates. It involves creating a continuous integration and continuous delivery (CI/CD) pipeline with several flexible techniques for rolling out new versions of a software product. Here are core concepts of progressive delivery:
- CI/CD pipelines—automate building, testing, and deployment tasks.
- Feature flag management—enables turning features on and off during production. It helps teams make changes to features in production and release updates quickly.
- Progressive deployment—introduces techniques like canary, blue-green, A/B testing, and roll-out deployments. We cover these in more detail below.
Learn more in our detailed guide to progressive delivery (coming soon)
5 Tips for Software Deployment Success
The following best practices can help you deploy software more effectively.
Keep Separate Clusters for Production and Non-Production
Having one large cluster for everything creates issues for resource consumption and security. It is essential to have at least two clusters, one for production and one for non-production resources. Keeping clusters separate helps prevent communication between the pods in each cluster.
This best practice helps prevent scenarios where the developer deploys a test feature in a namespace on the cluster housing production. If the developer runs integration tests on the feature, they may impact the back end production workloads. Using different namespaces is not sufficient for separating environments.
While multi-tenancy is possible in a single cluster, it requires significant expertise and effort to achieve. Creating separate clusters is usually easier. Some organizations create several dedicated clusters, including production, shadow, developer, tool, and other specialized clusters. At the very least, the production cluster should be separate from anything else.
Apply Resource Limits
By default, there are no resource limits when deploying an application to Kubernetes. Without specified limits, applications can consume the entire cluster, disrupting performance in a production cluster. Every application should have resource limits—developers might not handle this themselves, but they should know what CPU and memory limits to set.
It is important to consider potential traffic and load bursts, not just average consumption, when setting limits. Kubernetes provides resource elasticity, but it is important to strike the right balance. If the limit is too low, the cluster can crash the application. If it is too high, the cluster becomes inefficient.
Resource limits should also take into account the programming languages used. For example, Java apps often have issues with memory limits. It is possible to automate resource allocation using an auto-scaler.
Collect Deployment Metrics
Kubernetes clusters have distributed services supporting dynamic applications, so it is important to have appropriate metrics to enable the applications to adapt to traffic. Metrics are important for obtaining crucial information quickly without kubectl, understanding traffic patterns, and informing resource limits.
Metrics also help measure the success of the deployment, enabling continuous monitoring of the performance of an application. Tracking metrics should ideally be part of an automated workflow:
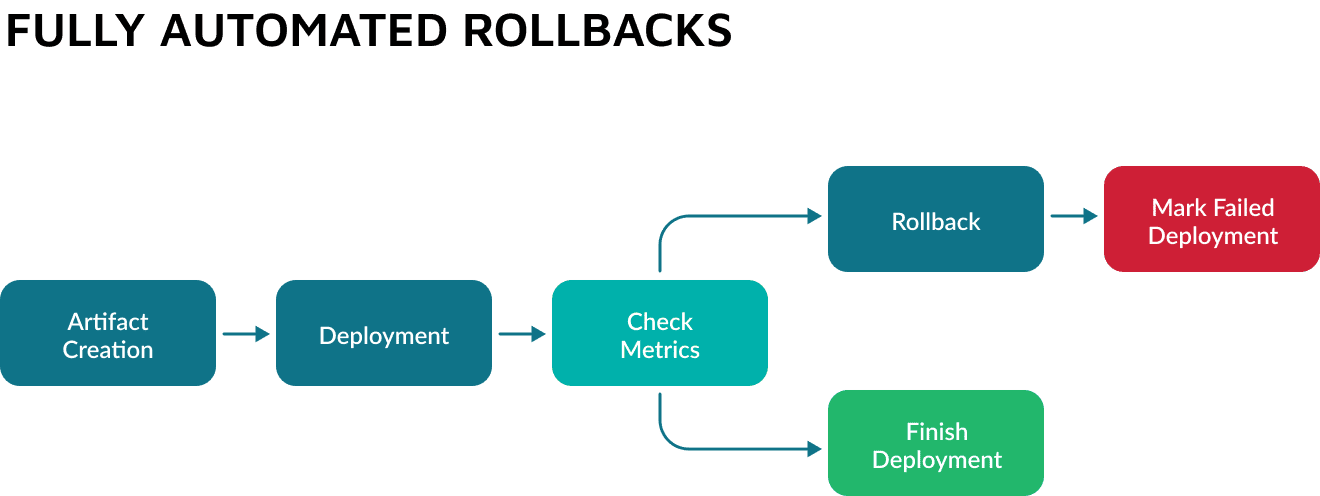
With an automated rollback, the system examines metrics after the deployment, marking it as completed or rolling it back. Establishing metrics that Affect deployments can be challenging but essential.
Implement a Secrets Strategy
When using dynamic services to handle configuration changes, they (or similar services) should also handle the related secrets. They pass secrets to containers during runtime. It is important to use a unified strategy to handle secrets, ensuring that different types of secrets (i.e., runtime vs build secrets) are not confused and maintaining smooth testing and development.
Applications only require build secrets during packaging (i.e., artifact repository or file storage credentials). Runtime secrets are only necessary after deployment (i.e., private keys, database passwords, and SSL certificates). Developers should only pass necessary secrets to an application.
The specific strategy is less important than sticking to a single strategy. Every team must use the same secret handling strategy across all environments, making it easier to track secrets. It should be flexible to enable easy testing and deployment. The focus should be on the secrets’ usage, not their source.
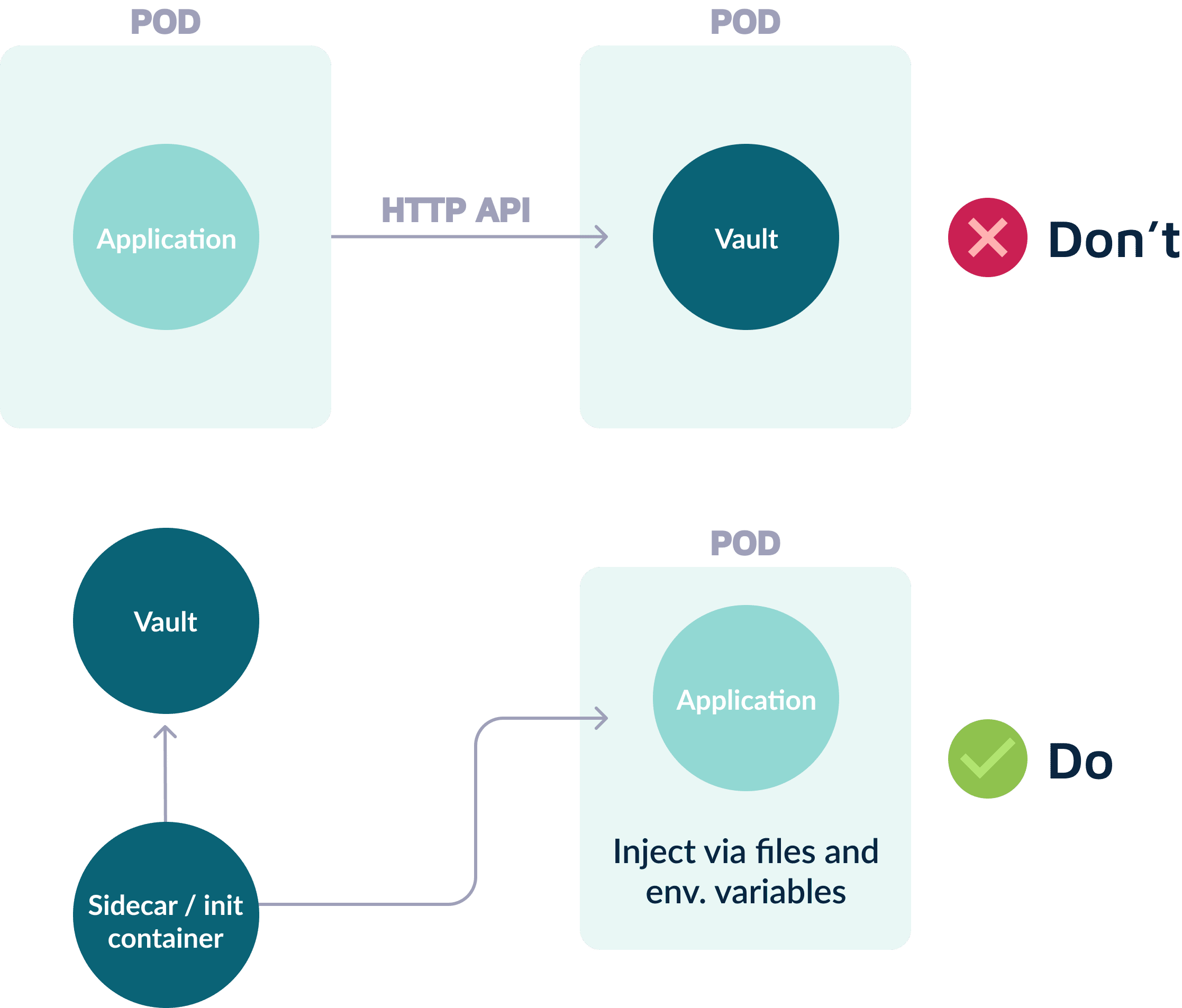
Automate Database Updates
Database management is as important as handling an application. It is best to automate databases to application code—this involves creating automatic update pipelines for new changesets. A dynamic temporary environment allows teams to review changesets and code safely.
The database automation strategy should include a rollback mechanism in case of a failed upgrade. Automatically transforming production data into test data is useful because keeping copies of production data in a test environment is less secure and inefficient. Having a small, anonymized subset of data enables more efficient handling.
What Is Progressive Delivery?
Progressive delivery is a software development paradigm that provides better control over the delivery of software updates. It involves creating a continuous integration and continuous delivery (CI/CD) pipeline with several flexible techniques for rolling out new versions of a software product.
Here are core concepts of progressive delivery:
- CI/CD pipelines—automate building, testing, and deployment tasks. It introduces efficiency into the software development life cycle (SDLC) by delegating repetitive tasks to programs.
- Feature flag management—enables turning features on and off during production. It helps teams gain granular control over feature development, making it possible to make changes to features in production and release updates quickly.
- Progressive deployment—introduces techniques like canary, blue-green, A/B testing, and roll-out deployments. We cover these in more detail below.
Progressive Delivery Made Easy with Codefresh
Codefresh is a GitOps software delivery platform based on the open source Argo project. Those familiar with Argo CD can instantly gain value from Codefresh’s robust features, while those new to continuous delivery will find the setup straightforward and easy. The new unified UI brings the full value of Argo CD and Argo Rollouts into a single view.
Codefresh takes an opinionated but flexible approach to software delivery. To deploy an application, simply define the git source of manifests and set a deployment target. Doing this from the UI will commit the configuration to git. Once in git, Codefresh will automatically detect the application and deploy it.
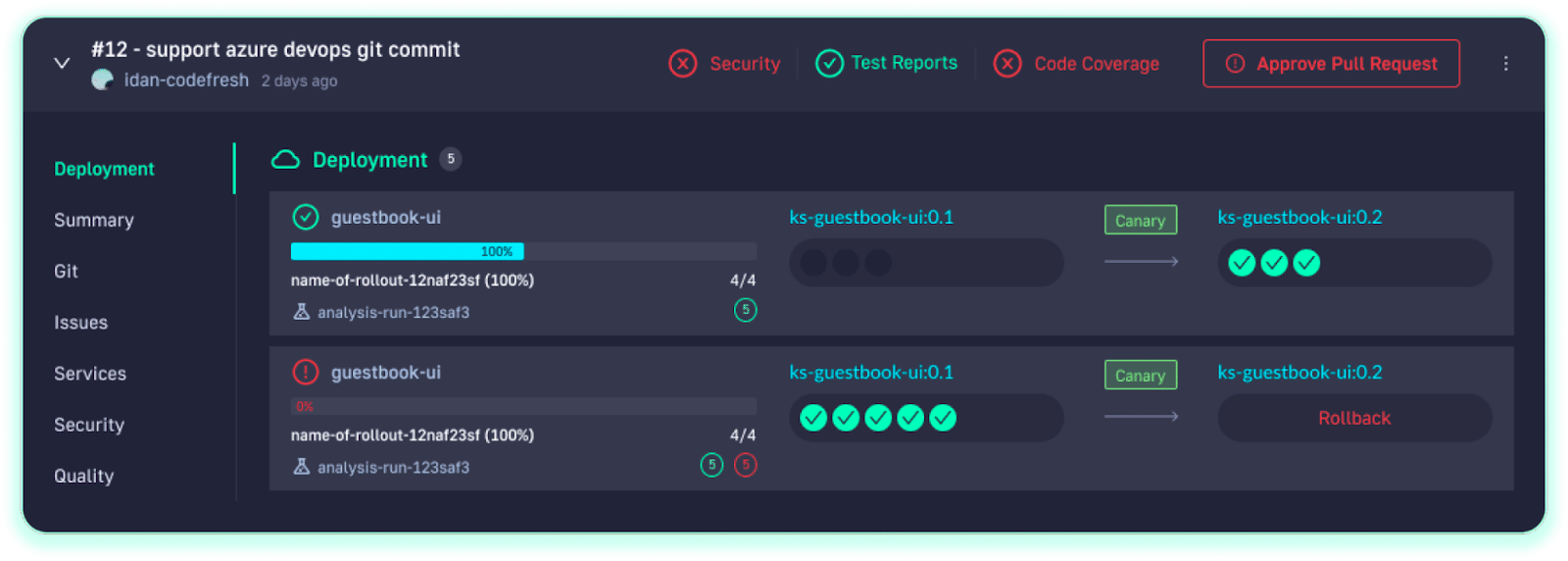
Progressive delivery has long been out of reach for release teams because of complex requirements. In the Codefresh platform, progressive delivery strategies like canary or blue/green deployment can be simply defined in a declarative manner. These progressive delivery strategies can greatly reduce the risk of rolling out new changes by automatically detecting issues easily and rolling back to previous stable versions.
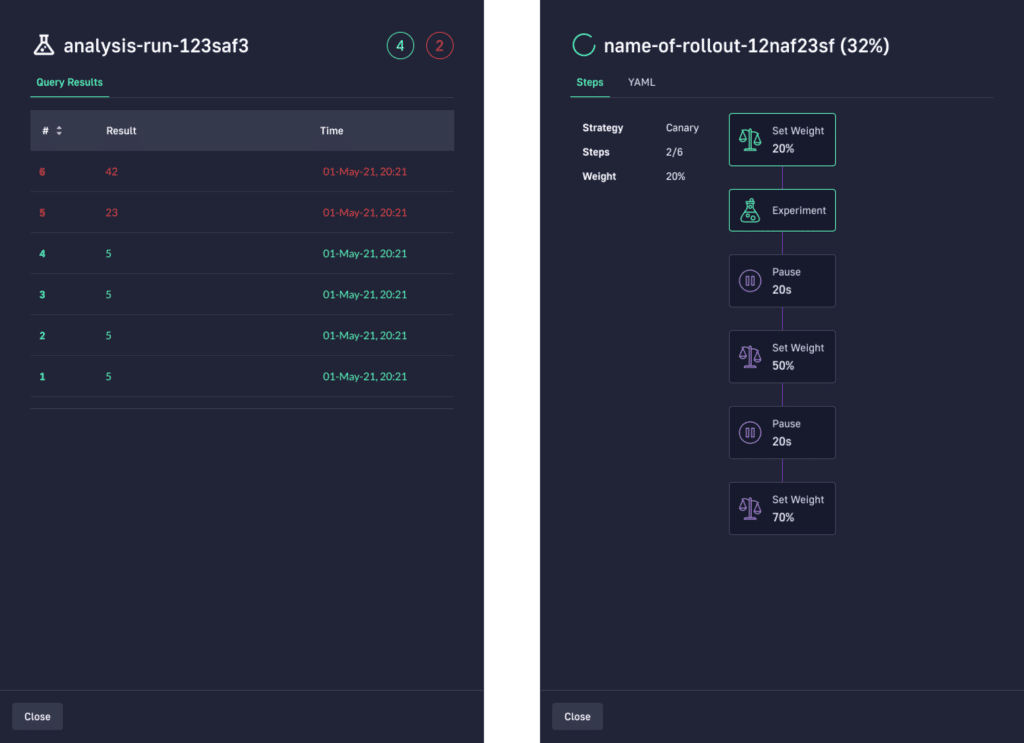
Below you can see how a canary deployment is managed automatically in Codefresh.
See Additional Guides on Key CI/CD Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of CI/CD.
Authored by Kolena
Authored by Codefresh

The World’s Most Modern CI/CD Platform
A next generation CI/CD platform designed for cloud-native applications, offering dynamic builds, progressive delivery, and much more.
Check It Out