Article Content
What Are Microservices?
A microservices architecture treats applications as a set of loosely coupled services. In a microservices architecture, services are highly granular, serving only a specific purpose, and lightweight protocols enable communication between them.
The goal of microservices is to enable small teams to work on services independently of other teams. This reduces the complexity of each service, makes changes easier, and avoids complex dependencies between components within an application. There is less need for different teams to communicate and coordinate, dramatically eases deployment, and improves reliability, because changes in one component can no longer break another.
Microservices allow organizations to quickly scale software projects and easily make use of off-the-shelf or open source components. However, a microservices architecture can be challenging to build and operate. Interfaces between services must be carefully designed and treated as public APIs. And new technologies are needed to orchestrate fleets of independent microservices, typically deployed as containers or serverless functions.
This is part of an extensive series of guides about Observability.
Building Microservices with Kubernetes
Kubernetes, often abbreviated as K8s, is a popular open source platform for managing and orchestrating containerized applications. It was initially developed by Google and is now maintained by the Cloud Native Computing Foundation. It provides a framework to run distributed systems resiliently. It takes care of scaling and failover for our application, provides deployment patterns, and more.
Kubernetes is a platform that eliminates the manual processes involved in deploying and scaling containerized applications. You can cluster together groups of hosts running Linux containers, called nodes, into a cluster. Kubernetes helps you easily and efficiently manage those clusters, which can span public, private, or hybrid clouds. For this reason, Kubernetes is an ideal platform for hosting cloud-native applications that require rapid scaling.
The beauty of Kubernetes is that it is modular and portable, running on various types of infrastructure including on-premise hardware, OpenStack clusters, public clouds like Google Cloud or AWS, and more. The modular architecture of Kubernetes makes it easy to swap out or add components to fit specific needs. It also supports a wide range of container tools, including Docker and rkt.related
Learn more in the detailed guides:
Related technology updates:
- [Report] GigaOm 2024 FinOps Radar for Kubernetes Management
- [Blog] Pros and Cons of Spark on Kubernetes
Containers and Container Runtimes
Microservices deployed in Kubernetes run inside containers. A container encapsulates everything required to run an application, including code, libraries, and dependencies. Containers are popular for microservices because they are portable, secure, and start faster than VMs.
Container runtimes are software components that run containers on a host operating system and manage their lifecycle. They work with the operating system kernel to launch and support containerization, and can be controlled and automated by Kubernetes.
Learn more in the detailed guides to:
Related product offering: Spot Ocean | Kubernetes Infrastructure Management
Related technology updates:
Stateless vs. Stateful Services
When developing microservices for Kubernetes, one of the first decisions you need to make is whether your services will be stateless or stateful. Stateless services are those that do not save client data generated in one session for use in the next session with that client. Each session is carried out as if it was the first time, and responses are not determined by the data from a previous session. On the other hand, stateful services are those that save data about each client session and use that data in the next session with that client.
Stateless services are typically simpler to develop and manage. They can be scaled horizontally by simply adding more instances, and they don’t require any special handling to preserve state information when they are restarted or fail. Stateful services are necessary for applications that require data persistence, such as databases, caching systems, or any application that needs to remember information from previous sessions. Kubernetes provides a mechanism called Persistent Volumes to dynamically manage persistent data for stateful services.
Learn more in the detailed guides to:
Managed Kubernetes Providers
It is possible to run and administrate your own Kubernetes cluster, but it can be a lot of work and requires a strong understanding of Kubernetes. An easier way is to use a managed Kubernetes provider, which runs the Kubernetes cluster on your behalf, and can make the learning curve smoother.
Amazon Elastic Kubernetes Service (EKS)
Amazon Elastic Kubernetes Service (EKS) is a managed service that makes it easy to deploy, manage, and scale containerized applications using Kubernetes. EKS runs the Kubernetes management infrastructure across multiple AWS Availability Zones, eliminating a single point of failure. This makes it a reliable choice for deploying your microservices.
Learn more in the detailed guide to Kubernetes on AWS
Related product offering: Komodor | Kubernetes Management and Troubleshooting
Azure Kubernetes Service (AKS)
The Azure Kubernetes Service (AKS) offers serverless Kubernetes, an integrated continuous integration and continuous delivery (CI/CD) experience, and enterprise-grade security and governance. It’s a powerful choice for any organization looking to deploy microservices on a robust, secure platform.
Learn more in the detailed guide to Kubernetes in Azure
Google Kubernetes Engine (GKE)
Finally, the Google Kubernetes Engine (GKE) provides a managed environment for deploying, managing, and scaling your containerized applications. GKE is built on Google’s experience of running services like Gmail and YouTube, and it offers a combination of performance, flexibility, and security.

Senior Developer Evangelist, Octopus Deploy
Kostis is a software engineer/technical-writer dual-class character. He lives and breathes automation, good testing practices, and stress-free deployments with GitOps.
TIPS FROM THE EXPERT
In my experience, here are tips that can help you better adapt to building microservices with Kubernetes:
- Design for resilience: Incorporate patterns such as bulkheads, retries, and timeouts to ensure that your microservices can handle failures gracefully. This will make your system more robust and reduce downtime.
- Embrace immutability: Ensure that your containers are immutable by using fixed, versioned images. This practice avoids the “works on my machine” problem and enhances the predictability of deployments.
- Service-to-service authentication: Use mutual TLS (mTLS) with a service mesh like Istio or Linkerd to secure communication between services. This ensures that only authorized services can communicate with each other.
- Blue-green and canary deployments: Implement these deployment strategies to minimize the impact of new releases. Blue-green deployments allow you to switch traffic between two environments, while canary deployments gradually introduce changes to a small subset of users.
- Automate everything: Automate deployments, scaling, and management tasks with Kubernetes operators. This will reduce manual intervention and errors, ensuring more consistent and reliable operations.
Deploying Microservices on Kubernetes
Configuring Deployment YAML files
Deployment is a crucial aspect of building microservices with Kubernetes. It involves defining your application in a YAML or JSON format for Kubernetes to understand the components of your application and how to run it. The Deployment instruction in Kubernetes is a declarative way of updating both the application and its configurations.
A Deployment YAML file in Kubernetes describes the desired state of a particular component of an application and Kubernetes will do the necessary actions to maintain the stated desired state. This file contains information such as the number of replicas, the container image to use, the ports to expose, and more. Kubernetes uses these YAML files to create, update, and scale applications.
Service Discovery in Kubernetes
Service discovery is a key aspect of any microservices architecture. In a microservices architecture, services need to be able to find each other in order to communicate. Kubernetes provides two primary modes of service discovery, Environment Variables and DNS.
Kubernetes automatically provides environment variables for services running in the same namespace. When a Pod runs in Kubernetes, it is automatically provided with environment variables for each active service. However, this method has some drawbacks, such as the inability to support dynamic configuration changes.
DNS, on the other hand, is a much more flexible and commonly used method of service discovery. Kubernetes provides a built-in DNS service for automatic discovery of services by their names. This method allows us to use standard protocols to communicate between services, and it can easily handle changes in configuration or service scaling.
Managing Configurations and Secrets
Kubernetes provides robust mechanisms for managing configurations and secrets, which are sensitive pieces of data like passwords and API keys, for your applications. ConfigMaps and Secrets are two Kubernetes objects that allow you to store and manage sensitive information.
ConfigMaps is a Kubernetes object used to store non-confidential data in key-value pairs. It allows you to decouple environment-specific configuration from your application’s code, making your application easier to build and deploy.
Secrets are used to store sensitive data. Kubernetes Secrets are secure objects which contain small amounts of sensitive data such as passwords, OAuth tokens, ssh keys etc. Storing sensitive information in Secrets is more secure and flexible than putting it directly in a Pod definition or in a Docker image.
Other Microservices Technologies and Tools
Microservices architectures can incorporate various languages and tools, but there is a core handful of tools required to enable microservices.
APIs Gateways and Service Mesh
Microservices typically use APIs to communicate, with an API gateway as the intermediary layer between the client and a service. The gateway can route requests and increase security, which is especially useful when there are a growing number of services.
Service mesh is another crucial aspect of microservices architectures. It is a dedicated infrastructure layer for handling service-to-service communication. Service mesh provides features like load balancing, service discovery, traffic management, telemetry, and security for microservices interactions. It offers fine-grained control over traffic, ensuring that data routes efficiently and securely between services. Popular service meshes include Istio, Linkerd, and Consul Connect.
Learn more in the detailed guide to Istio
Service Discovery Technology
Microservices must be able to find each other to operate. Service discovery tools help identify the location and state of microservices in real time, making it easier for developers to write code and avoid issues arising from the rapidly changing architecture. A dynamic database acts as a microservices registry specifying the location of instances, allowing developers to discover services.
Event Streams and Alerts
Services must be state-aware, and API calls are not effective for keeping track of state information. API calls that establish state must be coupled with alerts or event streams to transmit state data to the relevant parties automatically. Some organizations use a general-purpose alerting system or message broker, while others build event-driven systems.
Serverless
Another technology that’s closely tied to microservices is serverless computing. Serverless does not mean there’s no server. Instead, it’s a cloud computing execution model where the cloud provider manages the server, and dynamic allocation of resources. You’re only charged for the actual usage, not pre-purchased capacity.
Serverless architecture is a natural fit for microservices because it allows developers to focus on individual services without worrying about infrastructural considerations. It also scales automatically to meet the demands of the service, which aligns with the autonomous nature of microservices.
Learn more in the detailed guides to:
Edge Computing
Edge computing is a distributed computing paradigm that brings computation and data storage closer to the sources of data. This is in contrast to traditional cloud computing, where data processing happens in large, centralized data centers.
In a microservices architecture, edge computing can help to reduce latency, as data doesn’t have to travel to a central server for processing. This is particularly useful in real-time applications, where low latency is crucial. It also allows for more efficient use of resources, as data can be processed at the edge of the network, only sending relevant data to the central server.
Learn more in the detailed guide to edge computing
Microservices Example: The Circuit Breaker Pattern
Let’s look at a common software development challenge and how a simple microservice can solve it.
The challenge is delays or failures in remote calls. When a software system makes remote calls to other software components, running in different processes or on different machines, those calls can fail or hang until a timeout limit is reached. Having a large number of callers on an unresponsive provider can exhaust resources and result in cascading failures.
The circuit breaker pattern, commonly used in a microservices architecture, can solve this problem.

Source: Wikimedia Commons
The basic idea of a circuit breaker is to wrap the remote function call with a “circuit breaker” object that monitors for errors. When the error reaches a certain threshold, the circuit breaker is activated, and when it receives any subsequent calls to the same provider, it returns an error or redirects to an alternate service. This ensures that the system immediately responds and no threads need to wait for unanswered calls.
Another advantage of circuit breakers is that they can help with monitoring. Any change in circuit breaker status is logged with detailed status information. Tripping the circuit breaker is a clear sign of more serious environmental problems. Operators must also be able to trip or reset circuit breakers manually as part of debugging or troubleshooting operations.
Circuit breakers have three possible states:
- Closed—if the remote provider is up and running, the circuit breaker remains closed and calls go directly to the required service.
- Open—this state is triggered when the number of faults exceeds a specified threshold. The circuit breaker then opens, and from this point onwards, does not execute the function, returning an error to the caller instead.
- Half-Open—after a timeout period, the circuit enters the Half-Open state to test if the underlying problem still exists. If the call fails in this half-open state, the circuit breaker resumes the Open state. If successful, the circuit breaker is reset to its normal Closed state.
Microservices Monitoring and Security
Monitoring and securing microservices can be a challenge, mainly due to their distributed nature. However, with the right approach and tools, it is possible to keep an eye on your microservices and ensure their security.
Monitoring microservices involves keeping track of the health and performance of each service, as well as the communication between them. This requires a comprehensive monitoring solution that can collect and correlate data from different sources to provide a holistic view of your microservices architecture. The collected data can include metrics, logs, and traces, which provide information about the performance, errors, and dependencies of your services.
Securing microservices involves protecting each service from potential threats and vulnerabilities. This can be achieved by implementing security measures at different levels, including the network, the host, the application, and the data. Some of the common security practices for microservices include using authentication and authorization, encrypting communication, managing secrets, and regularly scanning for vulnerabilities.
Learn more in the detailed guide to microservices security
Related product offering: Tigera | Security and Observability for Containers and Kubernetes
Related technology update: [Blog] How Network Security Policies can Protect Your Environment
Microservices Testing and Logging
Microservices testing is becoming an integral part of the continuous integration/continuous delivery (CI/CD) pipeline managed by modern DevOps teams.
Testing microservices applications requires a strategy that considers both service dependencies and the isolated nature of microservices. The microservices testing process usually isolates each microservice to make sure it works, and then tests the microservices together.
Microservices test types
There are four types of tests commonly used in microservices applications:
- Unit tests—these types of tests help validate that specific software components are working as intended. A unit can be an object, module, function, etc. Unit tests can be used to identify if each microservice is coded properly and its basic functionality returns the expected outputs.
- Contract tests—in a microservices architecture, a “contract” is the expected outputs promised by each microservice for each input. A contract is implemented as an API and enables microservices to communicate. Contract testing verifies that each service call conforms to the contract, and that the microservice returns the expected outputs, even after its internal implementation has changed.
- Integration testing—integration tests check how microservices work together as subsystems and collaborate as part of the entire application. Testing usually involves the execution of communication paths to test assumptions about inter-service communication and identify faults.
- End-to-end testing—a microservices-based application can have multiple services running and communicating between them. When an error occurs, it can be complex to identify which microservice failed and why. End-to-end testing lets you run a realistic user request and capture the entire request flow to identify which services are called, how many times, and in what order, and where failure conditions occurred.
The importance of microservices logging
In a traditional monolith, you could simply find all the logs in the server filesystem. But with microservices, each instance of each service has its own logs, which can get deleted when an instance shuts down. This requires a centralized system that collects and analyzes logs. Microservices testing requires robust logging on all microservices, with unique IDs for each microservice instance that can be used to correlate requests.
8 Microservices Best Practices
Here are best practices that can help you make your microservices application a success.
1. Implement Failure-Tolerant Design
High availability is essential for cloud and container-based workloads. Containerized applications should not have to manage infrastructure or environmental layers. New containers should be available for automatic re-instantiation when another container fails.
It is important to design microservices for failure and test the services to see how they cope under various conditions. This design approach enables the infrastructure to repair itself, minimizing emergency calls and preventing attrition. The failure-tolerant design also helps ensure uptime and prevent outages.
2. Apply Versioning to API Changes
Organizations often have to add or update functionalities as their applications mature. Development shops usually require a versioning mechanism to ensure consistent updates. Versioning methods are particularly important for microservices because development teams update services individually. It is also harder to version microservices applications than conventional applications.
Developers must not use API or service name version data when versioning a microservices app. It is essential to keep proper documentation and ensure they update it with each version. It should be easy to configure every service’s URL and version number—this is important to avoid hard-coding them into the backend.
3. Implement Continuous Delivery
Continuous delivery enables fast, frequent deployments, a key benefit of microservices. This approach automatically tests and pushes each build through the pipeline to production. The pipeline’s steps depend on the amount and type of testing required before releasing changes to production. Several steps may cover staging and integration, component, and load tests. Release policies determine which steps to implement and when.
4. Consider Asynchronous Communication
Choosing the communication mechanism is a major microservices design challenge. Most microservice architectures use synchronous communication based on REST APIs. While this approach is the simplest to implement, it also allows latencies to build up and can result in cascading failures. Asynchronous communication works better for some scenarios, but is also more difficult to debug. You can implement it in various ways, including via message queues (Kafka), CQRS, or asynchronous REST.
5. Use a Domain-Driven Design Approach
The domain-driven design approach might work well for some teams, but may be overkill for smaller organizations. It applies object-oriented programming to business models, with rules to design the model around business domains. Large platforms like Netflix use this principle to deliver and track content using multiple servers.
6. Use Technology Agnostic Communication Protocols
Microservices typically cover specific business domains, with dedicated teams for each domain. Different teams may use different technologies, meaning that the communication protocols should be technology-agnostic. Common protocols used to enable requests to various microservices serving a single client include REST, GraphQL, and gRPC.
REST is suitable for static, but not dynamic, APIs. GraphQL is extremely customizable and supports graph-based APIs to give users a high degree of flexibility and control over data. However, GraphQL is also more difficult to implement than REST.
gRPC is a Google-developed, open source communication framework that handles most aspects of communication between services, enabling the integration of non-client-facing services. It is suitable for collaborative projects due to its language neutrality.
It is possible to combine protocols—for example, using REST for edge services and gRPC for internal services.
7. Leverage Application Mapping for Microservices
When transitioning to a microservices architecture, it’s crucial to have a clear understanding of your application’s structure. Application mapping is the process of identifying the different components of your application and their interactions. By creating a map of your application, you can gain insights into how your application works, which can help you design your microservices more effectively.
Application mapping for microservices involves identifying the different functionalities of your application, the data they use, and the dependencies between them. This can be done through code analysis, documentation review, and discussions with your team members. Once the map is created, it can be used as a guide for designing and implementing your microservices.
8. Use Distributed Tracing
As your microservices architecture grows and becomes more complex, it can become challenging to understand and debug the interactions between different services. This is where distributed tracing comes in.
Distributed tracing is a method used to profile and monitor applications, especially those built using a microservices architecture. It helps developers trace the request path through a web application. By integrating distributed tracing with your microservices, you can gain visibility into the performance and behavior of your services, which can help you identify issues and bottlenecks more quickly.
Microservices Delivery with Codefresh
Codefresh helps you answer important questions within your organization, whether you’re a developer or a product manager:
- What features are deployed right now in any of your environments?
- What features are waiting in Staging?
- What features were deployed on a certain day or during a certain period?
- Where is a specific feature or version in our environment chain?
With Codefresh, you can answer all of these questions by viewing one dashboard, our Applications Dashboard that can help you visualize an entire microservices application in one glance:
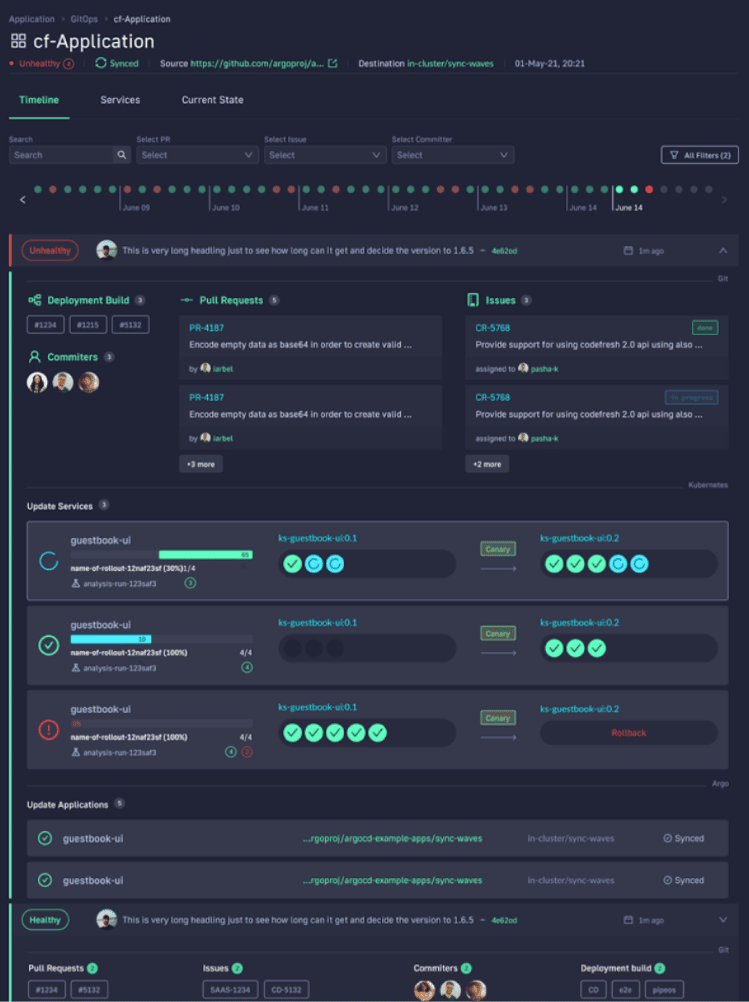
The dashboard lets you view the following information in one place:
- Services affected by each deployment
- The current state of Kubernetes components
- Deployment history and log of who deployed what and when and the pull request or Jira ticket associated with each deployment
See Additional Guides on Microservices Topics
Authored by Codefresh
Authored by Komodor
Authored by Lumigo
Authored by Lumigo
Authored by Lumigo
Authored by Lumigo
Authored by NetApp
Authored by NetApp
Authored by NetApp
Authored by NetApp
Authored by NetApp
Authored by NetApp
Authored by Spot
Related guides
- AWS ECS Pricing: 3 Pricing Models and 5 Cost Saving Tips
- Run an ECS Cluster on Spot Instance in 3 Steps
Related product offering: Kubernetes Infrastructure Management
Offered by Spot
Related technology updates:
Authored by Spot
Authored by Tigera
Authored by Tigera
Related guides
- Top 10 Microservices Security Patterns
- Solving Microservices Connectivity Issues with Network Logs
- Microservices in Kubernetes: A Practical Guide
Related product offering: Security and Observability for Containers and Kubernetes
Related technology update: [Blog] How Network Security Policies can Protect Your Environment
Below are additional articles that can help you learn about Microservices topics.

The World’s Most Modern CI/CD Platform
A next generation CI/CD platform designed for cloud-native applications, offering dynamic builds, progressive delivery, and much more.
Check It Out