Starting Point
Over the last years, we’ve been adopting several concepts for our project, struggling to make them work together. Let’s look at some of the concepts:
Microservice Architecture
The first one is the Microservice Architecture. We did not start it clean and by the book, rather applied it to an already existing project by splitting big services into smaller ones and breaking excessive coupling. The refactoring work is not yet finished. We are starting to build new services which look like “microservices”, however, I would call them”micro-monoliths”.
I have a feeling that this is a typical situation for an already existing project, that tries to adapt into this new architecture pattern, which sounds more like: You are almost there, but there is always a work to be done.
Docker
The second concept is using Docker for building, packaging, and deploying application services. We bet on Docker from the beginning and used it for most of our services which happen to be a good bet.
There are still few pure cloud services, that we are using when running our application on public cloud, thing like Databases, Error Analytics, Push Notifications and some others.
Kubernetes
And one of the latest bet we made was Kubernetes.
Kubernetes became the main runtime platform for our application. Adopting Kubernetes, not only allowed us to hide away lots of operational complexity, achieving better availability and scalability, but also enabling us to run our application on any public cloud and on-premise deployment.
With great flexibility, Kubernetes, however, brings an additional deployment complexity.
Suddenly your services are not just plain Docker containers, but there are a lot of new (and useful) Kubernetes resources that you need to take care for such as: ConfigMsaps, Secrets, Services, Deployments, StatefulSets, PVs, PVCs, Ingress, Jobs, and others. And it’s not always obvious where to keep all these resources and how they are related to Docker images built by CI tool.
Continuous Delivery vs Continuous Deployment
The ambiguity of CD term annoys me a lot. Different people mean different things when using this term. And it’s not only about the CD abbreviation meaning: Continuous Deployment vs Continuous Delivery, but also what do people mean, when using this abbreviation.
Still, it looks like there is a common agreement that Continuous Deployment (CD) is a super-set of Continuous Delivery (CD). And the main difference, so far, is that Continuous Deployment is 100% automated, while in Continuous Delivery there are still some steps that should be done manually.
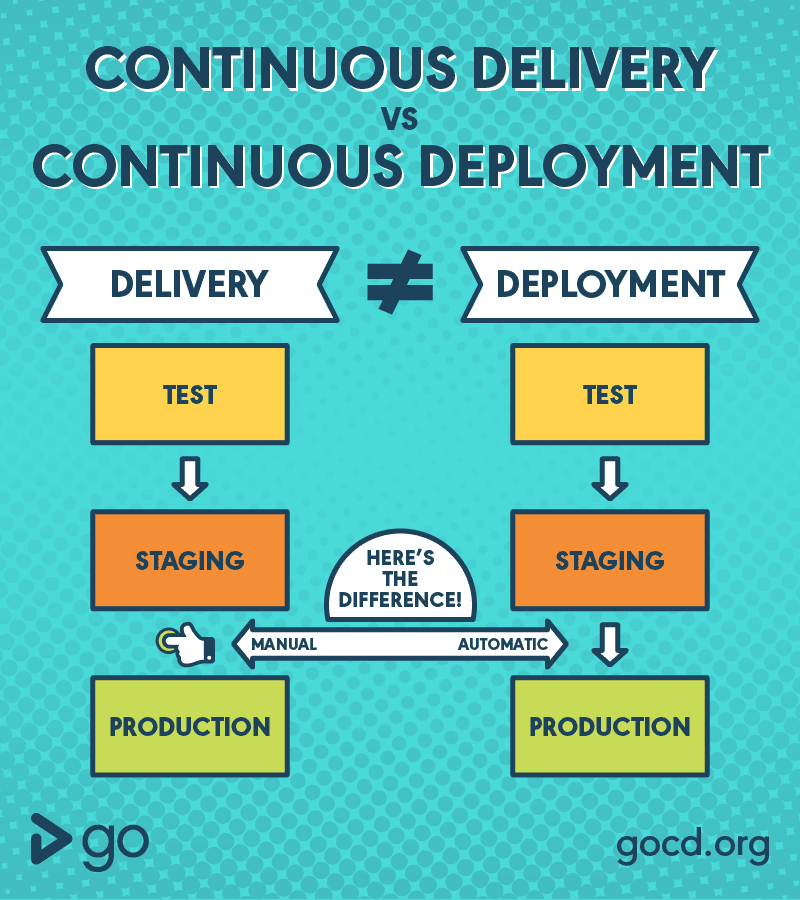
In our project, for example, we succeeded to achieve Continuous Delivery, that serves us well, both for SaaS and on-premise versions of our product. Our next goal is to achieve the following things:
- Create fluent *Continuous Deployment* for SaaS version
- Release a change automatically to production, without human intervention, and be able to rollback to the previous version if something went wrong
Kubernetes Application and Release Content
Now let’s talk about Release and try to understand the definition Release Content.
When we are releasing a change to some runtime environment such as development, staging or production, it’s not always a code change, that is packaged into a new Docker image with some tag.
Change can be done to application configurations, secrets, ingress rules, jobs we are running, volumes and other resources. It would be nice to be able to release all these changes in the same way as we release a code change. Actually, a change can be a mixture of both and in practice, it’s not a rare use case.
So, we need to find a good methodology and supporting technology, that will allow us to release a new version of our Kubernetes application, that might be composed of multiple changes and these changes are not only new Docker image tags. This methodology should allow us to do it repeatedly on any runtime environment (Kubernetes cluster in our case) and be able to rollback ALL changes to the previous version if something went wrong.
That’s why we adopted Helm as our main release management tool for Kubernetes.
Helm recap
This post is not about Helm, so Helm recap will be very short. I encourage you to read Helm documentation, it’s complete and well written.
Helm is a flexible release management system and can be extended with plugins and hooks.
The core Helm concepts are as follows:
- (Helm) Chart – is a package (
tararchive) with KubernetesYAMLtemplates (for different Kubernetes resources) and default values (also stored inYAMLfiles). Helm uses chart to install a new or update an existing (Helm) release. - (Helm) Release – is a Kubernetes application instance, installed with Helm. It is possible to create multiple releases from the same chart version.
- (Release) Revision – when updating an existing release, a new revision is created. Helm can rollback a release to the previous revision. Helm stores all revisions in ConfigMap and it’s possible to list previous releases with
helm historycommand. - Chart Repository – is a location where packaged charts can be stored and shared. Any web server that can store and serve static files can be used as Chart Repository (Nginx, GitHub, AWS S3 and others).
Helm consists of the server, called Tiller and the command line client, called helm.
- When releasing a new version (or updating an existing) `helm` client sends *chart* (template files and values) to the Helm server.
- *Tiller* server generates valid Kubernetes `yaml` files from templates and values and deploys them to Kubernetes, using Kubernetes API.
- *Tiller* also saves generated `yaml` files as a new revision inside `ConfigMaps` and can use previously saved revision for rollback operation.
Helm Chart Management
Typical Helm chart contains a list of template files (yaml files with go templates commands) and values files (with configurations and secrets).
We use Git to store all our Helm chart files and Amazon S3 for chart repository.
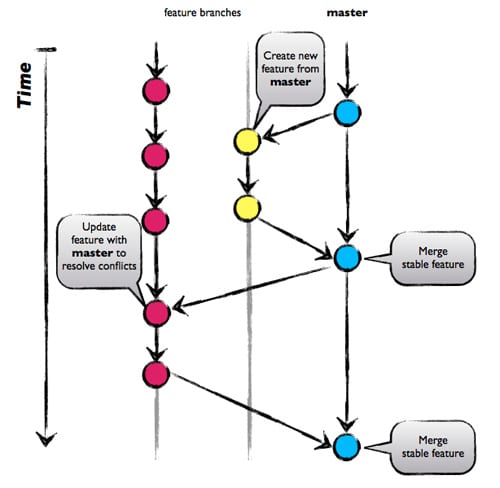
Our guide to Helm Chart Management with git:
- Adopt some Git management methodology. We use something very close to the GitHub Flow model

- Have a
gitrepository for each microservice. Our typical project structure is shown bellow:
# chart files
chart/
# chart templates
templates/
# external dependency
requirements.yaml
# default values
values.yaml
# chart definition
Chart.yaml
# source code
scr/
# test code
test/
# build scripts
hack/
# multi-stage Docker build file
Dockerfile
# Codefresh CI/CD pipeline
codefresh.yaml
- We keep our application chart in a separate
gitrepository. The application chart does not contain templates, but only a list of third-party charts it requires (requirements.yamlfile) and values files for different runtime environments (testing,stagingandproduction) - All secrets in values files are encrypted with sops tool and we defined a
.gitignorefile and setup agit pre-commit hookto avoid unintentional commit of decrypted secrets.
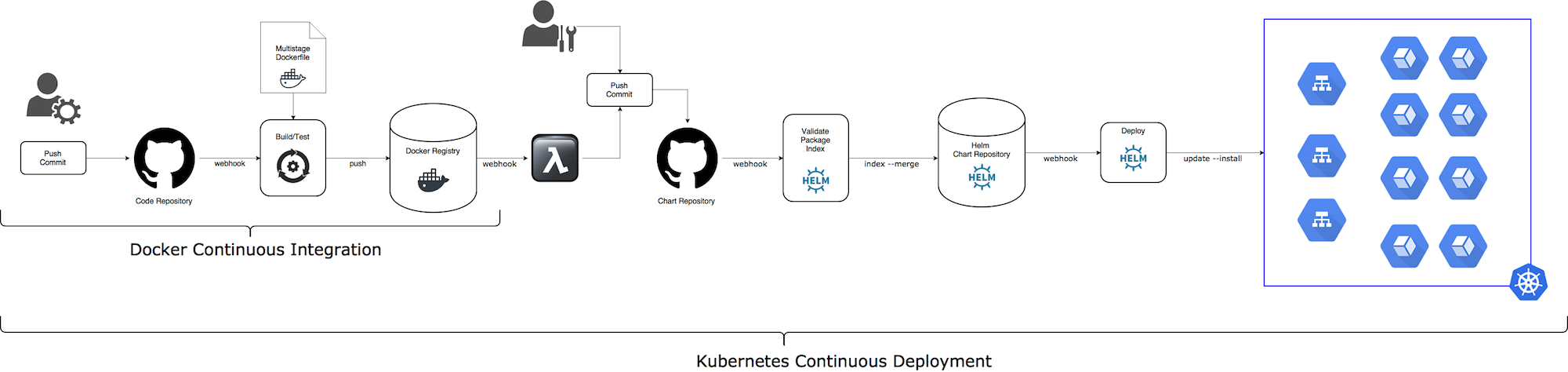
Docker CI (Continuous Integration)
Building and testing code on git push/tag event and packaging it into some build artifact is a common knowledge and there are multiple tools, services, and tutorials how to do it.
And if you choose our Codefresh service, you will get a built-in support for highly effective Docker CI. Codefresh also manages traceability links between Docker images, git commits, CI builds, Docker Registries, Kubernetes Services and Deployments and Helm Releases running on Kubernetes clusters.
Typical Docker CI flow
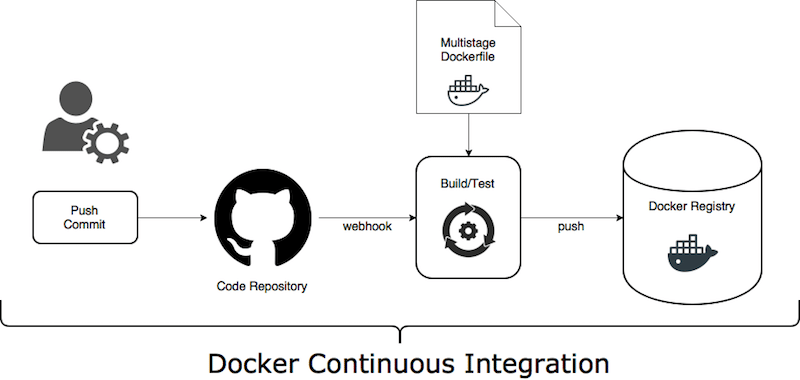
- Trigger CI pipeline on
pushevent - Build and test service code. Tip: give a try to a Docker multi-stage build.
- Tip: Embed the
git commitdetails into the Docker image (using Docker labels). I suggest following Label Schema convention. - Tag Docker image with
{branch}-{short SHA} - Push newly created Docker image into preferred Docker Registry
Docker Multi-stage build
With a Docker multi-stage build, you can even remove a need to learn a custom CI DSL syntax, like Jenkins Job/Pipeline, or other YAML based DSL. Just use a familiar Dockerfile imperative syntax to describe all required CI stages (build, lint, test, package) and create a thin and secure final Docker image, that contains only bare minimum, required to run the service.
Using multi-stage Docker build, also has other benefits:
- It allows you to use the same CI flow both on the developer machine and the CI server
- It can help you to switch easily between different CI services, using the same `Dockerfile`
The only thing you need is a right Docker daemon version (‘> 17.05’). So, select CI service that supports latest Docker daemon versions.
Example: Node.js multi-stage Dockerfile
#
# ---- Base Node ----
FROM alpine:3.5 AS base
# install node
RUN apk add --no-cache nodejs-npm tini
# set working directory
WORKDIR /root/chat
# Set tini as entrypoint
ENTRYPOINT ["/sbin/tini", "--"]
# copy project file
COPY package.json .
#
# ---- Dependencies ----
FROM base AS dependencies
# install node packages
RUN npm set progress=false && npm config set depth 0
RUN npm install --only=production
# copy production node_modules aside
RUN cp -R node_modules prod_node_modules
# install ALL node_modules, including 'devDependencies'
RUN npm install
#
# ---- Test ----
# run linters, setup and tests
FROM dependencies AS test
COPY . .
RUN npm run lint && npm run setup && npm run test
#
# ---- Release ----
FROM base AS release
# copy production node_modules
COPY --from=dependencies /root/chat/prod_node_modules ./node_modules
# copy app sources
COPY . .
# expose port and define CMD
EXPOSE 5000
CMD npm run start
Summary
This was the first post in series. In the next part, I will cover out POV for Kubernetes Continuous Deployment and Continuous Delivery.
We constantly change Codefresh to be the product that helps us and our customers to build and maintain effective Kubernetes CD pipelines. Give it a try and let us know how can we improve it.
Hope, you find this post useful. I look forward to your comments and any questions you have.
New to Codefresh? Create Your Free Account Today!