
In the previous article of the series we explained how to model GitOps environments and promote an application between them. That article was laser-focused on a single application and its Kubernetes resources. In this article we will zoom out to look at several related subjects:
- Where to put the Argo CD application manifests
- How to work with multiple teams/clusters/applications
- How to employ Application Sets for easier management
- How to split your GitOps repositories instead of using a monorepo
It is worth mentioning that as always, our advice is a general recommendation that follows best practices. You can use it as a starting point for your own organization, but if you believe that a different approach works better for your case, then please adapt the patterns we mention for your own environment. You can find our example repository at https://github.com/kostis-codefresh/many-appsets-demo
Note also that the previous article was pretty generic (and could even work for Flux users), while here we will focus specifically on Argo CD and its advanced features.
The different types of manifests
How to organize Argo CD applications is a very popular subject with many resources and blogs discussing the topic and constant questions and discussion from users. Unfortunately, most of the existing resources mix the different types of manifests and never mention Application Sets and their capabilities. The term “manifest” is also overloaded in the case of Argo CD and GitOps. So let’s define the different types of manifests first
| Category | Description | Type | Change Frequency | Target Users |
|---|---|---|---|---|
| 1 | Developer Kubernetes manifests | Helm, Kustomize or plain manifests in Git | Very often | Developers mostly |
| 2 | Developer Argo CD manifests | Argo CD app and Application Set | Almost never | Operators/Developers |
| 3 | Infrastructure Kubernetes manifests | Usually external Helm charts (in Git or Helm repo) | Sometimes | Operators |
| 4 | Infrastructure Argo CD manifests | Argo CD app and Application Set | Almost never | Operators |
The first category is the standard Kubernetes resources (deployment, service, ingress, config, secrets etc) that are defined by any Kubernetes cluster. These resources have nothing to do with Argo CD and essentially describe how an application runs inside Kubernetes. A developer could use these resources to install an application in a local cluster that doesn’t have Argo CD at all. These manifests change very often as your developers deploy new releases and they are updated in a continuous manner usually in the following ways:
- Updating the container image version on the deployment manifest (maybe 80% of cases)
- Updating the container image AND some kind of configuration in a configmap or secret (maybe 15% of cases)
- Updating only the configuration to fine-tune a business or technical property (maybe 5% of the cases)
These manifests are very important to developers as they describe the state of any application to any of your organization environments (QA/Staging/Production etc). It is worth mentioning that the promotion article talked specifically about these types of manifests.
The second category is the Argo CD application manifests. These are essentially policy configurations referencing the source of truth for an application (the first type of manifests) and the destination and sync policies for that application. Remember that an Argo CD application is at its core a very simple link between a Git repo (that contains standard Kubernetes manifests) and a destination cluster.
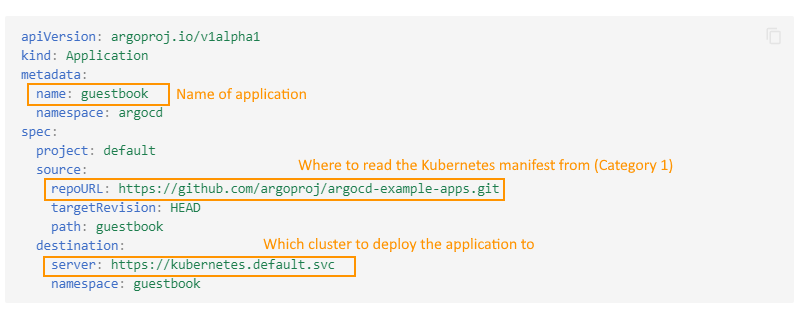
Contrary to popular belief, developers do not want to be bothered with these types of manifests. And even for operators, this type of manifest should be something that you set up once and then forget about it. Application Set manifests also fall in the same category.
The third and fourth category is the same thing as the first and second, but this time we are talking about infrastructure applications (cert manager, nginx, coredns, prometheus etc) instead of in-house applications that your developers create.
Note that it is possible to use a different templating system on these manifests than the applications of developers. For example, a very popular pattern is to use Helm for off-the-shelf applications, while choosing Kustomize for the applications created by your developers.
We are going to briefly talk about these types of manifests (categories 3 and 4), but the main focus of the article is on the first two categories. The reasons for that are
- Developers don’t care about infrastructure manifests
- These manifests do not change very often. Usually only when you upgrade the component in question or when you fine-tune the parameters.
The key point here is that these 4 types of manifests have different requirements in several aspects such as the target audience and most importantly the change frequency. When we talk about “GitOps repository structure” you should always start by explaining which category of manifests we are talking about (if more than one).
Anti-pattern 1 – Mixing different types of manifests
Before explaining the best practices it is important to warn against some anti-patterns, ideas that seem good in the beginning but end up complicating things in the long run.
One of the crucial points of your manifests is to have a very clear separation between Kubernetes (category 1) and Argo CD resources (category 2). For convenience, Argo CD has several features that allow you to mix both categories. Even though this is needed in some corner cases, we advise AGAINST mixing different types of manifests.
As a quick example, Argo CD supports the following syntax for a Helm application:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-helm-override
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/example-org/example-repo.git
targetRevision: HEAD
path: my-chart
helm:
# DONT DO THIS
parameters:
- name: "my-example-setting-1"
value: my-value1
- name: "my-example-setting-2"
value: "my-value2"
forceString: true # ensures that value is treated as a string
# DONT DO THIS
values: |
ingress:
enabled: true
path: /
hosts:
- mydomain.example.com
# DONT DO THIS
valuesObject:
image:
repository: docker.io/example/my-app
tag: 0.1
pullPolicy: IfNotPresent
destination:
server: https://kubernetes.default.svc
namespace: my-app
This manifest is two things in one. The main file is about an Argo app (category 2) but the “helm” property actually contains values for the Kubernetes application (category 1).
This manifest can be easily corrected by putting all the parameters in a values file in the same Git repository as the chart like this
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-helm-override
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/example-org/example-repo.git
targetRevision: HEAD
path: my-chart
helm:
## DO THIS (values in Git on their own)
valueFiles:
- values-production.yaml
destination:
server: https://kubernetes.default.svc
namespace: my-app
There is also the case of using Helm Umbrella charts that allow you to both reference other charts and override specific values on them.
Using external charts (i.e. not stored in Git) is also possible, but not an approach that we recommend. Using external charts from third-party sources presents a lot of challenges with both security and stability.
Ideally all your Helm charts should be under your control and in Git so that you can get all the benefits of GitOps with them.
However we understand that sometimes this is not possible. So as a last resort only you can use multiple sources to both reference an external Helm chart while still using your own values stored locally. Note that at the time of writing this guide this feature is in Beta.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-proper-helm-app
namespace: argocd
spec:
sources:
- repoURL: 'https://my-chart/helm-charts'
chart: my-helm-chart
targetRevision: 3.7.1
helm:
valueFiles:
- $values/my-chart-values/values-prod.yaml
## DO THIS (values in Git on their own)
- repoURL: 'https://git.example.com/org/value-files.git'
targetRevision: dev
ref: values
destination:
server: https://kubernetes.default.svc
namespace: my-app
In a similar manner Argo CD also supports the following:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-kustomize-override
namespace: argocd
spec:
source:
repoURL: https://github.com/example-org/example-repo.git
targetRevision: HEAD
path: my-app
# DONT DO THIS
kustomize:
namePrefix: prod-
images:
- docker.io/example/my-app:0.2
namespace: custom-namespace
destination:
server: https://kubernetes.default.svc
namespace: my-app
Here properties from Kustomize (category 1) are again mixed with the main Application manifest (category 2). To avoid this you should instead save your Kustomize values as an overlay instead of hardcoding them in the Application CRD
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-proper-kustomize-app
namespace: argocd
spec:
source:
repoURL: https://github.com/example-org/example-repo.git
targetRevision: HEAD
## DO THIS. Save all values in the Kustomize Overlay itself
path: my-app/overlays/prod
destination:
server: https://kubernetes.default.svc
namespace: my-app
The litmus test to understand if your manifests are divided correctly is to ask the following question:
“If a developer is expert on Kubernetes resources, but knows nothing about Argo CD, can they still install the application locally on their laptop using only kustomize (or Helm)” ?
If the answer is NO, then you need to find the point where the Kubernetes manifests “bleed into” Argo CD applications and remove the tight coupling.
I have seen lots of organizations that unfortunately fall into the trap of mixing the manifests and almost always when I discuss with them, they think that this approach is “required” because they never understood the capabilities of the underlying tools (Helm/Kustomize).
If your organization works with Helm make sure that you know how Helm value hierarchies work and how Helm umbrella charts work. You can cover most typical scenarios with a carefully designed Helm value hierarchy. Only employ the multi-source feature of Argo CD if you have no other option. And remember that it is in Beta right now.
If your organization works with Kustomize make sure that you know how components work (reusable blocks) as well as all the various transformers/patches/replacements.
Diving the two types of manifests is a good practice as you see in the later sections, but it should be obvious from the table shown in the previous section that mixing things with different life cycles is always a recipe for trouble.
Mixing the different types of manifests has several different challenges:
- It makes manifests harder to understand for all involved parties
- If confuses the requirements for people that use manifests (e.g. devs) vs those that create manifests (i.e. admins/operators)
- It couples your manifests to specific Argo CD features
- It make separating security concerns more complex
- It results in more moving parts and difficult to debug scenarios
- It makes local testing for developers much more difficult.
Note: Another Argo CD feature that you should NOT use is parameter overrides. In their most primitive form, they don’t even follow the GitOps principles. Even if you save them in Git, again you have a mix of Argo CD and Kubernetes information in the same place (mixing category 1 and category 2 information).
Anti-pattern 2 – Working at the wrong abstraction level
The purpose of Argo CD application CRDs is to work as a “wrapper” or “pointer” to the main Kubernetes manifests. The thing that matters is the Kubernetes manifests(category 1) and Argo CD manifests(category 2) should always have a supporting role.
In the ideal case, you should create an Application manifest once to define which Git repo goes to which cluster and then never touch this file again (this is why in the previous table the change frequency is “almost never”).
Unfortunately, we see a lot of companies that use the Application CRD as their main unit of work instead of the actual Kubernetes manifests.
The classic example is where they use a CI process to automatically update the “targetRevision” (or “path”) field in an Application.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
## DONT DO THIS
name: my-ever-changing-app
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/example-org/example-repo.git
targetRevision: dev
## earlier it was "targetRevision: staging" and before that it was "targetRevision: 1.0.0",
## and even earlier it was "targetRevision: 1.0.0-rc"
path: my-staging-app
## Previously it was "path: my-qa-app"
destination:
server: https://kubernetes.default.svc
namespace: my-app
Essentially treating an Application CRD as a mutable file that changes all the time implies several underlying problems and bad practices. For example, continuously pointing the targetRevision field to different branches almost always means the organization is using branches for environments which we strongly advise against.
It also means that looking at a Git repository by itself isn’t a clear indication of what the desired state is, instead, each application can have its own separate target revision that needs to be understood and compared to another Git repository for the full picture.
An Argo CD application is NOT a reusable box that can be used to run arbitrary applications. The whole point of GitOps is to have a clear history of events for what an application did. But if you treat the application CRD as a generic unit of work that you can point to completely different manifests you lose one of the main benefits of GitOps.
Also in most cases, you should change the underlying Kubernetes manifests themselves instead of the CRD. For example, instead of changing the targetRevision field to a branch that has a newer image of the application, you should instead change the application image directly on the Kubernetes deployment resource that is pointed by the Argo CRD.
Antipattern 3 – Using templating at different/multiple levels
A close relative of the previous anti-pattern is to apply templating facilities at the Application CRDs (category 2). Helm and Kustomize are already very powerful tools and can cover most cases with templating the main Kubernetes manifests (category 1). And even if your use case is not covered you can always use custom configuration plugins, or even pre-render your manifests with any external tool that you like.
The problem starts when people try to template Application CRDs, as they try to solve the issues created by the previous anti-pattern.
The classic example here is when a team creates a Helm chart containing Application CRDs which themselves point to the Helm charts of the Kubernetes manifests. So now you are trying to apply Helm templates into two different levels at the same time. And as your Argo CD footprint grows, it is very difficult for newcomers to understand how your manifests are structured.
The fact that Argo CD doesn’t include a powerful templating mechanism for templating Application CRDs should be a strong hint that this workflow is NOT the one we recommend. And with the introduction of ApplicationSets (see next point), the proper place to apply templating is on the ApplicationSet and not on individual Application files.
Antipattern 4 – Not using Application Sets
We have talked a lot about Application manifests (category 2) and what not to do with them. Here is the main twist of this article. Ideally, you shouldn’t need to create Application CRDs at all 🙂
If you have any type of non-trivial Argo CD installation you MUST spend some time to understand how ApplicationSets work and study at the very least the Git generator and the Cluster generator and how to combine them.
Application Sets can take care of the creation of all your application manifests (category 2) for you. For example, if you have 20 applications and 5 clusters, you can have a SINGLE application set file that will autogenerate the 100 combinations for your Argo CD applications.
Here is an example taken from the GitOps certification
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: cluster-git
spec:
generators:
# matrix 'parent' generator
- matrix:
generators:
# Git generator, 'child' #1
- git:
repoURL: https://github.com/codefresh-contrib/gitops-cert-level-2-examples.git
revision: HEAD
directories:
- path: application-sets/example-apps/*
# cluster generator, 'child' #2
- clusters: {}
template:
metadata:
name: '{{path.basename}}-{{name}}'
spec:
project: default
source:
repoURL: https://github.com/codefresh-contrib/gitops-cert-level-2-examples.git
targetRevision: HEAD
path: '{{path}}'
destination:
server: '{{server}}'
namespace: '{{path.basename}}'
This generator says “take all the apps under application-sets/example-apps and deploy them to all clusters currently defined in Argo CD”. It doesn’t matter how many clusters are currently connected or how many applications exist in the Git repo. The Application Set generator will automatically create all the possible combinations and also continuously redeploy as you add new clusters or new applications.
Those familiar with Argo CD Autopilot will recognize this pattern as the default setup for repo organization, albeit from a monorepo perspective.
Notice that application sets DO support some basic templating, so it is possible to still keep Helm/Kustomize for your main Kubernetes manifests, while still having some flexibility on the Application CRDs. Be sure not to miss Go template support for application sets.
Note that you are not required to use a single ApplicationSet for all your applications. You can also use multiple one for each “type” of applications, whatever type means in your case.
Best practice – Use the three-level structure
In the previous sections, we have seen some approaches that we don’t recommend and some pitfalls to avoid. We are now ready to talk about our suggested solution.
The starting point should be a 3-level structure as shown in the image below
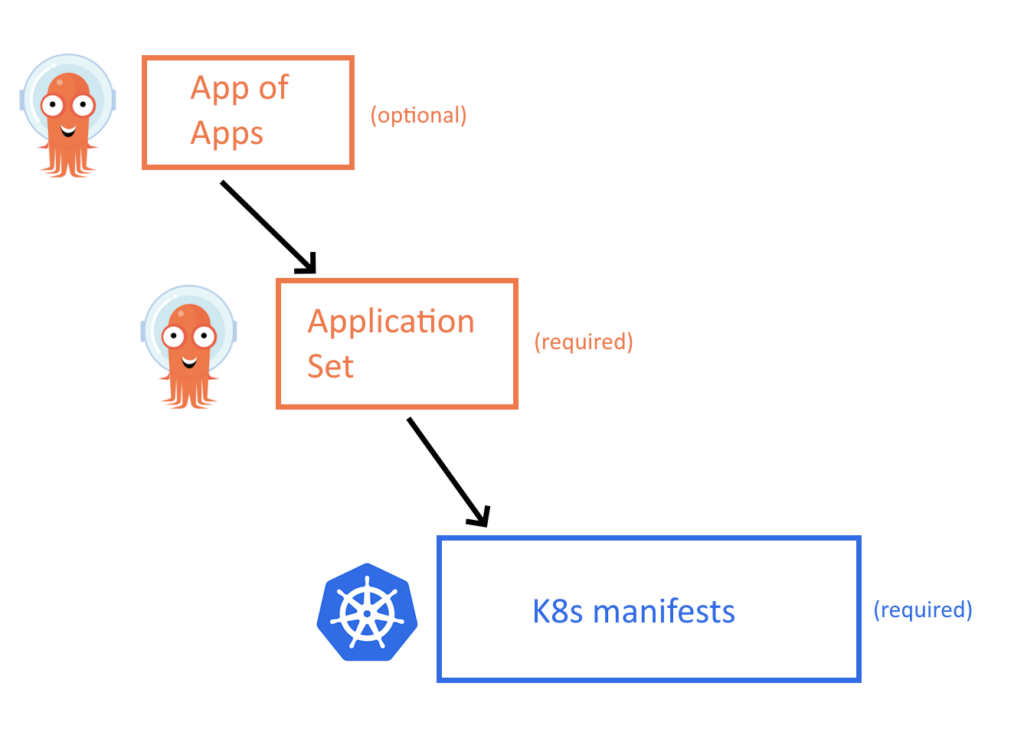
At the lowest level we have the Kubernetes manifests that define how the application runs (category 1 of manifests). These are your Kustomize or Helm templates and they are completely self-contained, meaning that they can be deployed on their own on any cluster even without Argo CD. We have covered in detail the structure of these files in the promotion blog post.
One level above, we have the Application Set as explained in the previous section. These wrap the main Kubernetes manifests into Argo CD applications (category 2 of manifests). Notice that in most cases you only need to create ApplicationSets and not individual Application CRDs.
Last, as an optional component you can group all your application sets in an App-of-App that will help you bootstrap a completely empty cluster with all apps. This level might not be needed if you have a different way of creating clusters (i.e. with terraform/pulumi/crossplane) and this is why it is not always essential.
And that’s it!
Notice how simple this pattern is:
- There are only 3 levels of abstraction. We have seen companies that have 4 or 5 making the mental model much more complex
- Each level is completely independent of everything else. You can install the Kubernetes manifests on their own, or you can pick a specific application set or you can pick everything at the root. But it is your choice.
- Helm and Kustomize are only used once at the Kubernetes manifests and nowhere else. This makes the templating system super easy to understand
Let’s look at a real-world example. You can find an example repo at https://github.com/kostis-codefresh/many-appsets-demo

Here we have chosen to place our Kubernetes manifests in “apps” and the application Set in the “appsets” folder. The names do not really matter. You can pick anything you want as long as it is clear what is going on.
The “apps” directory holds the standard Kubernetes manifests. We are using Kustomize for this example. For each application, there is an overlay ONLY for the applicable environments.
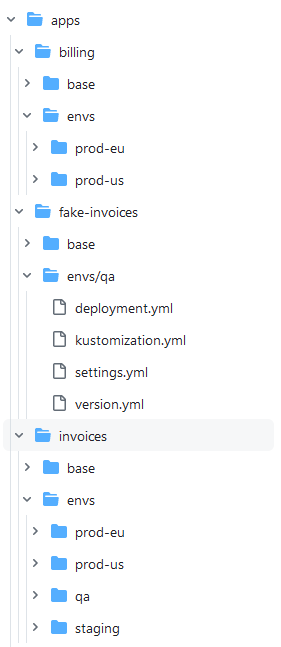
The structure was described in detail on the promotion blog post.
It is important to note that if you look at the overall structure each environment is placed on the directory “apps/<name-of-app>/envs/<name-of-env>”
In the appsets folder, we keep all our application sets. In this trivial example, it is a flat list but in a more advanced example, you could have folders here as well for better organization.

Each application set simply mentions the overlays defined in the Kubernetes manifest. Here is for example the “qa” appset
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: my-qa-appset
namespace: argocd
spec:
goTemplate: true
goTemplateOptions: ["missingkey=error"]
generators:
- git:
repoURL: https://github.com/kostis-codefresh/many-appsets-demo.git
revision: HEAD
directories:
- path: apps/*/envs/qa
template:
metadata:
name: '{{index .path.segments 1}}-{{index .path.segments 3}}'
spec:
# The project the application belongs to.
project: default
# Source of the application manifests
source:
repoURL: https://github.com/kostis-codefresh/many-appsets-demo.git
targetRevision: HEAD
path: '{{.path.path}}'
# Destination cluster and namespace to deploy the application
destination:
server: https://kubernetes.default.svc
namespace: '{{index .path.segments 1}}-{{index .path.segments 3}}'
This application set says the following:
“Go to the apps folder. Search all folders that contain an application and if they have a subfolder envs/qa then create an Argo CD application”. So this appset will only deploy to the QA cluster applications with “qa” overlays. Applications without this overlay will not be deployed. You can look at the apps folder and you can see that not all applications are deployed to all environments. For example “billing” is deployed only in production while “fake-invoices” is only in QA
We also have an optional app-of-apps manifest that simply groups all the application sets together. This is not strictly needed but it helps you bootstrap an empty cluster from zero to everything
In our example, with just a single manifest we deployed 12 applications (this is the number of combinations that the application sets create) in a single step.
Note that this contrived demo repository uses a single cluster for all “environments”. In a production setup you also also use the cluster generator to split all applications into the respective clusters (qa/prod/staging).
Day 2 operations for Argo CD applications
So why is this structure the optimal one? Let’s take a look at some common scenarios and see how simple they are using the demo repository of the previous sections.
In the previous sections, we argued that you need to split Kubernetes manifests (category 1) from Argo CD manifests (category 2). The main goal behind this decision is to make life easy for developers and help them with common scenarios. Let’s see some examples for developers:
Scenario 1 – A developer just wants to inspect the “qa” configuration of the “invoices” app
Solution 1:
cd apps/invoices kustomize build envs/qa
The solution is a single command and no Argo CD installation is needed.
Scenario 2 – A developer wants to understand what settings are different between US and Europe for the “billing” app
Solution 2:
cd apps/billing kustomize build envs/prod-eu/> /tmp/eu.yml kustomize build envs/prod-us/ > /tmp/us.yml vimdiff /tmp/eu.yml /tmp/us.yml
The solution is 3 commands and no Argo CD installation is needed.
Scenario 3 – A developer wants to install on their local cluster the “qa” configuration of “orders” app.
Solution 3:
cd apps/orders kubectl apply -k -f envs/qa
Again, no Argo CD installation is needed.
If you had mixed the different types of manifest you would force developers to also deal with Argo CD. And testing locally with Argo CD is far more complex instead of just using a simple Kubernetes cluster.
For administrators/operators things are also very simple. Most operations are a single change in a single file/folder regardless of how many clusters and applications you have.
As an example, an administrator wants to deploy the “payments” application to the QA environment (currently it is only running in prod environments).
cd apps/payment/env mkdir qa <create k8s manifests for qa> <wait for Argo CD to sync>
Essentially anything the administrator wants to do corresponds to a simple Git action
- Deploy an existing application to a new environment -> Create a new Kustomize overlay. No Argo CD changes are needed.
- Remove an application from an environment -> Delete the respective Kustomize overlay. No Argo CD changes are needed.
- Create a brand new application -> Commit the K8s manifests in a new folder under “apps”. No Argo CD changes are needed.
- Create a new environment called “integration” based on the qa one -> Copy/modify the qa application set to a new file for “integration”. In the next sync Argo CD will create the new combinations for all applications that have an “integration” overlay.
- Add a new cluster -> Connect the cluster to Argo CD and all applicationsets that reference it will automatically deploy their applications to that cluster as well.
- Move a cluster to a different environment -> Simply add/edit a new label on the cluster for the respective application set.
The key point here is to keep a clear separation of concerns with a clear separation of manifests. Developers can work with plain Kubernetes resources without knowledge of what Argo CD is modeling, and administrators can easily use applicationsets and folders in order to move applications between environments.
Bootstrapping a brand new cluster for an existing environment is super quick, as you only need to add it to the respective cluster generator.
Monorepo, Monorepo, Monorepo
The example repository we shared in the previous section assumes that all applications are somehow related. Maybe they are part of a bigger application or are handled by the same team.
In a big organization, you have several applications and several teams with completely different needs and limitations. A lot of teams struggle with the choice of using multiple Git repositories or using a single one (monorepo) for all their applications. And of course, we have our own recommendation here as well.
It is imperative first that we define what “Monorepo” means because as we discuss with many administrators and developers it is clear that people have different meanings for this word according to their background.
Essentially we have found 3 distinct areas where people call “monorepo” a specific Git organization structure.
Developers usually mention “morepos” when it comes to organizing source code. Instead of having one repository for each application, some teams choose to have a single repository that groups the source code from all applications in the organization. This technique was popularized by Google in the last decades and most online resources about “monorepos’ essentially talk about this technique.
What is important here is that this definition only applies to source code. Argo CD doesn’t deal with source code, so all resources that mention pro/cons for this approach are not really related to Argo CD. Unfortunately, we see a lot of administrators who reference these kinds of articles when adopting Argo CD and they do not understand that these source code techniques do not make sense in the context of Argo CD managing Kubernetes manifests.
The second definition of “monorepo” that we have seen in the wild, is when people describe as “monorepos” the Git repositories that contain both source code and Kubernetes manifests and Argo CD manifests at the same time. While this technique is related to Argo CD we have recommended multiple times to separate source code from manifests. We just mention this definition for completeness because several times teams say to us “we use a monorepo for our Argo CD applications” and what they actually mean is that their Git repositories contain both manifests and source code (and not necessarily that they have a single Git repository for the whole organization).
The third definition of “monorepo” and the one we are interested in this article is the case where an organization has a SINGLE Git repository for all Argo CD applications. There is no source code in this repository, but the key point is that it contains all deployed applications even when they are completely unrelated to each other. So is this a good practice or not?
Best practice – use a Git repository per team
The problem with a monorepo (as defined by the last definition of the previous section) is that it suffers from several scalability and performance issues as the number of Argo CD applications grows. Argo CD already has several mechanisms for dealing with monorepos, but it is best to avoid the problems on their root instead of trying to deal with them as more teams adopt Argo CD.
The single monorepo is indeed a very logical decision to take when you start your Argo CD journey. Having a single repository makes things easy for maintenance and observability. In the long run, however, it has several limitations not only in the way that Argo CD detects commits but also how the Git repository deals with conflicts and retries from all the different workflows that interface with the Git repository as a deployment source.
Our recommendation is to have multiple Git repositories. Ideally one for each team or each department. Again the basic question you should always ask yourself is if the applications contained in the Git repository are related in some way. Either they are micro-services and part of a bigger application, or they can be loosely coupled components that are used by a single team.
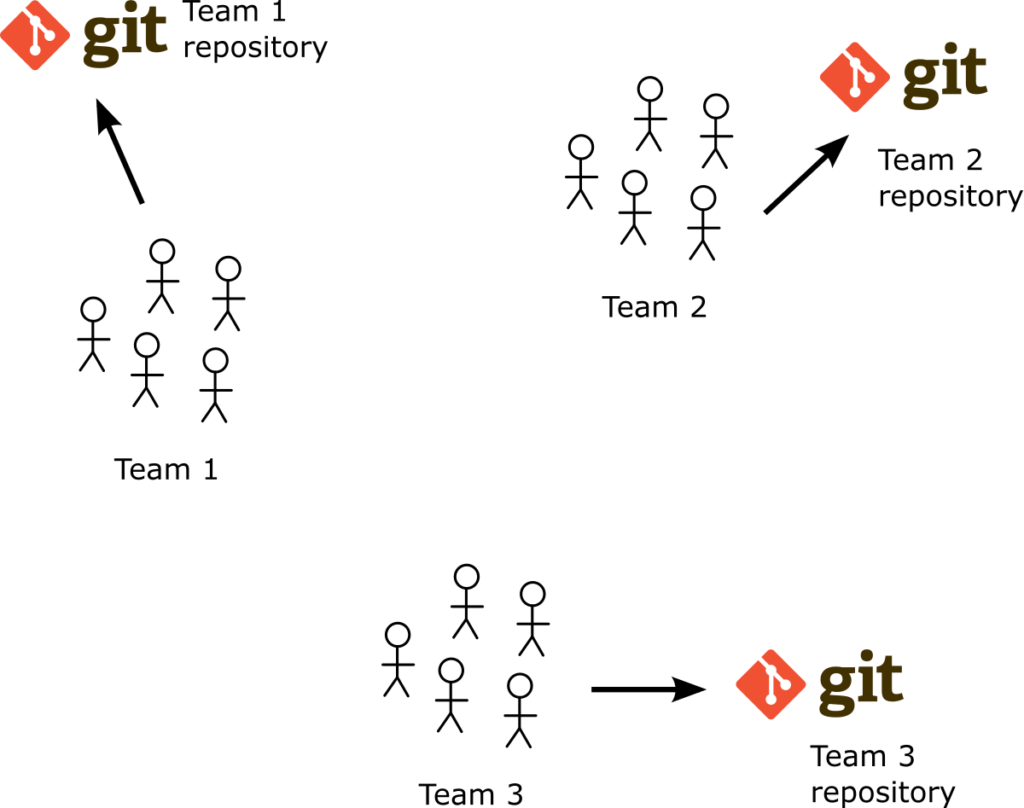
The benefits of multiple Git repositories are visible both in performance and in usability aspects. Especially for developers, multiple Git repositories are preferable as they can focus on the Kubernetes manifests of their respective applications instead of forcing them to deal with applications that are not part of their team.
What about infrastructure applications?
We have talked extensively about Kubernetes manifests (category 1) and Argo CD resources (category 2). What about infrastructure applications (categories 3 and 4)? Where to place them?
You can store infrastructure manifests in the same way as developer applications using the 3-level structure mentioned in the previous sections. It is imperative however that you don’t mix those manifests with those that developers need. And the best way to separate them is to have another Git repository.
Don’t mix infrastructure applications and developer applications in the same Git repo. Again, this is not only beneficial for Argo CD performance but it is also a good technique for helping developers.
So we can update the previous picture and include another Git repository for infrastructure applications for the team that handles infrastructure.
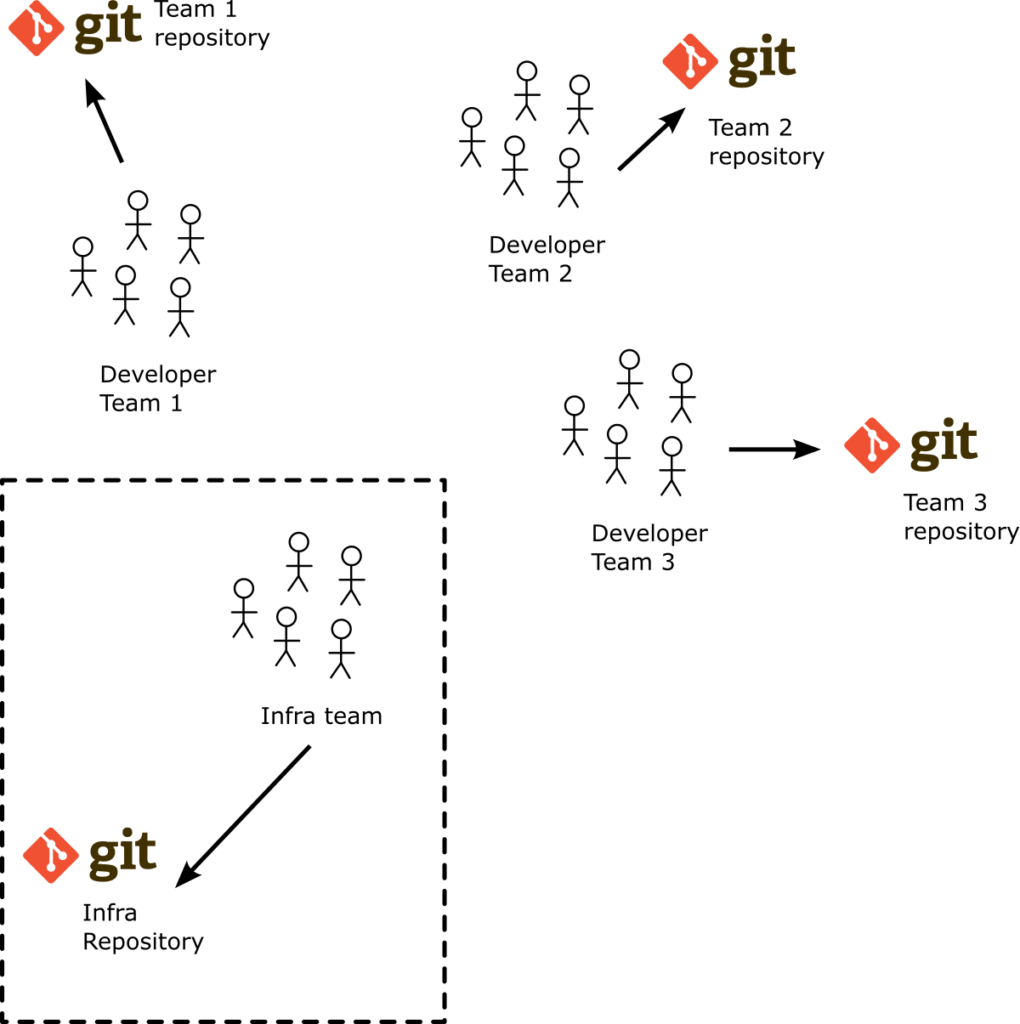
This way as a developer on my team I can check out a Git repository that has only the stuff that I am interested in. The respective Argo CD application is super fast as well as the CI system that touches this Git repository. There is a minimal number of Git conflicts and if you want to apply additional security constraints you can use the existing Git mechanisms offered by your Git provider
Once you have a large number of applications and teams you might find the need to share some common applications. There are several ways to do that. One quick way would be to have Application Sets that reference manifests from other teams. Another way would be to use a “common” Git repository for applications that are needed by all teams.
In a future article we will see more advanced scenarios, including using Git submodules for the two types of manifests as well as more advanced sharing techniques.
Summary
We have reached the end of this comprehensive guide on how to leverage Application Sets to organize and manage your Argo CD applications.
We have seen:
- What are the different kinds of Kubernetes and Argo CD manifests
- Why it makes sense to understand the different lifecycles of these manifests
- How Argo CD application sets work
- How to employ a simple 3-level structure of a set of interconnected applications
- Some common pitfalls to be avoided
- How to deal with infrastructure applications
- How to split your GitOps repositories for different teams.
We hope that you have a good understanding on how to organize your GitOps repositories. Welcome to Argo CD 🙂
Photo by Breno Assis on Unsplash