Article Content
What Is Continuous Delivery?
Continuous delivery (CD or CDel) prepares deployments for production, allowing development teams to deploy changes easily with the push of a button (typically, the merge to master command, which pushes the deployment to the master branch).
Continuous delivery produces artifacts deployable to production—the next step after continuous integration (CI). It allows the organization to wait before deploying each new release to evaluate the change.
The main catch in continuous delivery is that a human must still push the button to deploy the release. Companies often set up a CD process without realizing its full benefits, because manual approval takes time and holds up release of new features to customers.
What Is Continuous Deployment?
Continuous deployment (CD or CDep) involves deploying every push to production automatically. There is no human intervention, so the organization doesn’t hold up the pipeline for approval. The only difference between continuous delivery and continuous deployment is the “button” that employees must push to approve promotion of a build to production.
With CDep, the pipeline automatically and frequently pushes changes to production without waiting for a human to approve each deployment. It creates a more streamlined workflow and reduces bottlenecks. The organization must have full trust in the CI/CD process to ensure new releases are of high quality and ready to be pushed to customers with no human intervention.
9 Best Practices for Adopting Continuous Delivery
Implement Continuous Integration First
Continuous delivery is part of a Continuous Integration/Continuous Delivery (CI/CD) pipeline, so it is critical to have continuous integration in place before you get started with continuous delivery. Once you have a robust CI process in place, you are ready to progress to continuous delivery.
Learn more in our detailed guide to the CI/CD pipeline (coming soon)
Catalog Your Containers and Artifacts
A CI/CD pipeline involves verifying that new features are ready for deployment to production. Building confidence in new releases is a gradual process—each step in the pipeline adds a layer of assurance. This approach only works if you ensure that the features you test throughout the pipeline are the same as what you deploy.
However, many organizations create different artifacts for each environment (QA, staging, and production). If you deploy a different version of the release to the production environment, there is no guarantee it will function correctly.
Avoid last-minute edits and configuration drift, ensuring you use a single artifact across all environments. To achieve this, you can leverage containers and self-sufficient application packages (i.e., Docker). In general, the artifact or container doesn’t have any configuration, retrieving the required config during runtime.
These approaches guarantee that the package deployed in production is the same one tested in the pipeline. Containerization works with immutable artifacts—with each deployment artifact built only once. Containers can move artifacts unchanged through the pipeline without rebuilding the source code (as happens with a commit-based approach).
Ensure Your Testing Suite Is Sound
The purpose of integration, unit, and functional tests is to verify the integrity of every new release before deployment. Comprehensive testing should theoretically eliminate regressions on new features once published. CI/CD -platforms can fully automate and manage these tests.
The pipeline should include testing before deployments and after pull requests. For full automation, the test suite must run in one step. However, many organizations continue to create tests using old approaches, with engineers manually executing each test and slowing down the release pipeline.
Test engineers should only be responsible for writing new tests, not executing them manually. Manual testing slows down the feedback loop, which is acceptable for a small sample of tests but not for the main test suites.
There are various unit tests, some with side effects (write) and others without side effects (read-only). Tests without side effects only read data from external sources and don’t make modifications—these are easy to handle and maintain. Tests with side effects can write to the database and commit data to an external system—these are harder to maintain because you need to undo their actions after they finish.
The recommended approach is for each test to clean up its side effects—it allows you to run tests in parallel, which is important for dynamic testing environments.
Be Confident in Your Tests
An effective CI/CD pipeline requires fast test execution. Otherwise, the tests can slow down the delivery pipeline. The testing time should be equivalent to the packaging or compilation time, usually between five and 15 minutes.
Developers must be confident that their features are safe to push to the next pipeline stage without regressions. Tests must be fast to prevent the developers from waiting after a commit or focusing on other tasks and impeding the workflow.
Most of the waiting time during tests results from inefficient testing practices. Tests should not “sleep” or wait for events to happen—they should respond to events immediately. The process of creating test data can also be time-consuming, so you should have centralized, reusable data creation code. Tests with slow setup phases might be testing too much. Refactor any tests that take hours.
Use dynamic testing environments in your development process to allow multiple test suites to run in parallel. Test parallelism helps speed up the testing phase and ensure test correctness with no uncontrolled side effects. Read-only tests especially should run in parallel. Tests with special dependencies and write tests can slow down the pipeline, so you need to ensure these tests are self-sufficient.
Automate Database Deployments
Many organizations invest in automated application code deployment pipelines while neglecting database update automation. Your databases are as important as the application.
Extend the CI/CD approach to databases, using the following steps to enable automation:
- Keep your changesets in the Git source control.
- Create pipelines to update the database upon the creation of changesets automatically.
- Set up temporary dynamic environments for databases to review changesets before merging them.
- Perform quality checks like code reviews on changesets.
- Implement a rollback strategy for failed database updates.
Your pipeline should also automatically convert production data to test data. Keeping copies of all your production data in a test environment is not always a viable option. Keep a small subset of anonymized data for efficient handling.
Progressive delivery methods are not suited to databases (due to the inherent state), although you can adopt an evolutionary database design approach and plan database updates. This approach ensures that changesets are backward and forward compatible, letting you roll back database changes easily.
This process requires a disciplined team because each change to the database spans multiple deployments. However, it offers important advantages, allowing you to return to previous versions without downtime or data loss.
Incorporate Security Scanning into the Process
Code scans are an important part of the daily development workflow, like security scans. These scans include:
- Static code analysis for on-brand formatting and style
- Static code analysis for security issues and hidden vulnerabilities
- Runtime code analysis for errors
Several tools can handle the analysis, but many organizations don’t execute these tools automatically. Development teams often intend to use tools like Sonarqube for future software projects but forget to use them when the time comes. Sometimes, developers ignore the warnings and errors listed in analysis reports.
Incorporate code quality scans into the pull request process. Don’t just report the final results to the developers—make sure they apply best practices such as preventing merges based on warnings.
Release Selectively
Many organizations adopting continuous deployment find it difficult to trust the process. The concern is that if a developer commits early and frequently and without any oversight, a buggy or half-baked feature could reach the end-users.
You can address this concern by using feature flags. This approach is better than reliance on branches as it benefits from continuous integration. When writing code, the developers can use the flags to control which elements are visible or hidden from the end-users.
Automate All Repeatable Processes
Newcomers to DevOps often neglect the required manual steps of an automated delivery pipeline. Many organizations require manual actions before, during, or after each release. Some organizations hesitate to automate tasks due to the upfront cost, learning curve, or inertia (i.e., they are used to a manual decision-making process).
However, automation is the key to an effective, scalable CI/CD process. The more you automate, the better. Ensure all repetitive tasks are automated throughout the development, testing, and deployment phases.
You should automate all tests, configuration updates, and dependency collection. Evaluate which processes are repeatable and suitable for automation, and identify tasks that require manual approval or intervention.
Release Frequently
Release frequency is a priority in CD pipelines. Before each release, the software must be ready for release, having passed tests in production-like environments. A best practice is to include a deployment stage that utilizes a realistic testing environment before each release. There are various testing and release approaches, including:
- Canary deployment—you release an update to a subset of users to test it in a limited, real-world setting. If successful, you can roll out the deployment to a wider user base. If unsuccessful, you can roll back the release.
- Blue/green deployment—you set up two identical environments, with only one going live at a given time. You initially roll out new releases to the offline environment, and, if successful, you switch to the new environment, and the original production environment becomes idle. The first environment provides a backup, allowing you to switch back if there is an issue with the new release.
- A/B testing—you test new features in your application to verify performance and usability. You test different versions of a feature to identify the best one. While conceptually similar to blue/green deployment, A/B testing is not a deployment strategy. It is a testing phase before release.
Related content: Read our guide to continuous delivery pipeline
7 Best Practices for Continuous Deployment
Implement Continuous Delivery First
Continuous deployment is the next phase after continuous delivery, so you need to make sure you have implemented the standard CI/CD pipeline before progressing to continuous deployment. For example, you need to automate all possible testing, scanning, and software delivery tasks and implement a frequent release pipeline, to enable further pipeline automation.
It is not effective to pick and choose practices from continuous delivery and deployment in the wrong order. You must complete all tasks associated with continuous delivery first, or you won’t be able to implement continuous deployment properly.
Control the Rollout Process
The continuous deployment process automatically releases features and updates after passing the previous stages of the CI/CD pipeline. However, you don’t need to surrender control over the process.
You can use several deployment techniques to control rollouts and minimize risks. For example, the canary release approach lets you test out new features with a limited proportion of end-users. The blue/green deployment approach helps you manage transitions to new feature versions.
Implement Progressive Delivery
Progressive delivery pipelines extend the principle of CI/CD to enable faster code shipping, continually enhance user experience, and minimize risks. It is a key capability for DevOps, while feature management is important for progressive delivery.
Progressive delivery involves rolling out new features gradually to evaluate user engagement and limit the negative impacts of a bug. It offers greater security and control over the release process while supporting the continuous delivery of new code to production. In short, it is a more secure way to implement CI/CD.
Use Metrics and Logs
Even if your pipeline can deploy applications automatically, you need to have a way to determine the actual results of deployments. A deployment might appear successful at first but then introduce regressions. Development teams often use manual smoke tests and visual checks to assess an application, but they might miss subtle performance issues and bugs.
Adopt application metrics such as detailed event logs, feature monitoring metrics, counters, information traces to provide insights into requests. These metrics let you assess deployments comprehensively, providing warnings before you push a failed deployment.
Larger applications may require a gradual process to define key metrics. Apply metrics to events you suspect are problematic and test them over multiple deployments to see if they detect failures. If the metrics don’t detect all failed deployments, they are insufficient, and you need to fine-tune them.
Prepare for Fast Rollbacks
Using the appropriate metrics to verify deployment success, you can set up fast, automated rollbacks. Many organizations use powerful metrics manually without leveraging them for automation. Typically, developers review the metrics before and after triggering deployments. However, this approach is less effective for complex applications, where viewing metrics becomes time-consuming.
It often takes several hours until someone marks a deployment as failed—developers might ignore or misunderstand warnings. The reliance on humans to watch metrics means that an organization can only deploy updates during working hours.
To streamline your rollbacks, ensure the metrics are part of your deployment process, with the pipeline automatically reviewing metrics after each deployment. A fully automated pipeline can mark a deployment as finished or roll it back.
Monitor the Production Environment
Many organizations feel that continuous deployment is risky, even if they’ve implemented all the necessary measures. It is important to have a way to manage bugs that evade detection and reach production, but remediation can be costly and time-consuming, potentially damaging the company’s reputation. Manual deployment processes don’t eliminate this concern either, but stakeholders intuitively trust human experts more than automated systems.
You need to proactively look for indications of bugs and performance issues rather than relying on reports after deployment. Monitoring is useful for building confidence and ensuring you find deviations from expected behavior, especially in the immediate aftermath of a release. Set up tools to monitor statistics and alert team members to issues quickly to minimize the impact on end-users.
Streamline the Pipeline
When things go wrong in the production environment, you need to respond immediately. Some situations allow you to roll back releases to previous versions, but it’s not always a straightforward process. Migrating databases and fixing known issues can help prevent many problems, but sometimes you need to implement a complex fix.
Some organizations skip certain steps in their CI/CD pipeline, creating a false economy and increasing the likelihood of introducing issues that normal tests might have detected. You should invest in streamlining the pipeline to make the build and testing processes faster. Faster pipelines allow you to deploy changes faster when needed while shortening the various feedback loops of each release.
Continuous Delivery vs Deployment: Which One Should You Choose?
Before considering whether to implement continuous delivery or deployment, make sure your organization has a DevOps culture that can support it. A core part of DevOps is aiming to automate the entire software delivery process.
Continuous deployment might be relevant to your organization if you are:
- Able to deploy without approval from stakeholders (at least in theory, if delivery was fully automated).
- Your CI/CD pipeline is fully automated from end to end.
- Customers are accustomed to small, frequent iterations in production (or if not, you are willing to make this transition).
- Teams are able to respond to errors in production quickly and “roll forward” with additional releases that resolve issues.
If any of these are not true, the best next step is to fully automate your CI/CD process. Your goal should be achieving continuous delivery, with the ability to go from a code change to production deployment with no manual steps except human approval. Over time, you can transition from continuous delivery to full continuous deployment.
Whether you “only” achieve continuous delivery or full continuous deployment, you will enjoy most of the benefits of automated software delivery—code is always deployable with no release date pressure, faster releases and customer feedback, higher reliability, and improved productivity for developers.
Continuous Delivery and Deployment with Argo and GitOps
Argo is an open source project suite for accelerating and securing software delivery. Developers can use Kubernetes-native Argo to deploy applications more easily.
Argo offers tools to help developers progressively deliver software, allowing them to define the tasks required to ship and distribute each service. These tools include:
- Argo CD—a GitOps tool for Kubernetes-based continuous deployment. The configuration logic resides in a Git repository, allowing developers to use their existing development and review workflows with code from Git. Argo CD does not directly handle continuous integration but integrates with CI systems.
- Argo Rollouts—a Kubernetes controller for progressive delivery. It allows you to implement progressive deployment for rolling update techniques, such as blue/green deployments, canary deployments, and A/B testing.
- Argo Workflows and Pipelines—a Kubernetes-native workflow engine that orchestrates parallel Kubernetes jobs and can also be used for Continuous Integration.
- Argo Events—a workflow automation and dependency management tool based on events. It facilitates Kubernetes resource, Argo workflow, and serverless workload management, utilizing events from various sources.
Argo is useful for GitOps pipelines, enabling easier application lifecycle and deployment management. GitOps blurs the line between development and operations teams—automating deployment makes it easier to audit, troubleshoot, and roll back releases.
Continuous Delivery and Deployment Made Easy with Codefresh
Whether you are familiar with Argo CD or new to continuous delivery, you can immediately gain value from the Codefresh. The Codefresh UI brings the full value of Argo CD and Argo Rollouts and lets you visualize all your pipelines in a single view.
Codefresh takes an opinionated but flexible approach to software delivery. To deploy an application, simply define the git source of manifests and set a deployment target. Doing this from the UI will commit the configuration to git. Once in git, Codefresh GitOps will automatically detect the application and deploy it in your Kubernetes cluster.
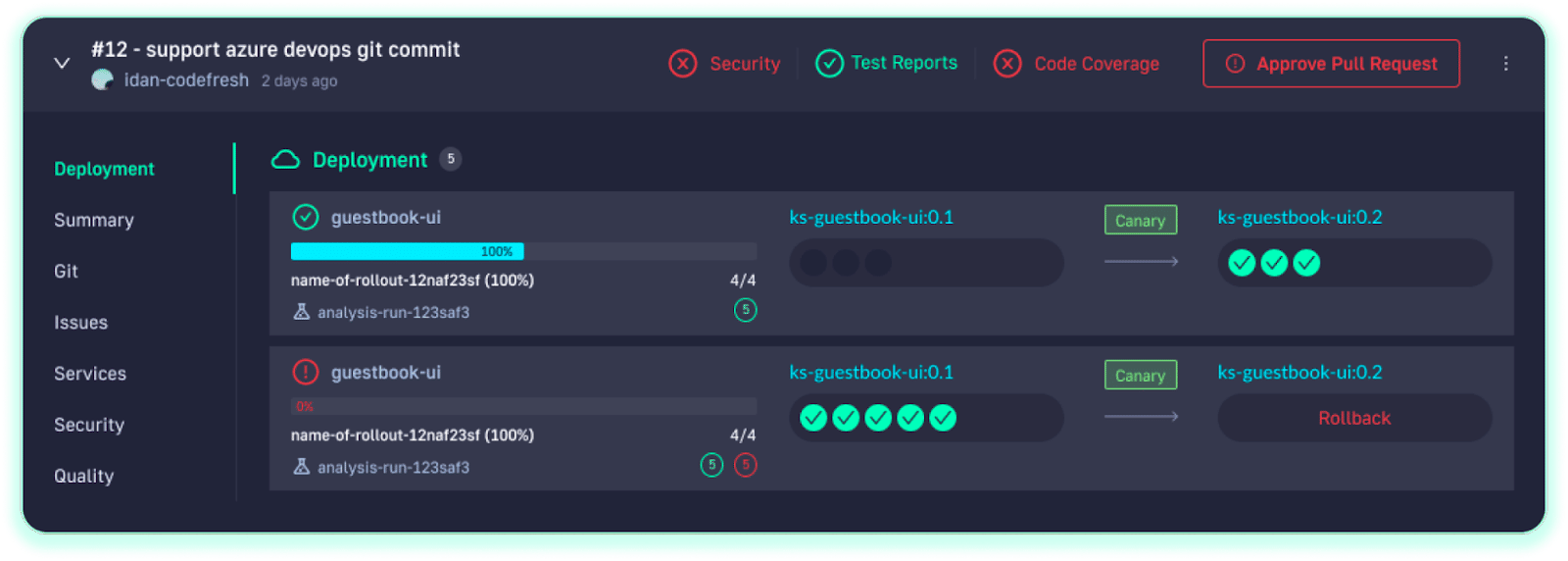
Easily supporting progressive deployment
Progressive delivery has long been out of reach for release teams because of complex requirements. In the Codefresh platform, progressive delivery strategies like canary or blue/green deployment can be simply defined in a declarative manner.
Canary and blue/green deployments can greatly reduce the risk of rolling out new changes by automatically detecting issues before they hit most users and rolling back to previous stable versions. Here is how Codefresh visualizes canary releases along with the health checks monitoring their rollout:
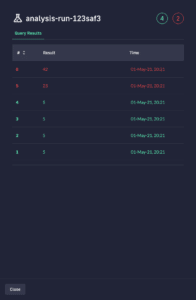
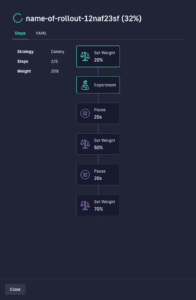
Building a complete delivery pipeline
You can’t get to continuous delivery or deployment without first solving continuous integration. Codefresh automatically creates a Delivery Pipeline, which is a workflow along with the events that trigger it. We’ve added a pipeline creation wizard that will create all the component configurations so you can spend less time with YAML and more time getting work done.
At the end of the pipeline creation wizard, Codefresh commits the configuration to git and allows its built-in Argo CD instance to deploy them to Kubernetes.
The Delivery pipeline model also allows the creation of a single reusable pipeline that lets DevOps teams build once and use everywhere. Each step in a workflow operates in its own container and pod. This allows pipelines to take advantage of the distributed architecture of Kubernetes to easily scale both on the number of running workflows and within each workflow itself.
Deploy more often and with greater confidence
Teams that adopt Codefresh deploy more often, with greater confidence, and are able to resolve issues in production much more quickly. This is because we unlock the full potential of Argo to create a single cohesive software supply chain. For users of traditional CI/CD tooling, the fresh approach to software delivery is dramatically easier to adopt, more scalable, and much easier to manage with the unique hybrid model.

The World’s Most Modern CI/CD Platform
A next generation CI/CD platform designed for cloud-native applications, offering dynamic builds, progressive delivery, and much more.
Check It Out