Article Content
What Is a Kubernetes Health Check?
Kubernetes health checks determine the health state of applications running in pods. They ensure applications operate as expected, enhancing the reliability and stability of your Kubernetes cluster. Health checks can identify and remedy issues automatically, like restarting containers that are not functioning correctly. They are crucial for maintaining high availability in dynamic and scalable environments.
Kubernetes health checks typically involve probes that automatically query the state of an application. Kubernetes offers three main types of probes: liveness, readiness, and startup. Each probe has a distinct purpose and checks a different aspect of the application’s state. Understanding and implementing these probes correctly is vital for Kubernetes management.
Why Should You Monitor Kubernetes Application Health?
Monitoring application health in Kubernetes is important for ensuring continuous and uninterrupted service. When applications fail, automated health checks can trigger necessary actions such as restarting failed containers, preventing extended downtimes. This automation decreases the need for manual intervention, saving time and reducing error rates associated with human interventions.
Additionally, monitoring can optimize resource utilization. By continuously assessing the state of applications, Kubernetes can make intelligent decisions about resource allocation, balancing loads, and scaling services up or down as necessary. This adaptability leads to more efficient use of computational resources and can reduce operational costs.
Three Types of Kubernetes Probes
Kubernetes aims to ensure application reliability via three primary types of probes:
Liveness Probe
Liveness probes determine whether an application is alive and functioning within a container. They help identify instances where an application becomes unresponsive or enters a failed state. If the liveness probe fails, Kubernetes automatically restarts the container, potentially resolving transient issues.
Liveness probes can be configured based on HTTP requests, command executions, or TCP connections. They must be defined considering the application’s behavior to avoid false positives or negatives. Correct usage of liveness probes contributes to higher application availability by ensuring only functional instances are running.
Readiness Probe
Readiness probes assess whether an application is ready to serve traffic. They are crucial for load balancing and service discovery since they ensure traffic is directed only to healthy and ready instances. If a readiness probe fails, Kubernetes stops sending traffic to that particular pod without restarting it.
This type of probe is particularly useful during application startup or deployment phases when an application might need time to initialize resources or perform background tasks. Correctly configuring readiness probes can enhance user experience by directing traffic exclusively to fully operational application instances.
Startup Probe
Startup probes protect slow-starting applications. They ensure that applications that take longer to start are not terminated prematurely. These probes override liveness and readiness checks during the startup phase, preventing false positives from causing unnecessary restarts.
By using startup probes, you can relax the constraints of liveness and readiness probes temporarily, allowing sufficient time for the application to become fully functional. This is especially useful for legacy applications or those that perform extensive initialization tasks before becoming operational.
Types of Kubernetes Health Checks Protocols
Kubernetes supports several protocols for performing health checks. These protocols allow flexibility in defining how probes interact with applications to determine their health state.
HTTP Requests
HTTP request-based probes use standard HTTP methods to check the state of an application. The probe sends an HTTP GET request to a specified endpoint, and the application must respond with a status code in the 200-399 range to be considered healthy. This method is widely used due to its simplicity and compatibility with most web applications.
HTTP probes offer a straightforward way to verify application function since they can check specific URLs or paths within an application, ensuring that critical API endpoints or services are available and responsive. HTTP health checks are particularly useful for microservices architectures, where individual components often expose HTTP endpoints.
Commands Probes
Command probes execute specific commands within the container to check the health of an application. If the command exits with a status code of 0, the application is considered healthy. This method provides a high degree of flexibility, allowing the execution of scripts or commands tailored to the specific needs of the application.
Command probes are beneficial for applications where a simple HTTP check is insufficient. They can perform checks involving multiple criteria, such as verifying the presence of required files, checking memory usage, or confirming the operational states of internal services. However, they also introduce potential security concerns, as they require running potentially sensitive commands inside the container.
TCP Connections
TCP connection-based probes attempt to establish a TCP connection to a specified port of the application. If the connection is successful, the application is deemed healthy. This type of check is useful for applications that don’t expose HTTP endpoints but do listen on specific network ports.
This method is particularly useful for various applications, including databases, messaging systems, and custom network services that rely on TCP for communication. TCP probes offer a lightweight and effective way to verify that these applications are accessible and can accept new connections, ensuring that they are ready to handle traffic.
gRPC
gRPC-based probes extend TCP probes by incorporating application-level checks for services using the gRPC protocol. They perform a status check by invoking a specific gRPC service method. If the response indicates success, the pod is considered healthy. This method is tailored for applications using gRPC for communication and requires support from the application side.
gRPC probes are advantageous for modern applications that favor gRPC over traditional HTTP for performance and efficiency reasons. They provide a more granular and application-aware health check capability, ensuring not only that the network layer is functional but also the application logic is working correctly.

VP of Open Source, Octopus Deploy
Dan is a seasoned leader in the tech industry with a strong focus on open source initiatives. Currently serving as VP of Open Source at Octopus Deploy, contributing as an Argo maintainer, co-creator of Open GitOps, and leveraging extensive experience as a co-founder of Codefresh, now part of Octopus Deploy.
TIPS FROM THE EXPERT
In my experience, here are tips that can help you better implement Kubernetes health checks:
- Combine multiple probes for complex checks: Use a combination of HTTP, command, and TCP probes to ensure comprehensive health checks. For instance, an HTTP probe can check the application’s primary endpoint, while a command probe verifies internal states or dependencies, reducing the risk of false positives or negatives.
- Leverage custom health endpoints: Create dedicated /healthz endpoints in your application that aggregate various health indicators, such as database connectivity, third-party service availability, and cache health. This ensures the liveness and readiness probes get a holistic view of the application’s status.
- Optimize probe intervals and timeouts: Customize initialDelaySeconds, periodSeconds, and timeoutSeconds based on your application’s characteristics and startup time. Fine-tuning these settings helps avoid premature restarts or excessive delays in failure detection.
- Use failureThreshold and successThreshold for stability: Set higher failureThreshold values for liveness probes in applications with transient issues to avoid unnecessary restarts. Conversely, a higher successThreshold for readiness probes ensures that the application is truly ready before it starts receiving traffic.
- Implement retry logic in startup probes: When using startup probes, add retry logic in the application to handle initialization failures gracefully. This allows the probe to succeed without requiring the container to be restarted, especially for applications with external dependencies during startup.
Tutorial: Configuring 6 Types of Health Check in Kubernetes
1. Define a Liveness Command
Liveness probes help identify and remedy scenarios where applications enter a non-recoverable state, typically requiring a restart. To configure a liveness probe using a command, consider the following example:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: registry.k8s.io/busybox
args:
- /bin/sh
- -c
- |
while true; do
echo "I'm healthy"; sleep 30;
echo "Now unhealthy"; sleep 600;
done
livenessProbe:
exec:
command:
- /bin/sh
- -c
- grep -q "I'm healthy" /proc/1/fd/1
initialDelaySeconds: 5
periodSeconds: 5
Let’s store the above configuration in a file called liveliness.yaml and apply it using the following command:
kubectl apply -f liveliness.yaml

In this configuration, the livenessProbe executes the command grep -q "I'm healthy" /proc/1/fd/1 command every 5 seconds after an initial delay of 5 seconds. The container is considered healthy as long as the above command receives the response ‘I’m healthy’. If the response is not returned after 30 seconds, the probe will fail, causing Kubernetes to restart the container.
2. Define a Liveness HTTP request
Liveness probes can also be configured to use an HTTP request to check the application’s health:
apiVersion: v1
kind: Pod
metadata:
name: busybox-liveness
spec:
containers:
- name: my-container
image: busybox
args:
- /bin/sh
- -c
- "while true; do sleep 30; done"
livenessProbe:
exec:
command:
- wget
- --spider
- -q
- http://localhost:80/healthz
initialDelaySeconds: 5
periodSeconds: 10
Let’s assume we saved the above code in a file called http_liveness.yaml. We can apply it using the following command:
kubectl apply -f http-liveness.yaml

Here, the liveness probe sends an HTTP GET request to the /healthz path on port 80 every 10 seconds after an initial delay of 5 seconds. If wget fails and it will return 1 (or other than 0), the container is considered healthy; otherwise, Kubernetes will restart the container.
3. Define a TCP Liveness Probe
For applications that do not expose an HTTP endpoint, a TCP socket check can be used:
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox-tcp-liveness
spec:
replicas: 1
selector:
matchLabels:
app: busybox-app
template:
metadata:
labels:
app: busybox-app
spec:
containers:
- name: busybox-container
image: busybox
command: ["sh", "-c", "nc -l -p 8080"] # Simulate a TCP server
ports:
- containerPort: 8080
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
Let’s store the above YAML in a file called tcp-liveness-readiness.yaml. Apply it using the following command:
kubectl apply -f tcp-liveness-readiness.yaml
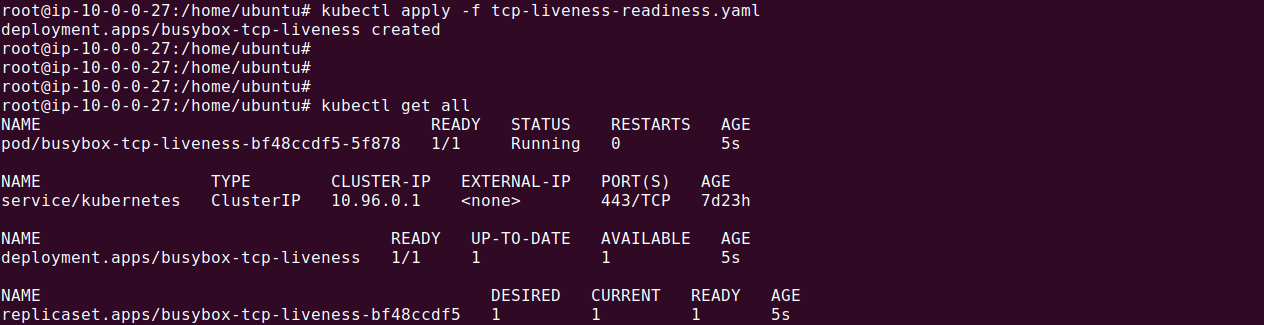
In this example, Kubernetes will attempt to establish a TCP connection to port 8080 every 10 seconds, starting 15 seconds after the container begins. If the connection cannot be established, the container is restarted. Please note we use the following command to simulate a running TCP server at port 8080:
command: ["sh", "-c", "nc -l -p 8080"] # Simulate a TCP server
4. Define a gRPC Liveness Probe
For applications that use gRPC, Kubernetes supports gRPC-based liveness probes:
apiVersion: v1
kind: Pod
metadata:
name: grpc-liveness-test
spec:
containers:
- name: agnhost
image: registry.k8s.io/e2e-test-images/agnhost:2.35
command: ["/agnhost", "grpc-health-checking"]
ports:
- containerPort: 5000
- containerPort: 8080
readinessProbe:
grpc:
port: 5000
livenessProbe:
grpc:
port: 5000
initialDelaySeconds: 5 # Time to wait before starting the first probe
periodSeconds: 10 # Time interval between probes
Let’s store the above configuration in grpc-liveness.yaml. We can apply it using the following command:
kubectl apply -f grpc-liveness.yaml
This configuration instructs Kubernetes to check the health of the gRPC service running on port 5000 every 10 seconds after an initial delay of 5 seconds. If the gRPC health check fails, Kubernetes will restart the container.
5. Protect Slow Starting Containers with Startup Probes
Startup probes are useful for containers that require extra time during initialization:
apiVersion: v1
kind: Pod
metadata:
name: slow-startup-sample
spec:
containers:
- name: slow-startup-module
image: busybox:latest
ports:
- name: liveness-port
containerPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 2
periodSeconds: 8
startupProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 25
periodSeconds: 24
Let’s save the above configuration in a file called slow.yaml. We can apply this file using:
kubectl apply -f slow.yaml

In this example, the startupProbe allows up to 10 minutes (25 attempts with 240 second intervals) for the application to fully start. Once the startup probe succeeds, the livenessProbe takes over to quickly detect and respond to deadlocks.
6. Define Readiness Probes
Readiness probes ensure that traffic is only routed to containers that are ready to handle requests:
apiVersion: v1
kind: Pod
metadata:
name: readiness-probe-sample
spec:
containers:
- name: myapp
image: busybox:latest
ports:
- containerPort: 9000
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10
periodSeconds: 7
Let’s store above configuration in a file called readiness-probe.yaml, we apply it using the following command:
kubectl apply -f readiness-probe.yaml

In this configuration, the readiness probe uses a command to check the application’s state every 7 seconds after an initial delay of 10 seconds. If the probe fails, the container is marked as not ready, and traffic is not routed to it until it passes the readiness check. This ensures that only fully operational containers receive traffic, improving application reliability and availability.
Managing Production Kubernetes Deployments with Codefresh
Codefresh GitOps, powered by Argo, helps you get more out of Kubernetes and streamline deployment by answering important questions within your organization, whether you’re a developer or a product manager. For example:
- What features are deployed right now in any of your environments?
- What features are waiting in Staging?
- What features were deployed last Thursday?
- Where is feature #53.6 in our environment chain?
What’s great is that you can answer all of these questions by viewing one single dashboard. Our applications dashboard shows:
- Services affected by each deployment
- The current state of Kubernetes components
- Deployment history and log of who deployed what and when and the pull request or Jira ticket associated with each deployment
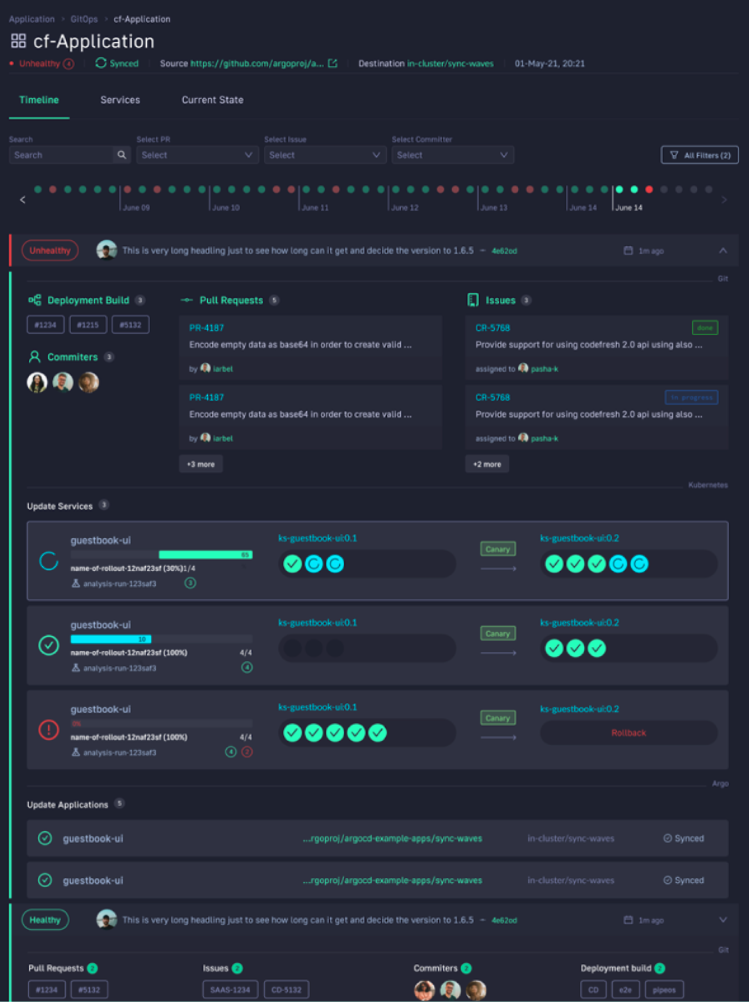
This allows not only your developers to view and better understand your deployments, but it also allows the business to answer important questions within an organization. For example, if you are a product manager, you can view when a new feature is deployed or not and who was it deployed by.
Ready to Get Started?
Deploy more and fail less with Codefresh and Argo