
The time has finally come! After the massive success of our Docker and Kubernetes guides, we are now ready to see several anti-patterns for Argo CD. Anti-patterns are questionable practices that people adopt because they seem like a good idea at first glance, but in the long run, they make processes more complicated than necessary.
Several times, we have spoken with enthusiastic teams that recognize the benefits of Gitops and want to adopt Argo CD as quickly as possible. The initial adoption phase seems to go very smoothly and more and more teams are getting onboarded to Argo CD. However, after a certain point things start slowing down and developers start complaining about the new process.
Like several open source projects, Argo CD has several capabilities that can be abused if you don’t have the full picture in your mind. The end result almost always makes life really difficult for developers.
So keep your developers happy and don’t fall into the same traps. Here is the full list of the antipatterns we will see:
| Number | Area | |
|---|---|---|
| 1 | Not understanding the declarative setup of Argo CD | Adopting Gitops |
| 2 | Creating Argo CD applications in a dynamic way | Adopting Gitops |
| 3 | Using Argo CD parameter overrides | Adopting Gitops |
| 4 | Adopting Argo CD without understanding Helm | Prerequisite knowledge |
| 5 | Adopting Argo CD without understanding Kustomize | Prerequisite knowledge |
| 6 | Assuming that developers need to know about Argo CD | Developer Experience |
| 7 | Grouping applications at the wrong abstraction level | Application Organization |
| 8 | Abusing the multi-source feature of Argo CD | Application Organization |
| 9 | Not splitting the different Git repositories | Application Organization |
| 10 | Disabling auto-sync and self-heal | Adopting Gitops |
| 11 | Abusing the target Revision field | Adopting Gitops |
| 12 | Misunderstanding immutability for container/git tags and Helm charts | Adopting Gitops |
| 13 | Giving too much power (or no power at all) to developers | Developer Experience |
| 14 | Referencing dynamic information from Argo CD/ Kubernetes manifests | Application Organization |
| 15 | Writing applications instead of Application Sets | Application Organization |
| 16 | Using Helm to package Applications CRDs | Application Organization |
| 17 | Hardcoding Helm data inside Argo CD applications | Developer Experience |
| 18 | Hardcoding Kustomize data inside Argo CD applications | Developer Experience |
| 19 | Attempting to version Applications and Application Sets | Application Organization |
| 20 | Not understanding what changes are applied to a cluster | Developer Experience |
| 21 | Using ad-hoc clusters instead of cluster labels | Cluster management |
| 22 | Attempting to use a single application set for everything | Cluster management |
| 23 | Using Pre-sync hooks for db migrations | Developer Experience |
| 24 | Mixing Infrastructure apps with developer workloads | Developer Experience |
| 25 | Misusing Argo CD finalizers | Cluster management |
| 26 | Not understanding resource tracking | Cluster management |
| 27 | Creating “active-active” installations of Argo CD | Cluster management |
| 28 | Recreating Argo Rollouts with Argo CD and duct tape | Adopting Gitops |
| 29 | Recreating Argo Workflows with Argo CD, sync-waves and duct tape | Adopting Gitops |
| 30 | Abusing Argo CD as a full SDLC platform | Adopting Gitops |
The order of anti-patterns follows the timeline of an organization that starts with minimal Argo CD knowledge and slowly migrates several applications to the GitOps paradigm.
Anti-pattern 1 – Not understanding the declarative setup of Argo CD
Following the GitOps principles means that Argo CD can take your Kubernetes manifests (or Helm charts or Kustomize overlays) from Git and sync them on your Kubernetes cluster. This process is well understood by teams and most people are familiar with saving Kubernetes manifests in Git.
It is important to note however that even this link between a cluster and a Git repository is a Kubernetes resource itself.
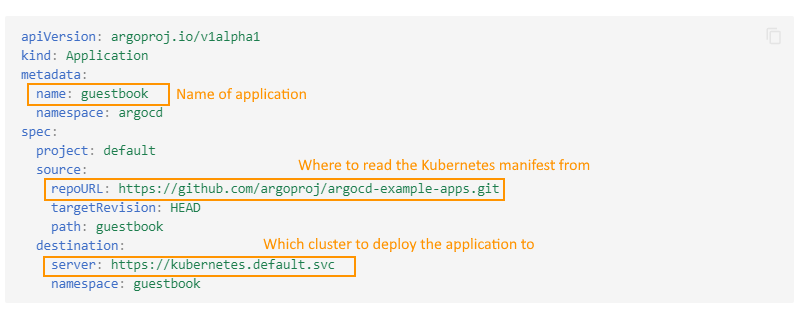
Argo CD introduces its own Custom Resource Definitions (CRDs) for several of its central concepts such as applications and projects and also reuses existing Kubernetes CRDs for clusters, secrets, etcs.
These files should also be stored in Git. That is the whole point of following GitOps. It doesn’t make sense to use Git only for some files and not store the Applications themselves similarly.
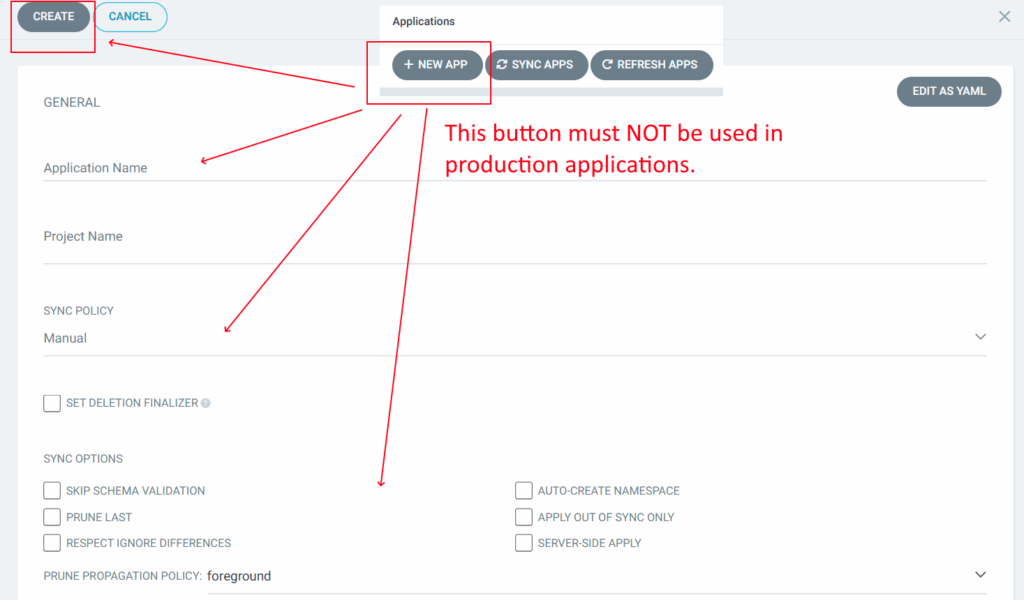
We see several teams that use the Argo CD UI or CLI to create applications that are not stored anywhere and then have difficulties understanding what is deployed where or how to recreate their Argo CD configuration from scratch.
It should be noted that the “create new app” button in the Argo CD UI is only for experiments and quick tests. You should not use it at all in a production environment as the created application is not saved anywhere.
Everything that Argo CD needs should be stored in Git. Recreating an Argo CD instance should be a simple process with minimal steps:
- Create a new cluster with Terraform/Pulumi/Crossplane etc.
- Install Argo CD itself using Terraform/Autopilot/Codefresh etc.
- Point Argo CD to your ApplicationSets or root app-of-apps file
- Finished.
Recreating your Argo CD instance is a repeatable process that can be performed in less than 5 minutes (explained in anti-pattern 27).
If you want a comprehensive guide on how to organize your Kubernetes manifests in Git see our Application Set guide.
Anti-pattern 2 – Creating Argo CD applications in a dynamic way
A related anti-pattern occurs when organizations have an existing process for creating applications and when they adopt Argo CD they simply call the Argo CD CLI or API to pass the information they already have.
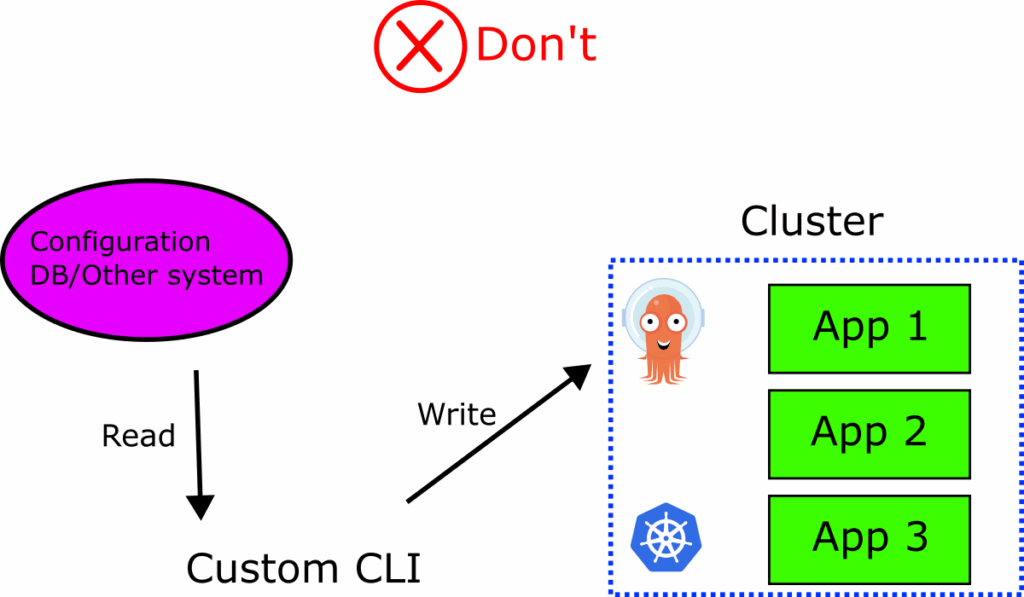
Essentially there is an existing database or application configuration somewhere else and a custom CLI or other imperative tool does the following:
- Extracts application configuration from the existing database
- Creates an Argo CD application or Kubernetes manifest on the fly
- Applies this file to an Argo CD instance without storing anything in Git.
You fall into this trap if the “official” way of creating Argo CD applications in your organization is something like this:
my-app-cli new-app-name | argocd app create -f -
Or several times, envsubst is used like this
envsubst < my-app-template.yaml | kubectl apply -f -n argocd
The end result is always the same. You have custom Argo CD applications that are not saved anywhere in Git. You lose all the main benefits of GitOps:
- You don’t have a declarative file for what is deployed right now
- You don’t have a history of what was deployed in the past
- Recreating the Argo CD instance is not a single-step process any more (see anti-pattern 27)
To overcome this anti-pattern you need to make sure that you use Argo CD the way GitOps works.
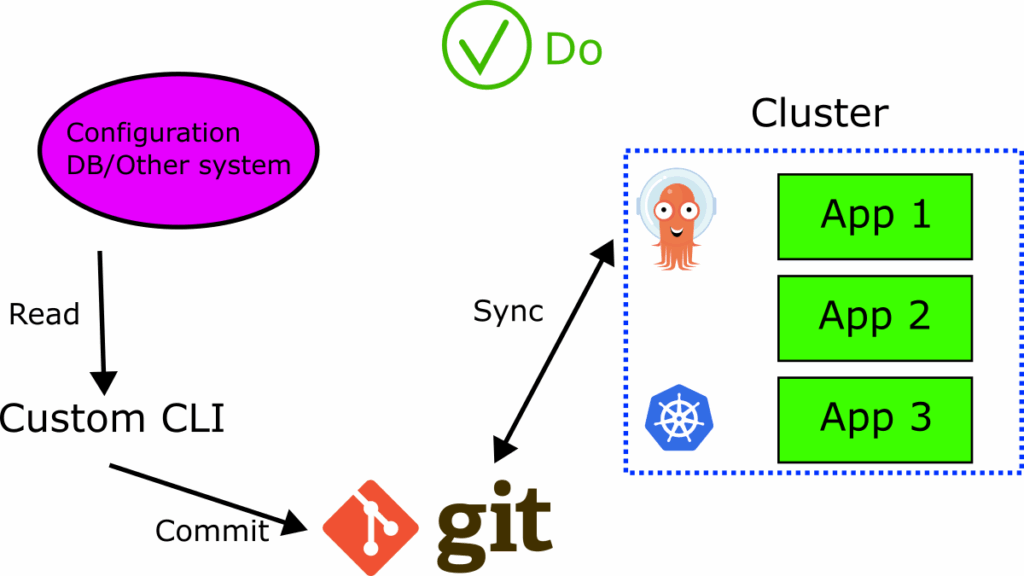
You either need to convert your existing database settings and make them read/write to Git or discard them completely and start using Git as the single source of truth for everything.
Then, all day 2 operations should be handled by Git.
The same is true for updating existing applications. If you want to update the configuration of an application, the process should always be the same:
- You (or an external system) change a file in Git
- Argo CD notices the change in Git
- Argo CD syncs the changes to the cluster.
If you use the Argo CD API or the Kubernetes API to manually patch resources then you are not following GItOps.
Updating applications in production with any of the following commands goes against the GitOps principles.
kubectl set image deployment/my-deployment my-container=nginx:1.27.0 kubectl patch deployment <deployment-name> [.....patch here…]
Use the Kubernetes API only for experiments and local tests, never for production upgrades (see also anti-pattern 10 – disabling auto-sync).
Anti-pattern 3 – Using Argo CD parameter overrides
Yet another way of updating an Argo CD application in a manner we do NOT recommend is the following:
argocd CLI app set guestbook -p image=example/guestbook:v2.3
The guest book application was just updated to version v2.3. Argo CD syncs the version and everything looks good. But where was this action saved? Nowhere.
This command is using the parameters feature of Argo CD that allows you to override any Argo CD application with your own custom properties. Even the official documentation has a huge warning about not using this feature as it goes against the GitOps principles.

Even if you save the parameter information in the Application manifest, you have now completely destroyed local testing for developers (see anti-patterns 6 and 17).
Anti-pattern 4 – Adopting Argo CD without understanding Helm
Helm is the package manager for Kubernetes. In its original form it offers several essential features in a single platform:
- A package format for Kubernetes manifests
- A repository specification for storing Helm packages in artifact managers
- A templating system
- A comprehensive CLI
- A lifecycle definition (upgrade, install, rollback, test )
Argo CD renders all Helm charts using the template command and completely discards most other lifecycle features. Even though in theory this is a good thing as Argo CD can replace the default Helm lifecycle (e.g. Argo CD comes with its own rollback command), Argo CD assumes that you already know how Helm templates work.
If you are adopting Argo CD and want to use Helm, then make sure that you know how Helm works on its own and how all your applications can be deployed in all your different environments WITHOUT Argo CD. Trying to learn Argo CD and Helm together at the same time is a recipe for failure.

At the very least you should know how to create Helm hierarchies of values
common-values.yaml +-----all-prod-envs.yaml +----specific-prod-cluster.yaml
And how Helm works when loading the hierarchy with the correct overrides
helm install ./my-chart/ --generate-name -f common.yaml -f more.yaml -f some-more.yam
If you use Helm umbrella charts, understand how to override child values from the top chart.
In particular, pay attention to the following:
restaurant: menu: vegetarian
This can be a simple value setting for a Helm chart that sets the restaurant.menu value to “vegetarian”. It can also be an umbrella chart which has a dependency subchart called “restaurant” which itself has a property called “menu”. Understand why those two approaches are different and the advantages and disadvantages of each.
We have already written a complete guide on how to use Argo CD with Helm value hierarchies.
Anti-pattern 5 – Adopting Argo CD without understanding Kustomize
This is the same anti-pattern as the previous one but for Kustomize users. Kustomize is a powerful tool and includes several features such as
- Overlays for different environments
- Reusable component configurations
- Common globals (labels, annotations, namespace prefixes)
- Configuration generators
- Transformers/Replacements
- Remote resources
Argo CD can reuse all Kustomize features, provided that you have structured your Kustomize files correctly first.

Again make sure that your Kustomize files work on their own BEFORE bringing Argo CD into the picture. Well structured Kustomize applications are self-contained. Any developer should be able to use the kustomize (or kubectl) command to extract the configuration for an existing environment without the need for Argo CD.
We presented a full example for Kustomize configurations in our Argo CD promotion guide.
Anti-pattern 6 – Assuming that developers need to know about Argo CD
This is the corollary to the previous two antipatterns. Several teams mix Argo CD configuration data with Kubernetes configuration making the life of developers extremely difficult.

This is a big problem for developers as one of their most important tasks is to run an application locally both during development and when trying to pinpoint difficult bugs in isolation. Creating Argo CD configurations and coupling them with Kubernetes manifests prevents them from understanding how an application runs independently.
We will see more specific anti-patterns later that also contribute to this problem but it is best to know about this trap in advance when you start working with Argo CD.
Remember also that developers don’t care about Kubernetes manifests. They only care about source code features. It is one thing to ask them to learn the basics (i.e. Helm values) and a completely different thing to require Argo CD knowledge just to be able to recreate the configuration of an existing environment.
When you design your Argo CD repository, you should always consider a developer persona who is an expert on Kubernetes but knows nothing about Argo CD. Can they recreate any configuration of any application on their laptop without using Argo CD? If the answer is no, it means that you are the victim of this anti-pattern.
Find out where you have hardcoded Argo CD configurations with Kubernetes configurations and remove the tight coupling. For specific advice see anti-patterns 17 for Helm and 18 for Kustomize.
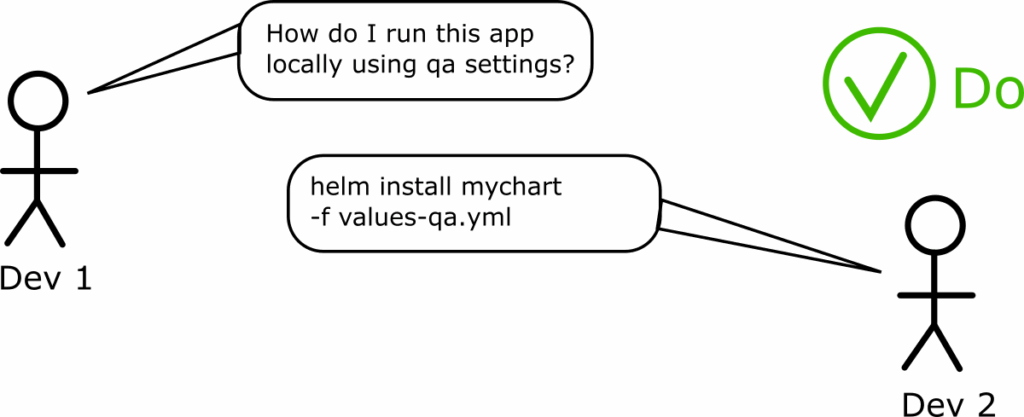
We have seen how to split Kubernetes configuration from Argo CD manifests in our Application Set guide.
Anti-pattern 7 – Grouping applications at the wrong abstraction level
As we explained in the first anti-pattern (store everything in Git), an Argo CD application is just a link between a Git repository and a Kubernetes cluster. It is not a deployment artifact or a packaging format.
We have seen teams that abuse an Argo CD application as a generic grouping mechanism, using it for microservices or even completely unrelated applications.
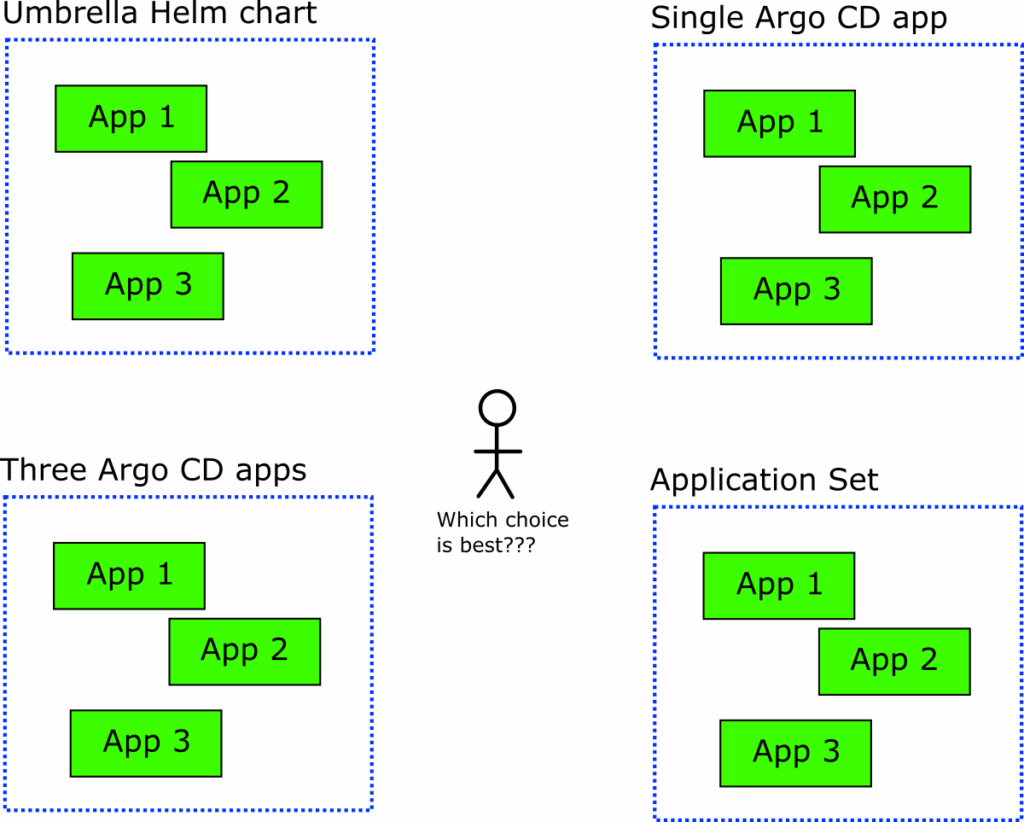
You need to spend some time understanding what your applications do and how tightly coupled they are. If you have a set of “micro-services” that are always deployed together and upgraded together, you might want to use an umbrella chart for them.
Argo CD applications should generally model something that requires individual deployments and updates. If you have several Argo CD applications that you always want to be managed together (but still want to deploy and update individually), then a better choice might be the app-of-apps pattern.
If several applications need to be deployed to different or similar configurations, then Application Sets are the proper recommendation.
So any time you want to group several applications, ask the following questions:
- Are those applications always deployed and upgraded as a single unit?
- Are those applications related in a business or technical manner?
- Do you want to use different configurations for different clusters for these applications?
- Is this combination of applications always the same? Do you sometimes wish to deploy a subset of them or a superset?
- Are these applications managed by a single team or multiple teams?
If you are unsure where to start, looking at Application Sets is always the best choice. Check also anti-pattern 19 (attempting to version application CRDs).
Anti-pattern 8 – Abusing the multi-source feature of Argo CD
This is a close relative of the previous anti-pattern. The Multi-source feature of Argo CD was one of the most requested features in the project’s history. The feature was created to solve a single scenario:
- You wish to use an external Helm chart that is not hosted by your organization
- You want to use your own Helm values and still store them in your own Gitrepository
- You need a way to instruct Argo CD to combine the external Helm chart with your own values.
The feature is finally implemented in Argo CD and you can finally do the following:
apiVersion: argoproj.io/v1alpha1
kind: Application
spec:
sources:
- repoURL: 'https://prometheus-community.github.io/helm-charts'
chart: prometheus
targetRevision: 15.7.1
helm:
valueFiles:
- $values/charts/prometheus/values.yaml
- repoURL: 'https://git.example.com/org/value-files.git'
targetRevision: dev
ref: values
Unfortunately, Argo CD does not limit the number of items you can place in the “sources” array. Several people have misunderstood this, abusing the feature to group multiple (often unrelated) applications.
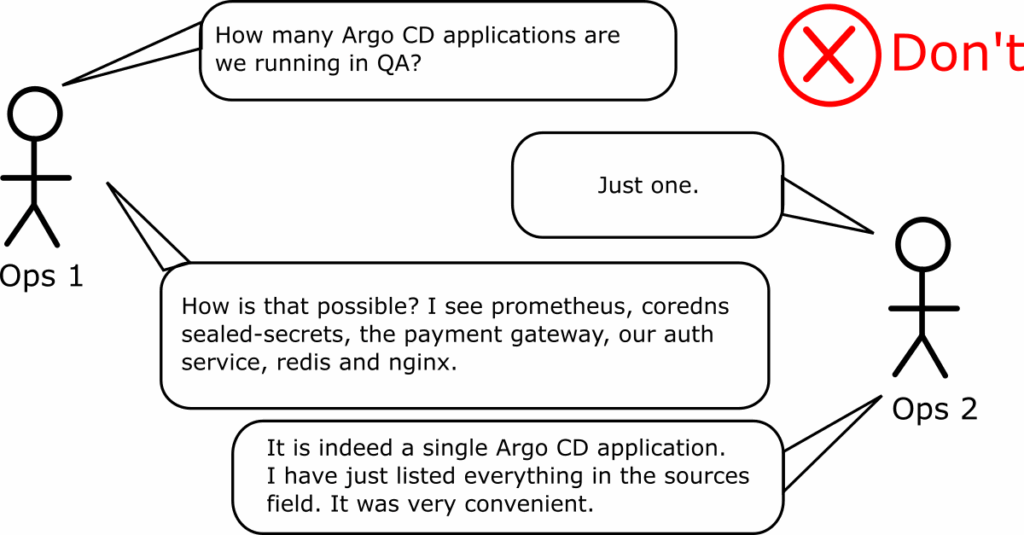
Don’t fall into this trap. The multi-source feature was never designed to work this way and several standard Argo CD capabilities will either be broken or not work at all if you use multi-sources as a generic application grouping mechanism.
The correct way to group applications is with Application Sets. If you want to use multisource applications with Helm hierarchies, we have also written an extensive guide.
Anti-pattern 9 – Not splitting the different Git repositories
If you look at any Kubernetes application from a high level it is comprised of 3 distinct types of files
- The source code
- Kubernetes manifests (deployment, service, ingress etc)
- Argo CD application manifests (or application sets)
We have already explained that as a best practice the source code should be separate than the manifests. If you are in a big organization it might also make sense to split Kubernetes manifests from Argo CD manifests.
If you keep all manifests in a single Git repository you will have issues with both CI (Continuous Integration) and CD (Continuous Deployment) phases. Your CI system will try to auto-build application code when a manifest changes, and Argo CD will try to sync applications when a developer changes the source code.
There are several workarounds for these scenarios, but why try to solve a problem that shouldn’t exist in the first place?
We have also seen several variations of the same pattern that make the deployment process even more complicated. A classic scenario to avoid is the following
- The source code of the application is in Git repository A
- The Helm manifest is in Git repository B
- Only the Helm values for the different environments are also stored in Git repository A
The assumption here is that Helm values are close to the source code that developers need to change. In reality, it never makes sense to have access to Helm values without also having access to the Helm chart that uses them. Either assume that developers know about Helm and show them everything, or assume that they don’t care about Kubernetes at all and offer them a different abstraction that hides Argo CD completely for them.
Yet another problem is mixing Kubernetes manifests and Argo CD manifests in the same repository but instead of using different folders, you hardcode Kubernetes information into Argo CD information. This is described in detail in anti-patterns 17 and 18.
Anti-pattern 10 – Disabling auto-sync and self-heal
Several times, migrating to Argo CD is a big undertaking, especially for organizations that have invested a significant amount of effort in traditional pipelines. After all, it can be argued that Argo CD simply replicates what is already possible with an existing Continuous Integration system:
- A change happens in Git in a manifest
- A separate process picks up the Git event
- The process uses kubectl (or a custom script) to apply the changes in the cluster.
This could not be further from the truth as Argo CD also works the other way around. It monitors changes in the cluster and compares them against what is in Git. Then you can make a choice and either review those changes or discard them altogether.
This means that Argo CD solves the configuration drift problem once and for all, something that is not possible with traditional CI solutions.
But this advantage only exists if you let Argo CD do its job. Some organizations disable the auto-sync/self-heal behavior in Argo CD in an effort to “lock-down” or fully control production systems.
This is a bad choice because production systems are exactly the kind of systems where you want to avoid configuration drift. Manual changes that happen in production (during hotfixes or other debugging sessions) are one of the biggest factors affecting failed deployments.
We recommend that you have auto-sync/self-heal for all your systems both production and non-production.
Locking down a system should not be done in Argo CD itself, but enforced on the cluster and Git level. The most obvious solution is to reject any direct commits in a Git repository that controls your production system and only allow developers to create Pull Requests which must pass several manual and automated checks before landing in the mainline branch that Argo CD monitors.
If you disable auto-sync/self-heal you are missing the number one advantage of moving to Argo CD from traditional pipelines (eliminating configuration drift).
Anti-pattern 11 – Abusing the targetRevision field
Promoting applications when adopting Argo CD is one of the biggest challenges for developer workloads. People see the targetRevision field in the Argo CD application and assume it is a promotion mechanism.
The first issue is when teams use semantic version ranges to force Argo CD to update an application automatically to a newer version. The second issue is if they continuously update the targetRevision field to different branch names or attempt to implement “preview environments” by pointing an Argo CD application to a temporary developer/feature branch.
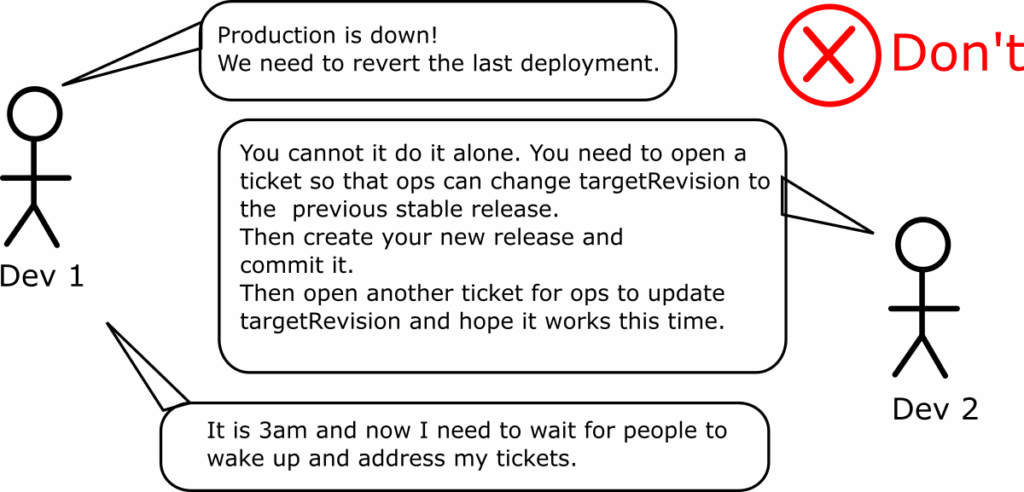
We have written a complete guide about the issues of abusing targetRevision.
In general, we recommend you always use HEAD in the targetRevision field which is also the default value.
Anti-pattern 12 – Misunderstanding immutability for container/git tags and Helm charts
This is not an anti-pattern with Argo CD per se, but it is closely related to the targetRevision choices, as explained in the previous anti-pattern.
We have seen several cases of people adopting Argo CD without first understanding the foundations (Helm, container registries, git tags). Several times, people use a specific git tag or Helm version in Argo CD without realizing that:
- Git tags seem to be immutable, but can be deleted and recreated with the same name
- Helm chart versions are mutable. This is how Helm was designed
- Container tags are mutable by default.
Let’s take these points one by one.
Container tags are mutable. You can create a container called my-app:v1.2 and then change something and push another container with the same tag. So just because you see the same container tag doesn’t mean that it is actually the same application. Some binary repository implementations don’t allow you to do this, but this is not always the default setting.
Helm chart versions are also mutable. You can change the contents of a Chart version and use the exact same version. Again, this is how Helm charts are created.

In fact Helm offers an additional property – the appVersion which can store the “application” version. So you can have a Helm chart with 3 “version” fields:
- The container image (mutable by default)
- The appVersion field (mutable)
- The Chart version (mutable)
So unless you control how developers work with code and manifests and also configure your Helm chart repository correctly, you don’t really know if a Helm chart version contains the same thing as another chart with the same version.
Git tags can also be overwritten. You can see this very easily with any GitHub repo with default settings.
git tag -a v1.2 -m "first tag" git push --tags echo "A change" >> README.md git tag -d v1.2 git push origin :v1.2 git tag -a v1.2 -m "first tag" git push --tags
Here we just pushed the same tag (v1.2) twice but with different contents. So if you were using this tag in the targetRevision field of Argo CD, you now have the “same” application without actually having the same contents.
The end result is that using tags and Helm chart versions in Argo CD doesn’t really restrict your developers unless you actively set up the rest of the ecosystem (Git repositories, Helm repos and binary artifact managers) to also work with immutable data.
Never assume you have a “locked-down” Argo CD system when the rest of the ecosystem allows developers and operators to create stuff with the same container/Helm/Git version.
Anti-pattern 13 – Giving too much power (or no power at all) to developers
When adopting Argo CD you need to make a decision about how much power and exposure you want to give to developers. On one end of the spectrum we see installations where developers have full access to the Argo CD UI and can sync/deploy their applications at will. On the other end we see locked down installations where developers are given very little power or Argo CD is completely hidden from them.
It is important to understand that despite these two extremes, there are several choices in the middle. First, you can configure the Argo CD access (and UI) to show only applications specific to each team. You can even do advanced scenarios where you show applications from other teams but in a read-only mode.
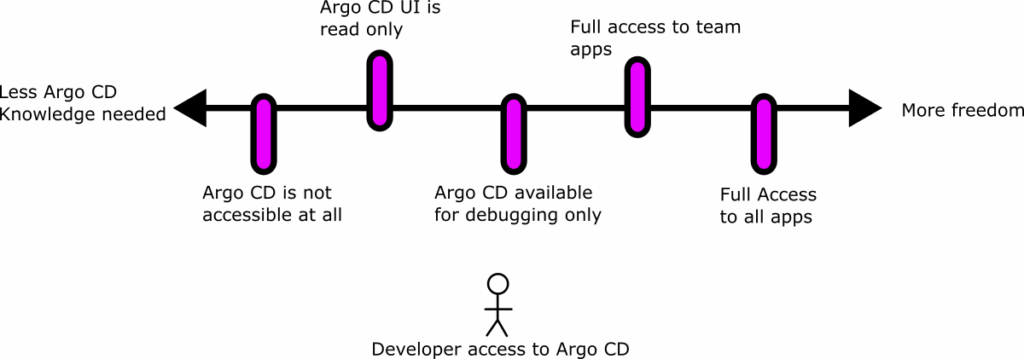
In our Argo CD RBAC guide, we have explained how the RBAC for Argo CD works and how you can show content specific only to a developer team.
There is no right or wrong answer here, but you need to balance the flexibility versus the security that you want to offer to developers.
On a related note we have already explained that developers don’t really care about Argo CD manifests and they shouldn’t also be forced to install Argo CD for local testing (see anti-pattern 6) .
So a recommended workflow would be the following:
- Developers can test and deploy their applications locally without using Argo CD at all
- When they have created a feature branch this should be converted to a preview/temporary environment using the Pull Request generator without any human intervention
- Once the feature is ready, it will be deployed to production simply by merging the Pull request
- A system designed for promotion should propagate the changes to the next environment (check anti-pattern 30).
Ideally developers should only come in contact with Argo CD in the last phase and only in the case of a failure. In the happy path scenario where everything works as planned, developers shouldn’t have to debug anything with Argo CD.
Anti-pattern 14 – Referencing dynamic information from Argo CD/ Kubernetes manifests
This is a more specialized anti-pattern related to number 2 (creating applications in a dynamic way). The second GitOps principle explains that the desired state of your system should be immutable, versionable and auditable.
This is only true if you store EVERYTHING that the application needs in Git (or your chosen storage method). In the case of Kubernetes/Argo CD manifests, this means that all values used should be static and known in advance.
It is ok if you want to post-process your manifests in some way as long as this happens in a repeatable manner OR you also save the result itself in Git.
The problem starts when your configuration is not known in advance but requires real-time access to something else.
The best example to illustrate this is the Helm lookup method which mutates the Helm chart to a different value without knowing in advance what this value is. This is problematic with Argo CD because having access to just the application manifests is not enough to run the application anymore.
Like anti-patterns 17 and 20 this also makes lives difficult for developers as they cannot run the application locally anymore (anti-pattern 6).
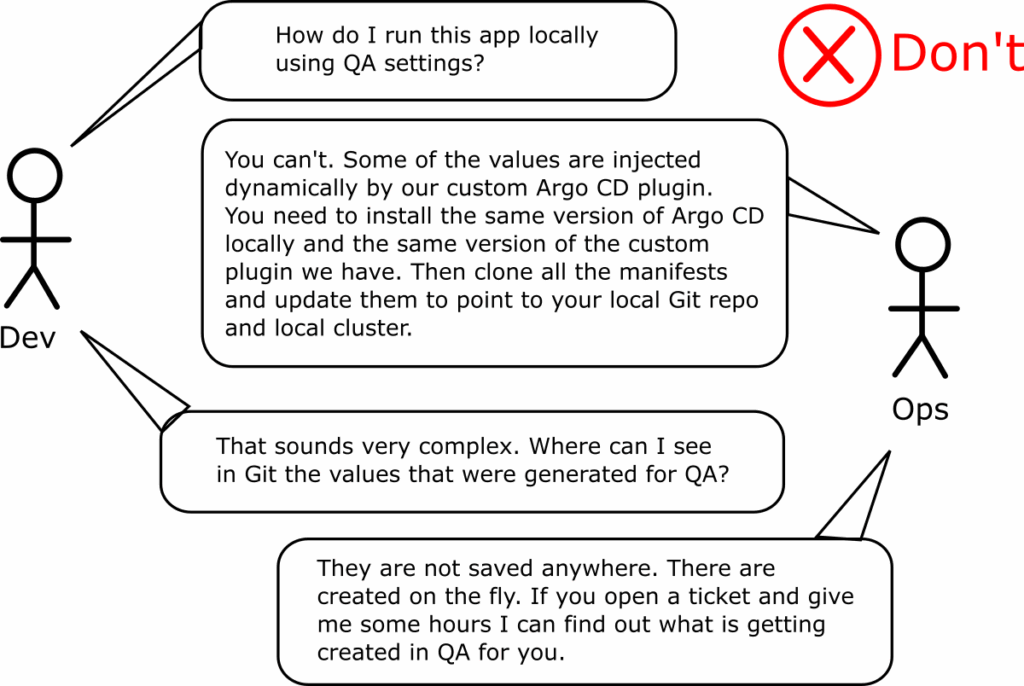
Note that the only exception to this rule is secrets. Even though you can store encrypted secrets in Git, it is also ok to reference them from an external source.
But make sure to understand the difference between referencing secrets from manifests versus injecting secrets into manifests.
Anti-pattern 15 – Writing applications instead of Application Sets
The Application CRD is the main entity in Argo CD that links a cluster and a GitHub repository. If you have a small number of applications or work in a homelab environment it is OK to write these files by hand.
But for any production installation of Argo CD (used in a company) you generally wouldn’t need to write Application files by hand. In fact you should not even deal with Application files at all.
The recommendation is to use directly Application Sets.
In a big organization you will rarely have to deal with a single application on its own. Almost always you want to work with a group of applications. Some examples are:
- A set of applications that go to the same cluster
- A set of applications that are managed by the same team
- A set of applications that share a configuration
- A set of applications that should be deployed/updated as a unit.
Application Sets implement this grouping and also automate the tedious YAML needed. For example if you have 4 applications and 10 clusters you don’t really want to create 40 YAML files by hand.
- You create a single cluster generator that iterates over your clusters
- You create 4 folders for the 4 applications
- The Application set runs and creates automatically all 40 combinations for you.
Some people resist using Application Sets because they think it is yet another abstraction that hides their real Application manifests.
This used to be true, but in the latest Argo CD releases the CLI allows you to render an application set and see exactly what applications will be created. You can run this command either manually or in a CI pipeline (when a pull request is created) so that you have instant visibility on what will change.
In general though, as we will see later all application set files should be created only once.They are not a deployment format (anti-pattern 19) and you shouldn’t have to edit ApplicationSets for simple operations.
We have written a dedicated guide on how to use Application Sets with Argo CD.
Anti-pattern 16 – Using Helm to package Applications instead of Application Sets
This anti-pattern is the so called “Helm sandwich”. This is the case where:
- A set of Kubernetes manifests is packaged as a Helm chart
- The Helm chart is referenced from an Argo CD application Manifest
- The Argo CD application manifest itself is packaged in another Helm chart
Essentially, there are two instances of Helm templating on two different levels.
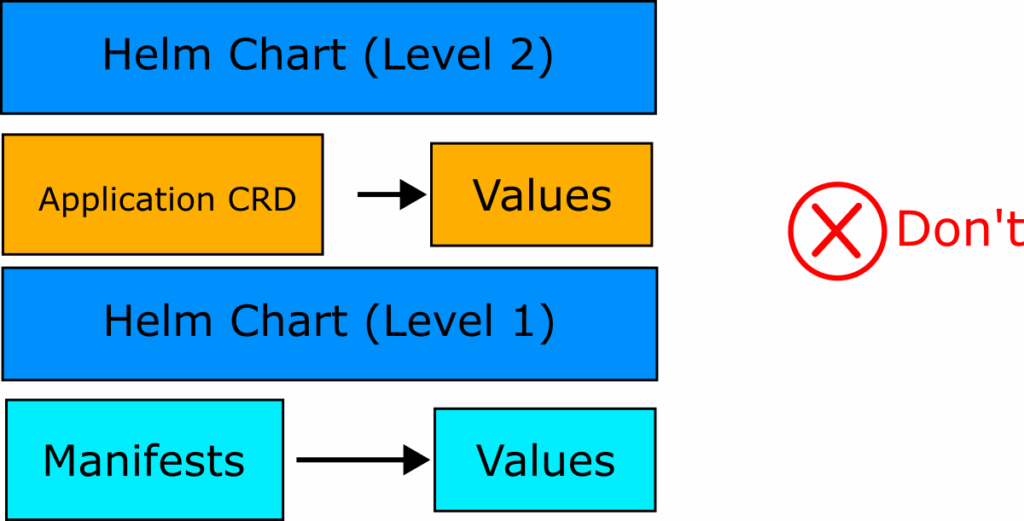
Teams that adopt this anti-pattern are familiar with Helm and assume that if it works great for plain Kubernetes manifests, it would also work great for Argo CD application manifests.
So why is this approach an anti-pattern? Using Helm for applications is not an issue on its own, but it is the start for several other anti-patterns:
- Because Helm charts have a version people try to version Applications -> Anti-pattern 19
- Chart version numbers often result in abusing target Revision for promotions -> Anti-pattern 11
- If you use Helm everywhere it is super easy to hard-code Helm values in Application manifests -> Anti-pattern 17
- People miss all the Argo CD specific features of application sets -> Anti-pattern 15
- Distributing applications to different clusters happens with snowflake servers instead of the cluster generator -> Anti-pattern 21
The biggest problem however is that it ruins again completely the developer experience. You now have 2 levels of Helm values and this is a recipe for disaster:

Even speaking for just operators/admins, packaging applications in a Helm chart creates an extra level of indirection that not only is not needed but makes your life more difficult as Argo CD was never created for this “Helm sandwich”.

Our recommendation is obviously to use Application Sets for configuring Applications, as already explained in the previous anti-pattern.
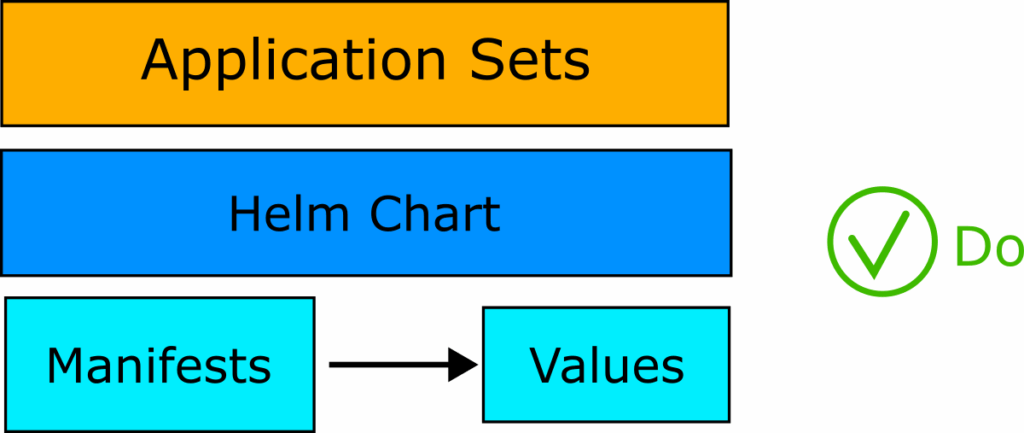
Application Sets are the preferred way to generate Applications and they support the exact same templating functions as Helm charts. Basically if you can template it with Helm, you should be able to template it with Application Sets.

Using the “Helm sandwich” pattern makes the process more complex for everybody involved in the software lifecycle.
For more information, see our Application Set guide.
Anti-pattern 17 – Hardcoding Helm data inside Argo CD applications
If you follow the advice we outlined in Antipattern 4 you should have a clear separation between your Helm charts and your Argo CD manifests.
The Helm charts can be used independently (even by developers) and contain all application settings. The Argo CD application manifest simply defines where this application runs, and only operators need to change this file.
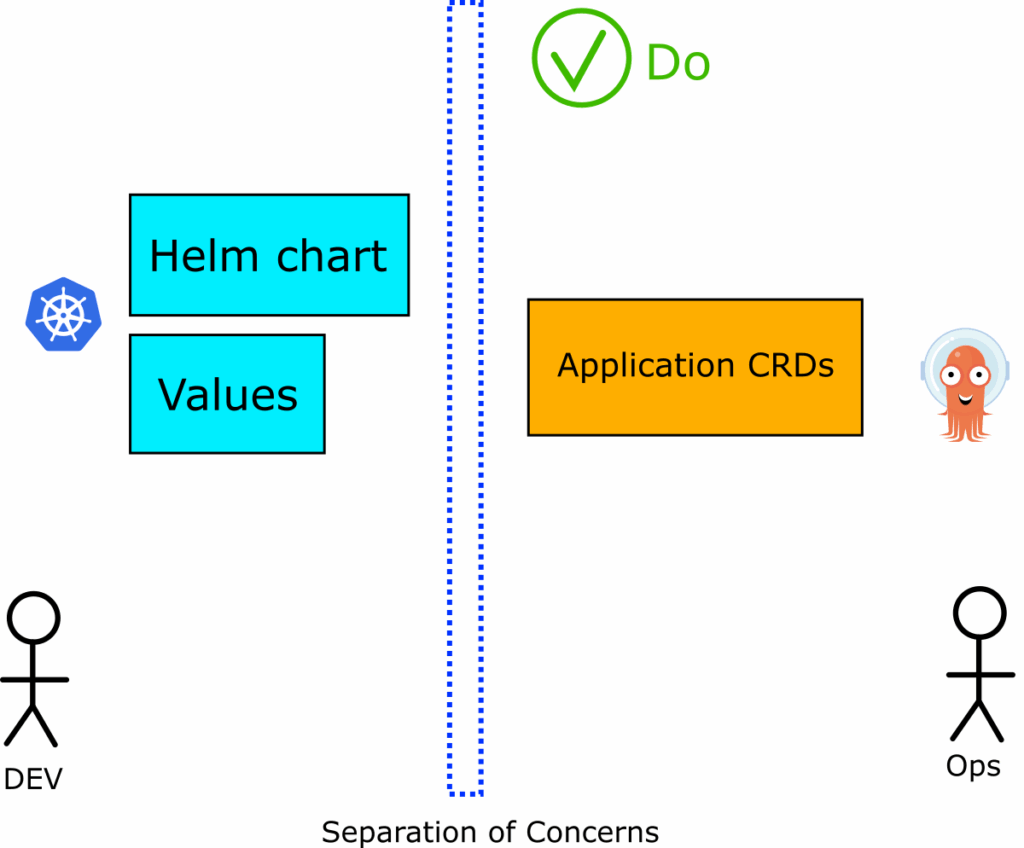
Those two kinds of files also have a different lifecycle
- Helm values are expected to change all the time (even by developers)
- Argo CD application manifests are created once and never changed again.
With Argo CD it is possible to hardcode Helm information inside an Application CRD. But just because you can do this, doesn’t mean it is a good idea to use this feature.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-helm-override
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/example-org/example-repo.git
targetRevision: HEAD
path: my-chart
helm:
# DONT DO THIS
parameters:
- name: "my-example-setting-1"
value: my-value1
- name: "my-example-setting-2"
value: "my-value2"
forceString: true # ensures that value is treated as a string
# DONT DO THIS
values: |
ingress:
enabled: true
path: /
hosts:
- mydomain.example.com
# DONT DO THIS
valuesObject:
image:
repository: docker.io/example/my-app
tag: 0.1
pullPolicy: IfNotPresent
destination:
server: https://kubernetes.default.svc
namespace: my-app
The big problem with this file is that you are mixing 2 different kinds of information with 2 different lifecycles. The application CRD is something that is interesting mostly to operators/administrators while Helm information is interesting to developers and is also expected to change a lot.
By mixing this information you make manifests harder to understand for everybody.
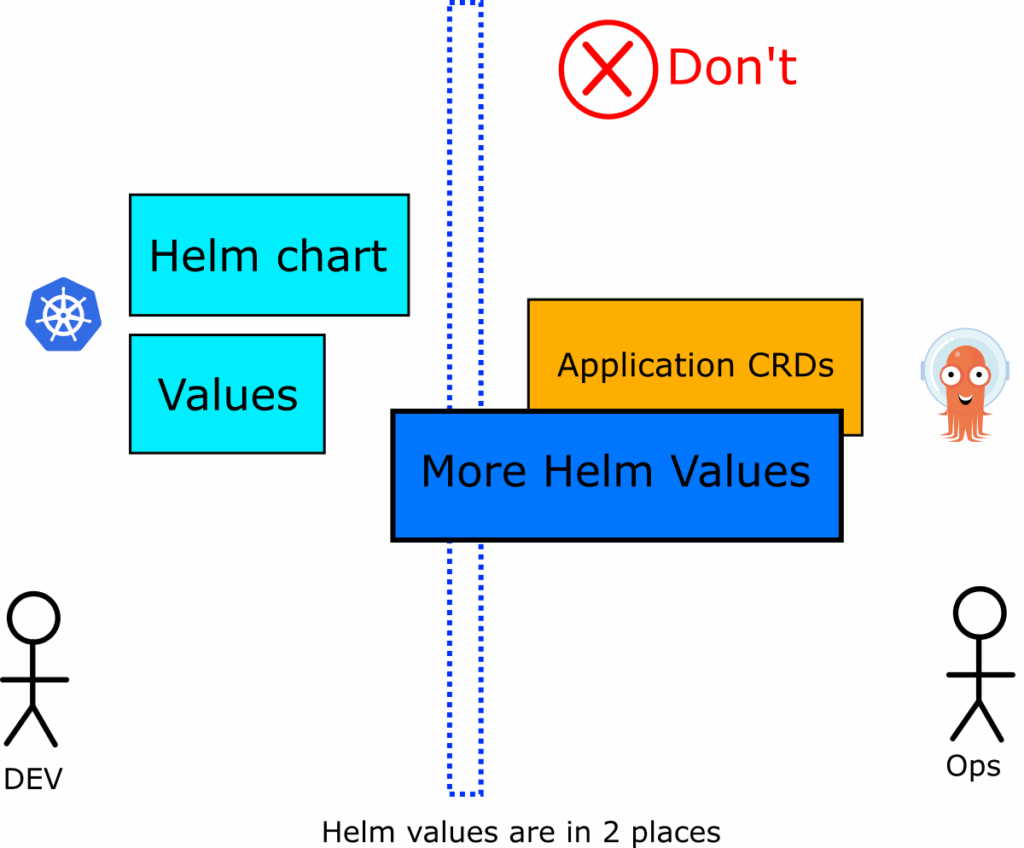
Now you have Helm information in two places (helm values and the helm property inside the Argo CD application manifest). It is very hard to understand what settings exist where and how to audit deployment history. Argo CD application manifests now must also change all the time especially if they define container images.
This manifest mixing is also the root of several other anti-patterns such as
- Using Applications as a unit of work (anti-pattern 19)
- Abusing the targetRevision field for promotions (anti-pattern 11)
- Not understanding how Helm hierarchy works (anti-pattern 4)
- Assuming that developers need Argo CD (anti-pattern 6)
The last point is especially important for developers. If you follow this practice, you have completely destroyed local testing for developers as they cannot run the application on its own anymore.

Even though we speak only about developers and operators here, several other scenarios will make this approach difficult to use
- Security teams will have a hard time understanding the settings for each application
- Your CI system cannot upgrade images just on Kubernetes manifests anymore. It also needs to look at Argo CD manifests and check if image definitions exist there as well
- It couples your Applications to specific Argo CD features
The correct solution is of course to store all Helm information in Helm values
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-helm-override
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/example-org/example-repo.git
targetRevision: HEAD
path: my-chart
helm:
## DO THIS (values in Git on their own)
valueFiles:
- values-production.yaml
destination:
server: https://kubernetes.default.svc
namespace: my-app
Now there is a clear separation of concern between developers and operators.
People who want to know applications’ settings can look at Helm values, while people who want to know where applications are deployed can look at Argo CD manifests. It is possible to run a Helm application without Argo CD.
For more information about the different types of manifests and how to split them see our Application Set guide.
This anti-pattern is even worse if coupled with the previous anti-pattern (the Helm sandwich).
Now you have 3 places where configuration settings can be stored:
- The Helm values of the chart that gets deployed
- The helm property inside the Application Manifest that references the Helm chart
- The Helm template that renders the Application manifest before getting passed to Argo CD
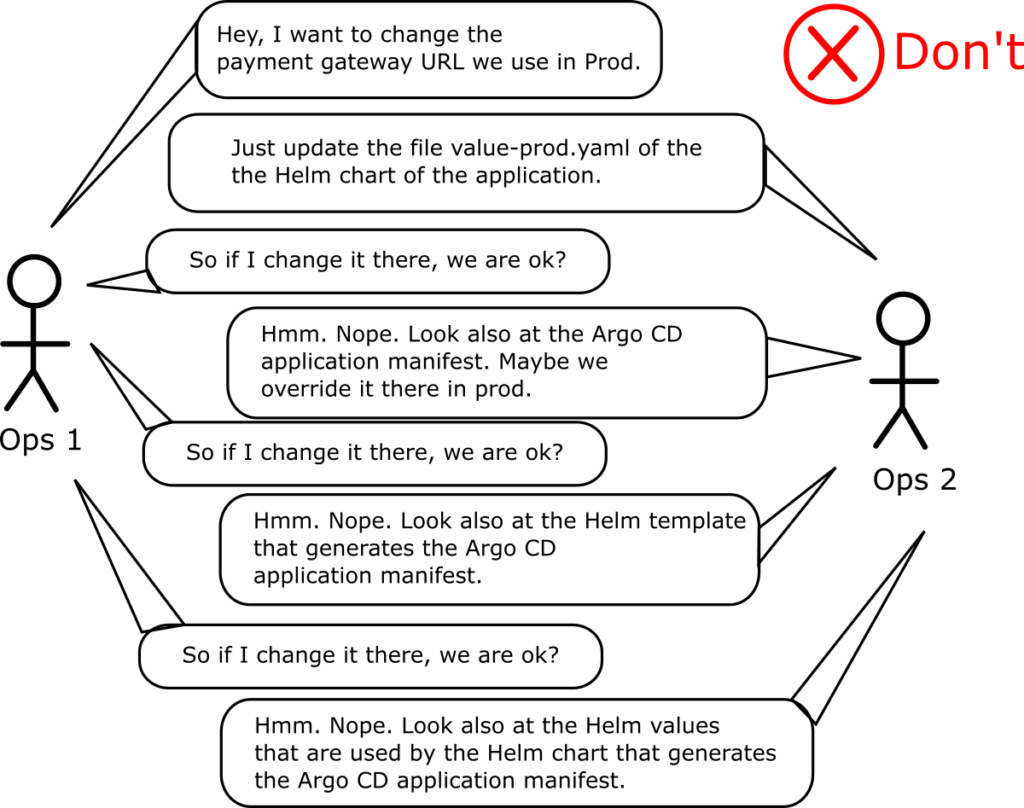
The result is a nightmare for anybody who wants to understand how an application gets deployed.
Anti-pattern 18 – Hardcoding Kustomize data inside Argo CD applications
This is the same anti-pattern as the previous one but for Kustomize. Again for convenience Argo CD allows you to hardcode Kustomize information inside an Application YAML:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-kustomize-override
namespace: argocd
spec:
source:
repoURL: https://github.com/example-org/example-repo.git
targetRevision: HEAD
path: my-app
# DONT DO THIS
kustomize:
namePrefix: prod-
images:
- docker.io/example/my-app:0.2
namespace: custom-namespace
destination:
server: https://kubernetes.default.svc
namespace: my-app
It is the same problem as before where you are mixing different concerns in a single file. Kustomize information should only exist in Kustomize overlays:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-proper-kustomize-app
namespace: argocd
spec:
source:
repoURL: https://github.com/example-org/example-repo.git
targetRevision: HEAD
## DO THIS. Save all values in the Kustomize Overlay itself
path: my-app/overlays/prod
destination:
server: https://kubernetes.default.svc
namespace: my-app
As explained before this helps developers during local testing. A developer can simply run “kustomize build my-app/overlays/prod” and get the full configuration of how my-app runs in production. No knowledge of Argo CD is required and no local installation of Argo CD is needed.

Developers can define how an application runs (its settings), while operators can decide where (which cluster) the application is deployed.
At the same time, several supporting functions are very easy:
- Git history of the overlays is the same as the deployment history
- There is only a single source of truth for configuration (the overlays)
- Developers don’t need to know how to use Argo CD at all
- It is very easy to diff settings between environments.
A detailed example with Kustomize overlays is available in our GitOps promotion guide.
Anti-pattern 19 – Attempting to version and promote Applications/Application Sets
An Argo CD application is just a link between a cluster and a Git repository. There is NO version field in the Application CRD. An application manifest is neither a packaging format nor a deployment artifact. The same is also true for Application Sets. You never deploy application sets. You just use them to auto-generate application manifests. Application Sets have no version on their own.
The lack of a version field is not a big problem because the expectation for both Applications and Application Sets is that you create them once and then never update them again. So, a version field is unnecessary as all Argo CD Applications are considered static.
However, we see several teams that try to use Applications as the unit of work (see anti-pattern 7) or continuously update those files in the targetRevision field (see anti-pattern 11).
At this point teams try to create their own versioning on top of the Argo CD manifests and of course they fail because Argo CD was never designed this way.
The same is true for promotions. You cannot really “promote” an Argo CD application from one cluster to the next. It doesn’t work this way. You can only promote values that are referenced from one application to the next (essentially copying them).
The way promotions work in Argo CD is the following:
- There is an Argo CD application manifest in QA that points to a Helm chart or Kustomize overlay
- There is an Argo CD application manifest in Staging that points to different Helm values or Kustomize overlays
- When it is time to promote you copy the Helm values or Kustomize overlay from the QA files to the Staging files.
- The Argo CD application manifests are not affected in any way. They are exactly the same as they were before.
See also the related anti-patterns of hardcoding Helm (anti-pattern 17) or Kustomize data (anti-pattern 18) inside applications.
If you find yourself constantly updating Argo CD application manifests (or Application Sets) you have fallen into this trap. Your Argo CD manifests should be created only once and never touched again. No process is simpler than not needing a process at all (to update Application manifests).
On a related note, we have created GitOps Cloud to solve this problem with promotions and allow you to promote applications from one cluster to another.
Anti-pattern 20 – Not understanding what changes are applied to a cluster
One of the main benefits of using Argo CD is that all your Git tools work out of the box and you can reuse your code review process for your Kubernetes manifests.
The most basic capability of storing anything in GitHub is creating a Pull Request before merging any changes. This allows humans to review what will change and also run any automated tools to verify and validate the changes.
Unfortunately this review process will not really work on files such as Helm charts or Application Sets or Kustomize Overlays. Let’s assume you need to review the following change:

You need to manually run Helm in your head to understand what is happening here. Humans never want to do that. Obviously one approach would be to pre-render all your manifests so that reviews only happen in the final content. There are however several alternatives that you can consider such as having your CI system render on the fly the manifests and show you what will actually happen.
Here is the exact change as before but this time on the final chart.
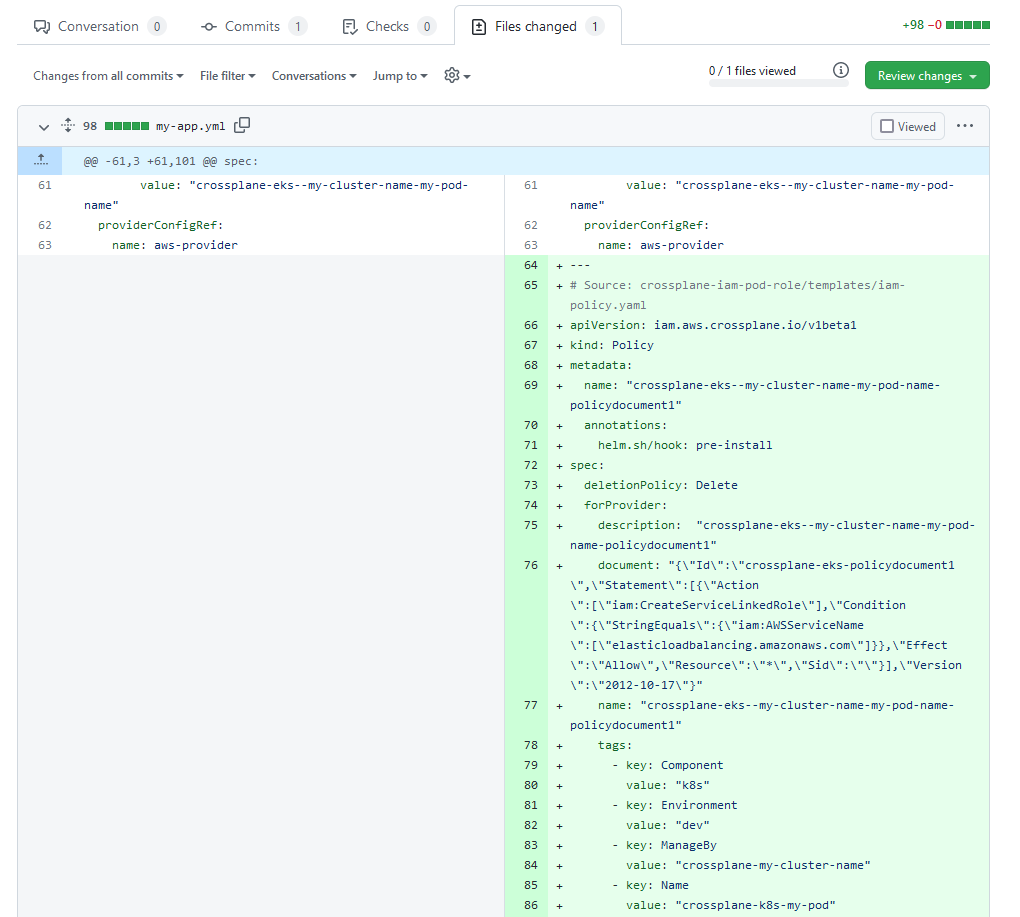
We have written a full guide on how to preview and diff your Kubernetes manifests with several other approaches.
Specifically for Argo CD you should also check https://github.com/dag-andersen/argocd-diff-preview and also understand that you can use the Argo CD CLI to render your Application Sets to Application CRDs.
Anti-pattern 21 – Using ad-hoc clusters instead of cluster labels
If you have a large number of clusters that you wish to manage with Argo CD, your first question is always whether to use a single Argo CD instance or multiple ones.
Once you answer this question the next step is to understand how you can distribute different applications to different clusters. The answer for this question is Application Sets.
Unfortunately we see a lot of teams that don’t understand how the cluster generator works and instead try to create ad-hoc cluster configurations (the pet vs cattle philosophy).
Examples to avoid often appear like this:
## DO NOT DO THIS
- merge:
mergeKeys:
- app
generators:
- list:
elements:
- app: external-dns
appPath: infra/helm-charts/external-dns
namespace: dns
- app: argocd
appPath: infra/helm-charts/argocd
namespace: argocd
- app: external-secrets
appPath: infra/helm-charts/external-secrets
namespace: external-secrets
- app: kyverno
appPath: infra/helm-charts/kyverno
namespace: kyverno
- list:
elements:
- app: external-dns
enabled: "true"
- app: argocd
enabled: "true"
- app: external-secrets
enabled: "false"
- app: kyverno
enabled: "true"
selector:
matchLabels:
enabled: "true"
Or this
## DO NOT DO THIS
Version: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: my-staging-cluster
namespace: argocd
spec:
goTemplate: true
generators:
- matrix:
generators:
- git:
repoURL: '<url>'
revision: HEAD
files:
- path: customConfig/base.yaml
- path: customConfig/{{ .Values.domainId }}/*.yaml
- list:
elements:
- appName: 'auth'
- appName: 'search'
- appName: ‘billing’
- appName: ‘payments’
These kind of configurations create snowflake servers that need constant maintenance. If you have fallen into this trap try to understand how much time you will need to spend in the following scenarios:
- Creating a brand new server
- Migrating an application from one server to another
- Applying a global setting to all your servers
- Making a different configuration change for a subset of your servers.
This kind of cluster management is even more problematic for developers, as simply understanding what applications are deployed where is not easy (already explained in anti-pattern 6).
Our recommendation is to create a production-ready setup using cluster labels. We have described all the details in a dedicated guide for the cluster generator and Argo CD application sets.
Anti-pattern 22 – Attempting to use a single application set for everything
A related anti-pattern is when teams discover application sets and, for some unknown reason, try to cram all their applications into a single application set. This often results in a complex mix of different generators that is hard to understand and hard to debug.

The recommendation is to have many different application sets in your Argo CD setup. Ideally, you should have different application sets per “type” of application. This type can be anything that makes sense to you. For example:
- An application set for all staging apps
- An application set for all AWS clusters
- An application set for all infra apps
- An application set for the billing team
- An application set for the payments team
You can slice and dice your applications in different dimensions. But in the end, you will have many application sets, and any time you make a change, you should instantly know where it should happen.
- A new requirement is that all AWS clusters need to get sealed secrets -> Change the AWS application set.
- A new requirement is that the billing team add a new microservice to their setup -> Change the “billing” application set.
- All new clusters must upgrade Prometheus -> Change the “common” application set.
There is no technical limitation on the number of application sets you can have on a single Argo CD installation. So, spend some time understanding your application sets accordingly.
As always, our Argo CD application guide is the best starting point.
Anti-pattern 23 – Using Pre-sync hooks for db migrations
Argo CD phases/waves allow you to define the order of Resources synced within a single Argo CD application. The pre-sync phase, in particular, can be used to check deployment requirements or perform other checks that need to happen before the main sync phase.
We often see organizations attempting to use pre-sync hooks for database migrations. The assumption here is that the database schema must be updated just before the new application version. Unfortunately, most organizations use legacy DB migration tools, and almost always, they package a DB migration CLI tool in the pre-sync phase, which is not the proper approach for Kubernetes applications.
Using pre-sync hooks for database migrations has several issues. The most important one is that the DB CLI tool is just a black box for Argo CD. The CLI runs and never reports back to Argo CD what really happened with the database. This can leave the DB in an inconsistent state where the main sync phase will always fail.
The second problem is that Argo CD is based on continuous reconciliation, where an application might be synced for several reasons and in different time frames. Unfortunately the traditional DB CLI tools are rarely created with this scenario in mind. Most times they assume they run inside a typical CI pipeline only once.
At this point, Argo CD users are looking for several hacks to force the pre-sync hook to run ONLY in the initial application deployment and not in any subsequent sync events, as this either slows down the deployment or breaks the database completely.
The correct approach is to use a Database migration operator built specifically for Kubernetes. We have written a full guide using the AtlasGo DB operator.
Anti-pattern 24 – Mixing Infrastructure apps with developer workloads
We have seen in anti-pattern 7 several ways to group applications with GitOps (applicationsets, apps-of-apps, Helm umbrella charts).
These grouping methods should always be used for the same types of applications. They should group either infra applications (core-dns, nginx, prometheus) OR the applications that developers create.
You should never mix applications of different types as you force developers to deal with infrastructure errors.

When you create a new cluster and hand it over to developers, it should already have everything they need. The respective application sets should also have installed any infrastructure applications.
Mixing both infrastructure and developer applications might be easier for you (to control directly the deployment order) but always results in a bad user experience for developers.
If developers have access to the Argo CD UI and see a deployment error, they should know immediately that it is something they can fix themselves.
Anti-pattern 25 – Misusing Argo CD finalizers
Argo CD finalizers allow you to define what happens when an Argo CD application (or application set) is removed. You must understand how finalizers work and the impact of adding/removing a finalizer from a resource.
Several teams have accidentally deleted one or more Argo CD applications because they never understood how finalizers work. Other times several resources are “stuck” and never recreated because of a misconfiguration with finalizers.
Finalizers are also very useful when you want to migrate applications from one Argo CD instance to another.
We have written a comprehensive guide about Argo CD finalizers and how to use them.
Anti-pattern 26 – Not understanding resource tracking
This anti-pattern is related to the previous one. First of all it is important to understand how Argo CD tracks and “adopts” Kubernetes resources. You can have Kubernetes resources that are not managed by Argo CD, or Argo CD resources that “owned” by other Kubernetes controllers.
It is vital to know that the relationship between a Kubernetes resource and the Argo CD application that owns it is not always 1-1. You can have
- Argo CD applications that no longer contain any Kubernetes resources
- Kubernetes resources that are no longer owned by an Argo CD application
The second scenario is achieved with finalizers. This pattern is very useful when you want to migrate applications from one Argo CD instance to another without downtime. The full process is the following:
- Argo CD instance A owns all Kubernetes resources
- You remove all finalizers for all applications (and application Sets)
- You delete all Argo CD applications
- The Kubernetes resources are still running just fine. There is no downtime
- You apply the same Argo CD applications to Argo CD instance B
- Argo CD instance B will adopt the same Kubernetes resources as before (with no downtime)
You can try this exact scenario of moving Argo CD applications between instances without downtime in our Gitops Certification (level 3) course.
The exact process can be used to upgrade an existing Argo CD instance to a new version in the safest way possible.
Anti-pattern 27 – Creating “active-active” installations of Argo CD
This is the corollary to the previous two anti-patterns. We see several several teams that try to create “active-active” installations of Argo CD with the following requirement:
- The main Argo CD instance is controlling all applications and deployments
- There is a secondary Argo CD instance that is also pointed to the same cluster
- If the main Argo CD instance “fails” the secondary instance “jumps-in”
- When the main Argo CD instance is restored it “adopts” again all applications.
These teams are disappointed to learn that Argo CD doesn’t support this and even the centralized mode is for controlling other Kubernetes clusters and not other Argo CD instances.
This requirement doesn’t really make sense for Argo CD and teams that look for this “active-active” configuration haven’t really understood resource tracking.
First of all it is important to understand that Argo CD only deploys applications. It doesn’t really control them. If Argo CD fails, new deployments will stop but existing applications will continue to work just fine. And even if those fail for some reason, their pods will be rescheduled/restarted by the Kubernetes cluster (even if Argo CD is no longer operational).
The disaster recovery scenario for Argo CD is straightforward if your team has everything in Git (see antipattern 1). You can launch a second Argo CD cluster and point it to the same application manifests. Argo CD will then adopt the existing Kubernetes resources.
This is even possible if the central Argo CD instance has issues but still runs, as you can use finalizers (as explained in the previous section) to migrate applications to the second Argo CD instance without downtime.
Keeping a second Argo CD instance in “active-active” mode only wastes resources.
Anti-pattern 28 – Recreating Argo Rollouts with Argo CD and duct tape
Bad deployments always happen regardless of whether you are using Argo CD or not. That is a fact for any software team. So how do failed deployments work if you have adopted GitOps?
The simplest way to fix a failed deployment is to roll “forward”. Make a new release or fix the Kubernetes manifests and once you commit, Argo CD will deploy the new changes and hopefully bring back the application to a good state.
Argo CD also includes a “rollback” command which simply points the application back to a previous Git hash. This sounds great in theory but it has 2 major problems:
- It works only if auto-sync is disabled (anti-pattern 10)
- It breaks GitOps as your cluster doesn’t represent what is in Git anymore
At this point, teams start creating custom solutions to overcome these limitations. The most common approaches we see are:
- Trying to detect a failed deployment, and then disable auto-sync on the fly while rolling back
- Using notifications with external metric providers who will automatically try to revert a commit on their own, so Argo CD will sync as usual to the previous version
These custom solutions are always clunky and create more problems than they solve. You know that your team is falling into this trap if you hear people always asking the question, “How can I disable auto-sync temporarily?”
The recommended solution is to use Argo Rollouts.
Argo Rollouts is a progressive Delivery controller designed for this exact scenario—automated rollbacks when things go wrong. It also comes with its own resource (Analysis) that allows you to look at your metrics during a deployment and roll back without any human intervention.
Argo Rollouts will handle production deployments while non-production environments can still use plain Argo CD.
Anti-pattern 29 – Recreating Argo Workflows with Argo CD, sync-waves and duct tape
The sync wave feature of Argo CD allows you to execute tasks before and after the main sync phase. These tasks should ideally be idempotent and quick to finish. Some examples are:
- Sending a notification to another system
- Performing a quick smoke test
- Verifying that a dependency exists
We see teams that misuse the sync waves in Argo CD with long-running tasks that are part of a bigger process with strict requirements such as
- Automatic retries
- If/else control flows
- Dependency graphs and fan-in/fan-out configuration
- Artifact storage are retrieval
Sync waves were NEVER designed for this kind of requirement. If you try to do this, you will soon resort to custom scripts that nobody wants to maintain. Adopting Argo CD for deployments and then trying to incorporate custom scripts in the sync process is a huge step backwards.
If you have this kind of process you should use Argo Workflows which handle exactly these kinds of requirements.
Argo Workflows are Kubernetes native workflows that offer you all these features out of the box.
Therefore the whole sync process must be:
- Run an Argo Workflow before the sync process
- Perform the main Sync phase
- Run another Argo Workflow after the sync process.

Argo Workflows will then handle all the heavy lifting using declarative Kubernetes resources instead of custom scripts.
Anti-pattern 30 – Abusing Argo CD as a full SDLC platform
Despite all the features and the developer-friendly UI, Argo CD is very simple at its core. It is a powerful sync engine that continuously watches what you have in Git and applies the change to your cluster. All the features are centered around this use case.
However, deploying an application is only part of the software development life cycle (SDLC). Several other requirements must be met before (the CI process) and after (observability) the main deployment.
We have seen several teams trying to expand Argo CD’s scope and make it something it never was. Most importantly, Argo CD has no visibility in your Continuous Integration (CI) process. Argo CD doesn’t know:
- What are the new features in the container that gets deployed
- Who made the container build
- If the application has passed your unit and integration tests
- If your new container has passed your security scans
- Who approved the Pull request of the source code change
In fact, Argo CD doesn’t even know that it deploys a new container that includes commits from a source code repo. All it knows is diffing and applying Kubernetes manifests without any insights about the business features behind.
Attempting to integrate this information into Argo CD either through custom plugins or custom YAML segments is always a clunky process. We understand the need for a unified interface. Developer teams love the Argo CD UI and think they can use it as a central dashboard for everything.
That is not the role of Argo CD. You can create a developer portal that uses Argo CD behind the scenes, but Argo CD is not a developer portal itself.
If you want to use a central platform for all your Argo CD instances that also combines deployment information with the CI world, check out Codefresh GitOps cloud.
Conclusion
We hope this comprehensive guide is useful and has provided several good and bad practices when adopting GitOps. Argo CD is a great tool, but it offers several knobs and switches that can be used with undesirable results.
Some features can be abused in several ways, simply because no good documentation exists about the history of the feature, what the intended use is, and what to avoid.
Using this guide you can start your Argo CD journey in the best way possible as you now have the knowledge of what to avoid before investing a significant amount of effort into your Application manifests.
Here is a summary of all the anti-patterns and our recommendation:
- Not understanding the declarative setup of Argo CD -> Store Application CRDs in Git.
- Creating dynamic Argo CD applications -> Use Git as the single source of truth for application configuration.
- Using Argo CD parameters -> Avoid using the parameters feature as it goes against GitOps principles.
- Adopting Argo CD without understanding Helm -> Understand how Helm works independently before adopting Argo CD.
- Adopting Argo CD without understanding Kustomize -> Ensure your Kustomize files work on their own before integrating with Argo CD.
- Assuming that developers need to know about Argo CD -> Design your Argo CD applications so developers can recreate configurations without Argo CD knowledge.
- Grouping applications at the wrong abstraction level -> Use Application Sets or app-of-apps pattern for proper application grouping.
- Abusing the multi-source feature of Argo CD -> Use multi-source as a last resort and only for edge case scenarios.
- Not splitting the different Git repositories -> Separate source code, Kubernetes manifests, and Argo CD application manifests into different Git repositories.
- Disabling auto-sync and self-heal -> Keep auto-sync/self-heal enabled for all systems, including production.
- Abusing the targetRevision field -> Always use HEAD in the targetRevision field.
- Misunderstanding immutability for container/git tags and Helm charts -> Actively set up the ecosystem (Git, Helm repos, artifact managers) to work with immutable data.
- Giving too much power (or no power at all) to developers -> Balance flexibility and security with Argo CD RBAC, and enable local testing without Argo CD.
- Referencing dynamic information from Argo CD/ Kubernetes manifests -> Store all values used in manifests statically in Git.
- Writing applications instead of Application Sets -> Use Application Sets to automate the creation of Application files.
- Using Helm to package Applications instead of Application Sets -> Learn how Application Sets work and their features.
- Hardcoding Helm data inside Argo CD applications -> Store all Helm information in Helm values, separate from Argo CD manifests.
- Hardcoding Kustomize data inside Argo CD applications -> Store Kustomize information only in Kustomize overlays separate from Argo CD manifests
- Attempting to version and promote Applications/Application Sets -> Promote values or overlays, not Application manifests themselves.
- Not understanding what changes are applied to a cluster -> Use tools or CI systems to preview and diff rendered Kubernetes manifests.
- Using ad-hoc clusters instead of cluster labels -> Use cluster labels and Application Sets to distribute applications to different clusters.
- Attempting to use a single application set for everything -> Have many different Application Sets, each with a different purpose/scope.
- Using Pre-sync hooks for db migrations -> Use a Database migration operator explicitly built for Kubernetes.
- Mixing Infrastructure apps with developer workloads -> Separate infrastructure applications from developer workloads.
- Misusing Argo CD finalizers -> Understand how finalizers work and use them correctly for application deletion and migration.
- Not understanding resource tracking -> Understand how Argo CD tracks and adopts Kubernetes resources.
- Creating “active-active” installations of Argo CD -> Avoid active-active setups, rely on Git and resource tracking for disaster recovery.
- Recreating Argo Rollouts with Argo CD and duct tape -> Use Argo Rollouts for progressive delivery and automated rollbacks.
- Recreating Argo Workflows with Argo CD, sync-waves and duct tape -> Use Argo Workflows for long-running tasks and complex process orchestration.
- Abusing Argo CD as a full SDLC platform -> Use a different system as a developer portal or promotion orchestrator.
Let us know in the comment section if we have missed any other questionable practices!
Happy deployments!