Article Content
A microservices architecture is a new way to design software applications, which has been broadly adopted by the software development community. Unlike traditional architectural styles that treated software as a single, monolithic unit, microservices architectures are based on a modular approach. Microservices are lightweight, loosely coupled modules that perform specific functions, and are easier to develop, manage, and update.
Microservices applications divide software into components that are replaceable and independently upgradeable. Each microservice might use different programming languages, dependencies, or hardware, giving development teams tremendous flexibility. Microservices communicate over a network, typically using universal protocols such as REST APIs, which are agnostic to the underlying technology. This makes them loosely coupled, making it possible to replace or rebuild a component without affecting the rest of the application.
Microservices Architecture and DevOps
Microservices architectures provide better support for Continuous Integration/Continuous Delivery (CI/CD) and DevOps workflows than monolithic architectures. Small, frequently deployed services enable fast, flexible development pipelines. The flipside of this equation is that microservices require a DevOps approach to ensure success. In addition, adopting GitOps can make a big difference in terms of the ease of maintenance, reliability, and auditability of a microservices application.
Traditional monolithic applications are less compatible with agile development practices, but they have less moving parts and are easier to monitor and manage.. On the other hand, microservices architectures are complex and distributed, containing many moving parts, dependencies, and separate technology stacks. This higher complexity means that microservices are only feasible for organizations that invest in automating deployment and monitoring tasks.
Monolithic vs Microservices Architecture
A monolithic architecture is a large system built with a single codebase and deployed as one unit, typically fronted by a load balancer, and integrated with a database on the back end. It usually contains three key components: a user interface, data interface, and business logic. Monoliths are useful for projects that require minimal operational overhead.
The main advantages of a monolithic architecture include:
- Simplicity—building, testing, and deploying a monolithic architecture is relatively simple. Monolithic applications offer unidirectional, horizontal scaling, running multiple copies of an application with a load balancer.
- Cross-cutting—monolithic applications have a single codebase, allowing them to address cross-cutting concerns easily. These concerns include configuration management, logging, and performance monitoring.
- Performance—the components in a monolith usually share memory, making them faster than components that use service-to-service communications via mechanisms like IPC.
The main drawbacks of a monolithic architecture include:
- Resource efficiency—monolithic applications do not support elastic scalability. They are typically deployed on one server for their entire lifecycle. During normal loads, they often have very low resource utilization, and during unexpected peak loads, they can experience downtime due to insufficient resources.
- Tight coupling—monolithic components become entangled and tightly coupled over time, creating problems for managing and scaling deployments. This coupling effect also contributes to monolith drawbacks.
- Lack of reliability—if a single module in a monolithic application has an error, it can crash the whole application.
- Time-consuming updates—the reliance on a single codebase and the prevalence of tight coupling require a full redeployment of the application for every update.
- Inflexible technology stack—a monolithic architecture uses a single technology stack throughout the application. Changing the technology stack is time-consuming and expensive.
In contrast, a microservices architecture consists of separate, loosely coupled services. It segments the components of an application into small, independent services, enabling granular deployment and scaling.
The main advantages of microservices include:
- Resilience—microservices are fault-tolerant by design. When a component failed, it is automatically healed or replace with another working component, with minimal impact to user experience.
- Technology agnostic—each microservice can be built using different programming languages, technologies, and protocols. This gives teams tremendous flexibility in using the most effective tools for each component of the microservices application.
- Scalability—microservices-based applications are easily scalable because developers can scale each component independently. This approach also helps optimize resource consumption.
- Loose coupling—the components in a microservices-based app are loosely coupled, allowing them to undergo individual testing processes. The application can adapt more easily, accumulating changes gradually. In addition, each team has less dependencies on other teams, and there is a reduced chance of feature clash.
- Compatible with containerization—microservices go hand in hand with containerized architectures and Kubernetes. Each container is typically deployed as a container, and the application as a whole can be managed within a Kubernetes cluster.
However, switching to a microservices approach does involve some challenges, especially in terms of management and cost. Drawbacks of a microservices architecture include:
- Skill requirements—the microservices approach requires experience in new technologies, design patterns, and architectures. Engineering staff should be skilled in cloud native infrastructure and microservices architecture principles.
- Complex testing and monitoring—with applications split into multiple components, there are many moving parts to monitor and repair. Robust testing and monitoring solutions are essential to maintain the complex, dispersed application landscape.
Monolithic architectures are often the better option for developing small, simple applications. Switching to a microservices model is not recommended if the team lacks expertise and experience. On the other hand, microservices architectures are better suited to complex application development. Organizations with skilled, motivated developers can benefit significantly from the switch.
Microservices vs Service-Oriented Architecture (SOA)
Service-oriented architecture (SOA) is an approach to software development that takes advantage of reusable software components, known as services. SOA can be considered an early form of microservices architectures. It is a legacy model that is not commonly practiced for current software applications, but it is useful to understand the differences between the original SOA architecture and a microservices approach.
In SOA architectures, each service consists of the necessary code and data integrations to execute a particular function (i.e., signing into an app, processing a form, etc.). Service interfaces offer loose coupling, allowing services to access each other without knowledge of the underlying integration implementation. This loose coupling saves time because developers can reuse components in multiple applications. It presents an advantage but also a risk—the shared enterprise service bus (ESB) allows issues to spread between connected services.
Here are some key areas of comparison between SOA and microservices:
- Reusability— the primary objective of SOA is to enable reusable integrations and component sharing, which enhances scalability. Microservices often reuse components and code, creating dependencies that decrease resilience and agility.
- Speed—SOAs share a common architecture to simplify troubleshooting and development, but this often results in slower operations than microservices-based applications. In addition, updating shared components can be dangerous, as it can impact a larger number of applications in an enterprise SOA environment.
- Synchronous vs asynchronous communication—in SOA, the reusable services are available enterprise-wide via synchronous protocols (i.e., RESTful APIs). However, in microservices applications, synchronous calls generate real-time dependencies and impact resilience. These dependencies often affect performance due to latency. Microservices apps thus prefer asynchronous communication (e.g., event sourcing, where a publish/subscribe model helps keep components up-to-date with changes to other components).
- Data sharing vs duplication—SOA services allow applications to synchronously retrieve and modify data directly at the primary source, reducing the maintenance of complex data synchronization. Microservices applications ideally allow each service to access data locally, maintaining its independence.
- Storage allocation—SOA architectures usually allocate storage resources via a unified data storage layer shared across an application’s services. Microservices often have dedicated servers or databases to store data for any service.
Should Your Team Be Using Microservice Based Architectures?
A microservices-based architecture can help DevOps teams achieve their software engineering cadence goals. However, since the architecture is highly complex, organizations should determine when a microservices architecture is truly needed and apply a walk-crawl-run approach, starting small and scaling up gradually to ensure the approach works well in their environment.
It is not always needed to decompose all functionality into separate, independently deployable services instead of maintaining the functionality in a monolith or coarse-grained module. Ideally, organizations should work pragmatically to implement microservices as needed rather than modifying all aspects of the application.
A microservices architecture does not only impact functionality – it also impacts the entire development process. It typically requires making changes to the operating model and team structures and responsibilities. It also involves knowledge and adoption of distributed computing architecture patterns.
Microservices Architecture Patterns
The implementations of microservices may differ, but all microservices architectures share several core concepts, including:
- Distributed architecture—this pattern means that each component within a microservices architecture is fully decoupled from others, accessible via a remote access protocol (e.g., SOAP, REST, etc.). This distributed design facilitates deployment and scalability.
- Independently deployed units—this pattern makes deployment easier, enabling the decoupling of components. Service components are key to this approach, with each microservice representing a component rather than a full service. Each service component contains at least one module representing a specific function or portion of an application. Microservices can have varying levels of granularity.
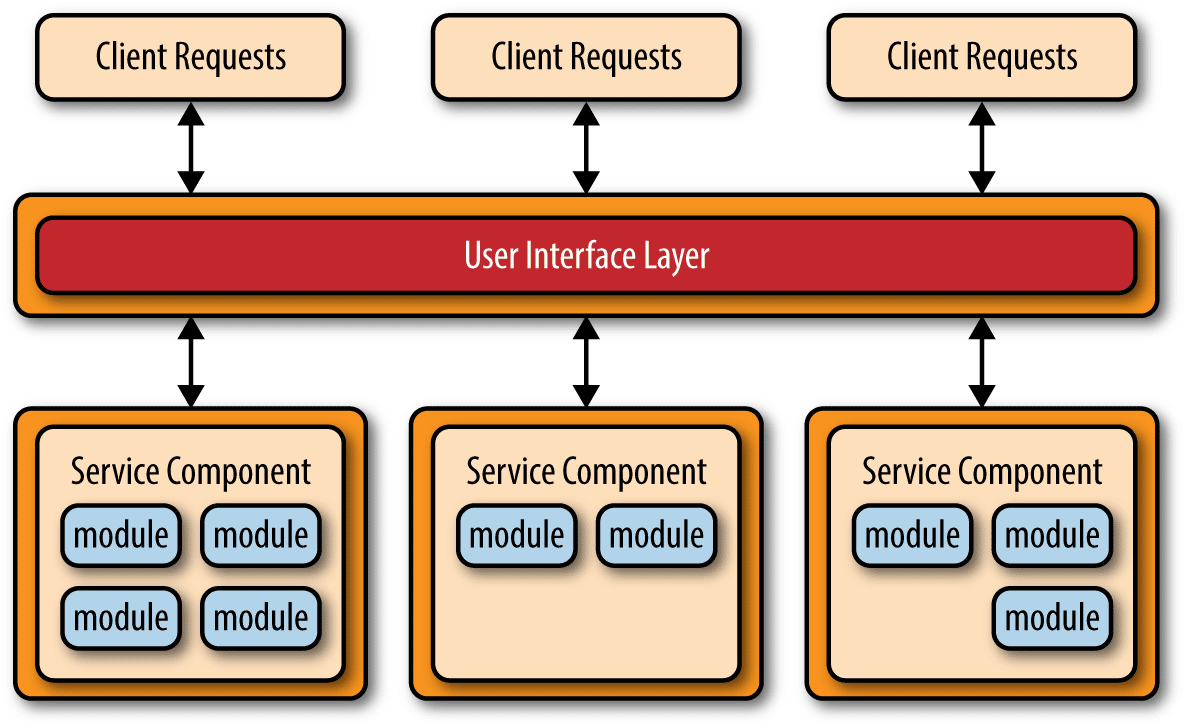
Image Source: O’Reilly
Another aspect common to all microservices architectures is their evolution from other common architectures. Microservices emerged to solve existing problems, evolving out of monolithic and distributed application architectures. The first focused on a layered architectural approach and the second focused on a service-oriented approach.
The rise of continuous delivery and deployment pipelines drove the evolution of the microservices architecture pattern from monolithic applications. The tightly coupled components in a monolithic application make it difficult to test, modify, and deploy, requiring longer development cycles (usually monthly). Monolithic apps were too brittle for frequent deployments.
The microservices architecture provided a solution by dividing a large application into small, manageable units. Each component is individually deployable, allowing developers to test and modify components without impacting the rest.
The SOA pattern is robust, offering high levels of heterogeneous connectivity, service orchestration, and abstraction. However, it is complicated and expensive to implement, overkill for many applications. The microservices pattern offers similar advantages in an architecture that is more scalable and in many cases simpler to implement.
Key Components of Microservices Architecture
Here are some of the main concepts used in microservices architecture:
Containers
A container is a software unit that packages an individual service and its dependencies, keeping it together throughout the deployment lifecycle. While the microservices architecture does not require containerization, containers help accelerate deployment.
Containers differ from virtual machines (VMs) in their ability to share middleware and operating system components. They eliminate the need for an individual operating system for each VM, allowing organizations to run more microservices on one server. Containers are also deployable on-demand and don’t impact application performance; developers can easily move, replace, or replicate them.
Another important aspect of containers is that they are immutable – a container cannot be changed once deployed, promoting consistency and reliability. Containers can also be controlled via declarative configuration, meaning that developers state the final configuration they require, and the container platform automatically achieves this desired state.
Containers are independent and consistent, making them critical for scaling components of a microservices architecture based on workloads. They also enable redeployment in case of failure. Docker began as an open source container management platform and a major container provider today, with many tools evolving around it.
Service Discovery
A microservice architecture typically has a fluctuating number of active instances, making it difficult to keep track of services distributed across the network. Service discovery allows service instances to adapt in evolving deployments, distributing the appropriate load between each microservice. This component consists of:
- A service provider—initiates service instances over the network.
- A service registry—stores available instance locations.
- A service consumer—retrieves the location of service instances from the registry and communicates with them.
Service discovery uses two main discovery patterns:
- Client-side discovery—searches the registry to find a service provider, chooses available service instances, and forwards requests.
- Server-side discovery—the router searches the registry and requests the relevant instance once discovered.
The service registry must always have current data to allow services to find their related service instances. If the registry is down, it hinders all services, making it important to ensure the service discovery mechanism is fault tolerant.
CI/CD Pipeline
A comprehensive, automated CI/CD process is essential for scaling microservices. Without end-to-end automation, testing and deploying hundreds of services is unfeasible. The microservices approach requires frequent deployments and flexible development processes.
The following strategies can help organizations implement a CI/CD pipeline to support their microservices environment:
- Container-based pipelines—containerized pipelines can run independently with various language versions, leveraging Docker images to enable flexibility and self-service. This approach helps streamline development efforts.
- A unified, context-based pipeline—a single malleable pipeline should handle all microservice integrations and deployments. It is mainly relevant for applications where all microservices use the same language and technology stack. Rather than managing multiple pipelines for different microservices, this approach uses triggers to communicate context and influence pipeline behavior. Triggers may be action-based or time-based and induce dependencies to perform specific actions.
- Blue/green or canary release models—organizations can test their releases using a blue/green or canary deployment strategy to address the complexity of their microservices applications. This approach involves releasing a new software version in parallel to an existing version, to test the new version in real-world conditions while minimizing the impact on users.
Real-Time Monitoring
Traditional monitoring systems are often insufficient for handling the complexity and distributed nature of microservices. Robust monitoring solutions can collect metrics and distributed traces to glean insights and predict system behavior.
Monitoring is essential for troubleshooting and maintaining performance. The system monitoring stack should use metrics, logs, and traces to feed data to the dashboard from multiple services. Metrics should focus on traffic, latency, and errors to help determine when the system generates alerts. Maintaining observability requires data from running services and infrastructure, stored and processed in a consistent format, with searchable logs. Identifiers and timestamps can help humans and machines to navigate through logs.
An ID field for each service helps track system requests, enabling context-based log grouping and distributed tracing. It also provides insights into operations and the relationship between services.
API Gateways
An API gateway is crucial for communication in distributed architectures, including microservices. It provides a layer of abstraction between the services and outside clients, handling most of the communication and admin tasks of a monolith (this helps keep the microservices application lightweight). API gateways can also handle requests, message monitoring, and load balancing.
API gateways also help speed up communication between clients and microservices and clients by translating messaging protocols. An API gateway typically provides embedded security features, managing authorization and authentication and tracking requests to detect intrusion.
Should You Use a Service Mesh for Your Microservices?
Microservices are gaining traction due to benefits like dynamic service discovery and easier network policy enforcement. However, their operational complexity presents a challenge for observability. If an organization doesn’t own the code for a service, it might experience low visibility. Identifying performance issues and manually changing code is time-consuming. Another issue is potential latencies resulting from extra service hops during service-to-service communications.
Service mesh technologies can help address these issues, making them increasingly important for microservices. A service mesh is an infrastructure layer that offers platform-level automation, ensuring communication between container-based application components. Service mesh tools help manage operations, handling east-west traffic for remote procedure calls originating in the data center and traveling between services.
Service meshes differ from API gateways, which handle external communications and north-south traffic. Services meshes have a flexible release process, enabling scalable microservice operations while ensuring security, resiliency, and high availability.
Once an organization has an established CI/CD pipeline, it can leverage a service mesh to deploy applications and manage code programmatically. The service mesh approach is especially useful for large applications comprising many microservices. A service mesh can help enforce security by encrypting traffic, authenticating identity, and implementing zero trust.
The main advantages of deploying a service mesh include:
- High availability/fault tolerance—a service mesh lets organizations set up failover and use fault injections to test code paths.
- Secure communications—IT teams and CISOs can authenticate, authorize and encrypt communications between services, with the service mesh managing encryption via TLS.
- Observability—a service mesh deployment supports real-time monitoring and distributed tracing.
Microservices Delivery with Codefresh
Codefresh helps you answer important questions within your organization, whether you’re a developer or a product manager:
- What features are deployed right now in any of your environments?
- What features are waiting in Staging?
- What features were deployed on a certain day or during a certain period?
- Where is a specific feature or version in our environment chain?
With Codefresh, you can answer all of these questions by viewing one dashboard, our Applications Dashboard that can help you visualize an entire microservices application in one glance:
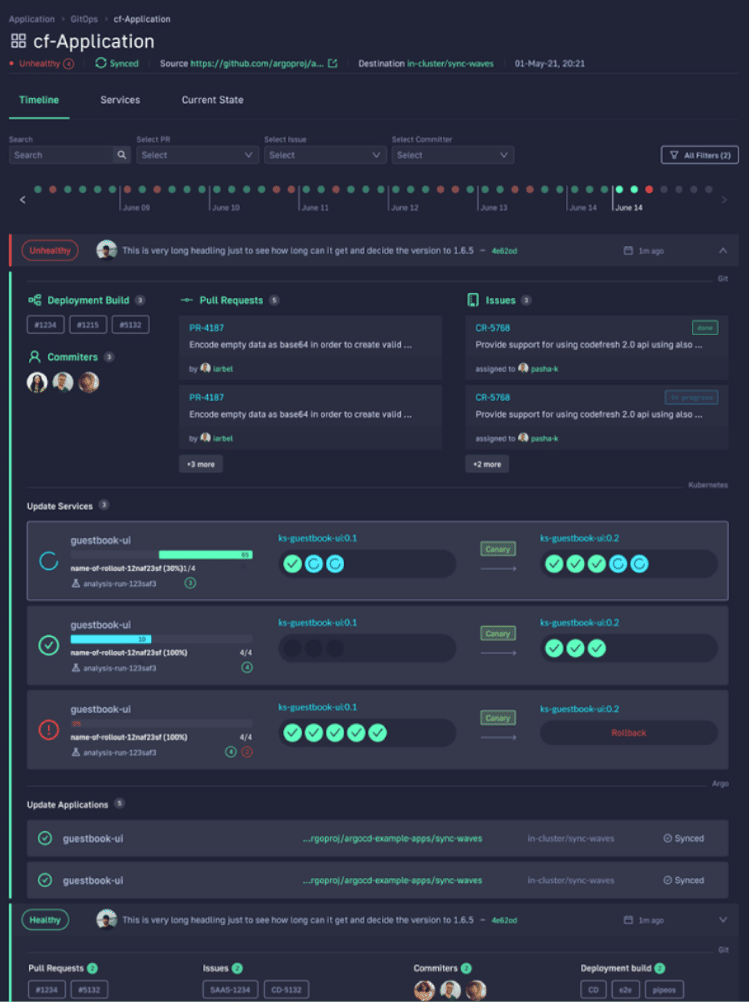
The dashboard lets you view the following information in one place:
- Services affected by each deployment
- The current state of Kubernetes components
- Deployment history and log of who deployed what and when and the pull request or Jira ticket associated with each deployment

The World’s Most Modern CI/CD Platform
A next generation CI/CD platform designed for cloud-native applications, offering dynamic builds, progressive delivery, and much more.
Check It Out