
In today’s technology landscape (which one could describe as a sky filled with clouds that overlook a sea of IoT devices), clients expect a constant flow of updates. They also expect them to be seamlessly deployed. From microservices to mobile apps, modern applications have lots of moving components required to deliver their services. The pipeline that keeps the updates flowing is continuous delivery, and optimizing time to market is what makes it important. Read this useful tutorial and make sure to create a free Codefresh account to start building, testing and deploying Docker images faster than ever before.
What are CI and CD?
Just to set our baseline, I thought it would be useful to define what CI and CD are before getting into the value they can provide. Instead of redefining these terms, let me cite the “official” definitions from the guys at ThoughtWorks, who literally wrote the books on these topics:
Continuous Integration (CI) is a development practice that requires developers to integrate code into a shared repository several times a day. Each check-in is then verified by an automated build, allowing teams to detect problems early.
Continuous Delivery (CD) is the natural extension of Continuous Integration: an approach in which teams ensure that every change to the system is releasable, and that we can release any version at the push of a button. Continuous Delivery aims to make releases boring, so we can deliver frequently and get fast feedback on what users care about.
For more information on the subject, you can also read the article about the differences between CI and CD.
Pipelines: What are they?
Once you have CI and CD in place, the deployable unit path is called a pipeline. You can see an example pipeline in the image below:
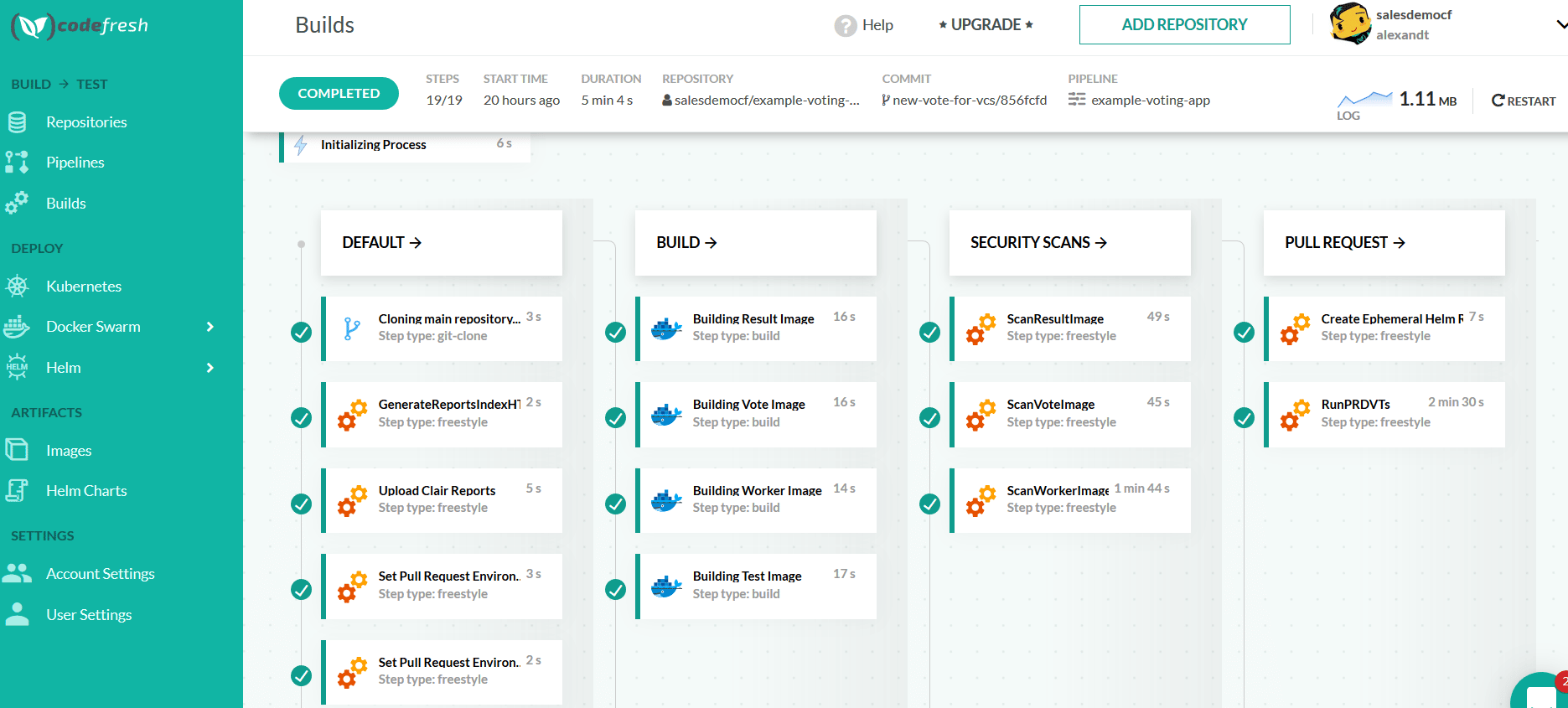
A pipeline procedure is triggered when code is committed to a repository hosted somewhere like GitHub. Next comes notification to a build system, such as Codefresh. The build system compiles the code and runs unit tests.
Wait, your code does have unit tests, right? Of course it does; I don’t know why I asked. (If you are not doing unit testing, you need to!) Back to the pipeline.
If your pipeline is built well, and unit tests go smoothly, at this point integration tests should be the next step.
After integration testing is done, you can create images and push them to a registry service, such as Docker Hub. From there, they can be easily deployed.
This is just a basic example. A pipeline can do many other things, such as performing security scans, run quality checks on the code, send slack notifications etc. You can also have approval steps that stop a pipeline and ask for human approval before resuming their operations.
Some pipelines also include automatic deployment (which is sometimes called Continuous Deployment) to a test environment for user validation after the packages are built.
Pipelines: The Good, The Bad, The Ugly
Now that you know what a pipeline is, let’s discuss the pros and cons of pipelines.
Probably the biggest con (although it’s easy to avoid as long as you approach pipelines in a healthy way) is the temptation of trying to build your own tools in-house to handle the core work that is done during the CI/CD pipeline. This is insane. As I mentioned in the previous section, there are more than enough tools available in the market to get you started without having to reinvent the wheel. A lot of companies try to build a pipeline using bash or python scripts. Almost always they end up with a spaghetti structure of files and methods that nobody wants to edit or add features.
Pipelines done the wrong way can also be dangerous because they can limit the amount of choice you have in deciding which tools to use. You can spend a lot of time trying to find the perfect tool, or combination of tools, to meet your dream scenario. A better approach is simply to find tools that are good enough to start. Whatever tool you pick first, you will probably be missing a specific feature you want, or it will be too big or small for what you need it to do. This is why you should always tweak, tune, optimize, and substitute components in your pipeline as your product size and needs change.
Codefresh is one of the few solutions that covers both CI and CD so it is very easy to get started with pipelines that only work with unit tests and code packaging and move then gradually to more complex workflow that handle deployment.
Now, for the good parts of pipelines. There is lots and lots of good about pipelines when they are done the right way. Some of the highlights of a well assembled pipeline are:
- Developers can just worry about their code and dependencies, not runtime configuration.
- Testers can see what tests have been automatically run, and then either automate more, investigate trouble areas, or simply spend their time on the new functionality to validate it against client requirements.
- Operations can just redeploy if something isn’t working inside an application. No restoring from tape, or wondering what changed and wasn’t documented.
- Introducing new versions or bug fixes is the same routine process.
- Velocity of deployments is increased. New features reach production much faster.
Importance of Pipelines
The single most important piece of a solid deployment pipeline is that it is so consistent and reliable, it’s boring. Building code isn’t fun, packaging things and managing dependencies between versions sucks, and having someone waiting around to make sure every successful build gets put in the correct test environment right away is a bad use of everyone’s time.
Any developer that has been in the industry for a while has fought to get something deployed in a second (or 15th) environment and it just won’t start, or throws a weird error that no one has seen before. Then, the game to find what step got missed, starts. Of course it’s always someone else who missed the step, and asking other people if they performed ALL of the steps in their jobs in order to track down the source of the problem is extremely time-consuming.
With delivery pipelines, however, you get the same result every time, so if it works in the system test environment it will work in UAT and staging and production.
Boring is good. Just ask your friendly neighborhood first responder. The best days are the boring days when they don’t need to rush anywhere. Those days happen much more often when you have a well-designed and implemented CI/CD pipeline.
Your pipeline should be boring and repeatable. It should just work. It should be visible to all project stakeholders (even some non-technical people). Project managers for example should be able to see a pipeline and know if a feature is now in production or not.
Psst, want to try it out? Check out Codefresh, it’s the best CI/CD for Docker out there.
