
In my last blog post, I wrote about how the term microservice has entered our vocabulary. In this post, I examine the trend toward microservice architecture and discuss how Node.js and Docker technologies converge to facilitate this pattern.
The Era of Monolithic Architecture
The classic view of a web application looks like this:
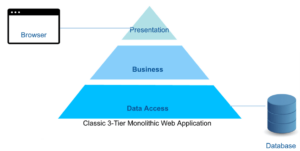
In software engineering, this is known as monolithic architecture, and it has a number of advantages.
- It is relatively straightforward to begin developing, testing and debugging code that is bundled into a single executable process. Until the codebase actually begins to reach a mass where it really deserves to be called monolithic, it can be fairly easy to reason about data flows and application behavior.
- The deployment model is easy to understand. The application is deployed as a unit, whether a bundle of files or compressed as a single web application resource (for example, a Java WAR file).
- The model for scaling is simple to understand. Scale up by installing the application on a more powerful server and scale out by placing the application behind some type of load balancer to distribute requests so that no single instance is overwhelmed by high loads.
The second point above is actually pretty significant, especially when you consider that creating server environments has historically been time-consuming and expensive. Because of this, there was a practical limit on the number of environments that were available for promoting applications through a pipeline to production. Starting from the developer’s local workstation, a staged pipeline might include some or all of these:
- (local) – developer’s workstation
- dev (or sandbox) – first stage for developers to merge and unit test
- int** – integration stage for developers to test with external databases and other services; often used for CI builds
- qa (or test) – for functional and other types of testing
- uat** – customer user acceptance testing and demo
- preprod (or staging) – exact replica of production environment for final verification
- production – live site
The creation and management of the pipeline from developer workstations to production data center servers, and the requisite team coordination needed to promote builds through each stage, historically involved a significant investment in time and effort. The introduction of virtual machine technology (and eventually Vagrant, and Puppet and Chef) helped provide organizations with labor, time and infrastructure cost savings, but the process nevertheless remained burdensome.
If the process to move an application through the pipeline is laborious and time-consuming, it makes sense to coordinate larger releases that are worth the effort. And with larger codebases, then type-safe, class-based object-oriented languages with a heavy emphasis on domain models, design patterns like inversion of control through dependency injection, and all the things that became the hallmarks of well designed applications of the last decade or so, may appear quite compelling, if not downright necessary for mediating the challenges of maintainability and extensibility as the application matures.
The Java and .NET platforms, frameworks and tooling evolved in part to address the burden of developing and deploying a complex codebase and bundle of related artifacts for large, sophisticated applications. And to recapitulate, monolithic architecture made sense in part because the deployment model was not only easy to understand, but given the expense of creating and maintaining various staging environments, it was also more cost effective to manage from a traditional IT operations perspective.
Ramifications of Monolithic Architecture
But at some point, the advantages of a monolithic architecture become significant liabilities.
It inhibits continuous delivery
Staging large epic releases is undesirable, especially to compete in today’s social, mobile and app-centric world where consumers and customers expect updates and new features to be released frequently.
However, we already noted that application deployment is laborious and time-consuming — and of course, the larger and more sophisticated the application, the greater the potential risk of things going wrong.
Continuous delivery is an attempt to reduce the cost and risk associated with delivering incremental changes in large part by automating as much of the deployment pipeline as possible. Nevertheless, for a large complex application, there is simply too much effort, cost, and risk involved in redeploying an entire application to update a single deployment. While feasible, as a practical matter, monolithic architecture inhibits efficient contiuous delivery.
Sub-optimal scalability
We noted that the scaling model for an application is straightforward. But there is a practical limit on scaling up, and scaling out by deploying entire copies of large applications is a relatively expensive and inefficient way to scale.
In particular for larger and more complex applications, not all components are under the same load. It would be more ideal to scale out at the individual component level, but in monolithic architecture, the unit of scaling is the entire application.
Adverse impact on development
Working with the code of a large, complex monolithic application is challenging. Larger codebases are more difficult to maintain and extend, and require greater coordination among teams. The application evolves at a cadence dictated by a release cycle scheduled to amortize the cost of testing and deployment balanced by the desire to release new features to market. The effort involved leads to more epic releases, and all the inherent effort and risks that that implies.
The friction involved in having teams coordinate development, testing and integration of individual layers and slices of the application impedes rapid progress and evolution. Each individual team member needs to take care in setting up their local development environment to support building and testing the entire application regardless of which little piece they’re developing for. As cognitive overhead increases, individual team members become less effective, their contributions take greater effort, and quality is adversely affected.
For a project that will scale in size and complexity, the initial commitment to a specific technology stack (platform, frameworks, tooling) becomes another liability. This is a decision that will generally follow the life of the project over many years, dictated by the application architecture as a whole instead of by the choices available for building individual components over time.
APIs drive modern apps
Application integration, mashups, AJAX, the trend toward single-page applications and the explosion in the number of clients capable of accessing the web have all driven the ascendancy of APIs and forever changed the way we view a web application. No longer is it about the physical unit of deployment corresponding to the user’s experience in a browser — it’s about the user’s experience across a broad range of devices.
The application is the set of services delivering functionality exposed by APIs that power an appropriate experience on a particular client.
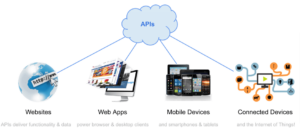
Rise of microservices
With an emphasis on APIs, it becomes more desirable than ever to independently evolve, deploy and scale individual services. By moving away from monolithic architecture, we can reduce codebase complexity through separation of concerns at a physical level. We can focus on a system of processes with loosely coupled partitions at functional boundaries instead of a single process with layered boundaries imposed by classic three-tier web application architecture.
Freeing development teams from the constraint of integrating and delivering their functionality as part of a larger complex bundle relieves an enormous amount of friction. By targeting lightweight, fine-grained services, smaller teams can move at their own cadence, test more effectively, and deploy more rapidly. Once deployed, these services can potentially scale independently and more cost effectively.
Of course, these benefits sound great in theory, but as the previous post made clear, there is a reason why we were building monolithic applications in the first place. Achieving these benefits depends on a few other factors.
Enter Docker
As noted previously, deployments environments have traditionally been laborious to create and maintain. Virtual machine technology and solutions like Vagrant, Puppet and Chef, have helped mitigate the burden and expense, but the pursuit of microservice architecture creates an even greater demand for compute resources.
In 2013, a company known for its multi-language Platform as a Service (PaaS), dotCloud, released the open source Docker project around the container technology it had been developing.
While based on a legacy that goes back to chroot, FreeBSD jails, Solaris zones, cgroups and Linux containers, Docker helped catalyze mainstream attention.
Docker provides the ability to run processes in isolated operating environments. Unlike virtual machines, however, Docker containers use a shared operating system kernel. By not virtualizing the hardware, containers are far more efficient in terms of system resources, and they launch essentially as quickly as a process can be started.
Docker makes the idea of micro operating environments for microservices practical. It makes it feasible to have development environments and all the other environments in the deployment pipeline mimic the production environment.
Enter Node
Docker is a major contributor to making a microservice architecture cost effective and practical. It is a tremendous advantage to have technology that so dramatically simplifies the aspect of launching and hosting a process and its dependencies in an isolated compute environment defined by something as simple as a Dockerfile.
But there is another factor to the equation. While docker provides an efficient operating environment for a process, it doesn’t have anything to do with how that process was developed.
The introduction of Node.js in 2009 presented developers with an exciting opportunity to leverage a lean and mean platform that leveraged JavaScript and Google’s high performance V8 engine for building lightweight, fast, and highly scalable network services.
The platform and core framework were designed around an event-driven, non-blocking I/O model and constructing a trivial server is as simple as the following script:
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'application/json'});
res.end('{ "message": "Hello World" }');
}).listen(3000, '127.0.0.1');
console.log('Server listening at http://127.0.0.1:1337/');The server can be launched by executing the script via Node:
$ node server.js
Server listening at http://127.0.0.1:3000/Contributing to Node’s phenomenal growth was an excellent package management system built on lessons learned from other communities. Creating, publishing, and installing a Node module or collection of related modules as a package is simple and fast.
Packages contain their own local copy of installed modules, easing deployment since there is no requirement to install to any common file system locations (and resolve potential version conflicts).
All that is required for a package is a package.json file that contains a bit of metadata about a package and its dependencies. A minimal package.json file only requires a name and version.
Because creating and publishing is so trivial, and installing is so simple and effective, npm encourages the development of lightweight, narrowly focused libraries. The growth of the public npm registry has been nothing short of phenomenal.
As March 2015, there are over 130,000 packages at the public npm registry, and over one billion downloads during the past month.

In terms of this growth, npm has eclipsed all other package managers, including the venerable CPAN.
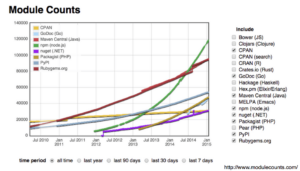
Module Counts Comparison, January 2015
While no particular technology stack is perfect, the following benefits of Node can’t be understated with respect to microservice architecture:
- Lightweight HTTP server processes — the Node platform is based on Google’s well-regarded open source, high performance V8 engine, which compiles JavaScript to native machine code on supported systems; this machine code undergoes dynamic optimization during runtime. The V8 engine is highly tuned for fast startup time, small initial memory footprint, and strong peak performance.
- Highly scalable — the Node platform was designed from the onset for end-to-end asynchronous I/O for high scalability. There are no extraordinary operating environment requirements to support high scalability, so cost and complexity are not not special concerns in planning deployments of large numbers of services.
- Lightweight for developers — there is minimal ceremony involved in creating and consuming packages, which encourages a high degree of modularization and lightweight, narrowly-focused packages independently versioned and published.
Wrapping it up
The convergence of Node.js and Docker container technology is phenomenally well suited for microservice architecture.
The benefits include a higher degree of productivity because developers focus their energy on building smaller, narrowly-defined services partitioned along functional boundaries. There is less friction and cognitive overhead with this approach, and services can evolve, be deployed, and scale independently of others.
Node provides a high performance platform that supports high scalability with lightweight server processes. Its simple package management system makes creating, publishing, and consuming packages easy, facilitating and streamlining the process of building and deploying lightweight services.
Docker makes running server processes in isolated compute environments (containers) cheap and easy. These containers are extremely efficient in terms of system resources and provide excellent peformance characteristics, including fast starts.
In future posts, we’ll provide recipes for building and orchestrating microservices. We’ll also discuss some of the challenges that come with distributed systems as well as strategies for handling them.
These are the slides for my presentation at NodeSummit 2015: