
In our previous guide, we documented 10 Docker anti-patterns. This guide has been very popular as it can help you in your first steps with container images. Creating container images for your application, however, is only half the story. You still need a way to deploy these containers in production, and the de facto solution for doing this is by using Kubernetes clusters.
We soon realized that we must also create a similar guide for Kubernetes deployments. This will hopefully give you the whole picture of how to create a container image and how to properly deploy it (or at least warn you of some common pitfalls).
Notice that in this guide we talk specifically about application deployments on Kubernetes and not Kubernetes clusters themselves. This means that we assume that the Kubernetes cluster is already there (and it is properly set up) and you simply want to deploy an application on it. In the future, we will complete the trilogy by also documenting anti-patterns for the creation of the clusters (i.e. talk about the infrastructure level instead of the application level).
Unlike other guides that simply complain about how things can go wrong, we always associate each anti-pattern with the respective solution. This way you can actually check your own deployment process and fix any issues without hunting down extra information.
Here is the list of bad practices that we will examine today:
- Using containers with the latest tag in Kubernetes deployments
- Baking the configuration inside container images
- Coupling applications with Kubernetes features/services for no reason
- Mixing application deployment with infrastructure deployment (e.g. having Terraform deploying apps with the Helm provider)
- Performing ad-hoc deployments with kubectl edit/patch by hand
- Using Kubectl as a debugging tool
- Misunderstanding Kubernetes network concepts
- Using permanent staging environments instead of dynamic environments
- Mixing production and non-production clusters
- Deploying without memory and CPU limits
- Misusing health probes
- Not using Helm (and not understanding what Helm brings to the table)
- Not having deployment metrics to understand what the application is doing
- Not having a secret strategy/treating secrets in an ad-hoc manner
- Attempting to go all in Kubernetes (even with databases and stateful loads)
By the way, if you still haven’t looked at the container anti-patterns guide, you should do this now, as some of the bad practices mentioned above will reference it.
Anti-pattern 1 – Using containers with the latest tag in Kubernetes deployments
If you have spent any time building containers, this should come as no surprise. Using the “latest” tag for Docker images is a bad practice on its own as “latest” is just a name of the tag and it doesn’t actually mean “most recent” or “lastly built”. Latest is also the default tag if you don’t specify one when talking about a container image.
Using the “latest” tag in a Kubernetes deployment is even worse as by doing this you don’t know what is deployed in your cluster anymore.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-bad-deployment
spec:
template:
metadata:
labels:
app: my-badly-deployed-app
spec:
containers:
- name: dont-do-this
image: docker.io/myusername/my-app:latest
If you apply this deployment you have now lost all information on which container tag is actually deployed. Container tags are mutable, so the “latest” tag does not really mean anything to anyone. Maybe this container image was created 3 minutes ago, maybe it was 3 months ago. You will need to hunt down all your logs for your CI system or even download the image locally to inspect it so that you know what version it contains.
The “latest” tag is even more dangerous if you couple it with an always pull policy. Let’s say that your pod is dead, and Kubernetes decides to restart it in order to make it healthy (remember that is why you are using Kubernetes in the first place).
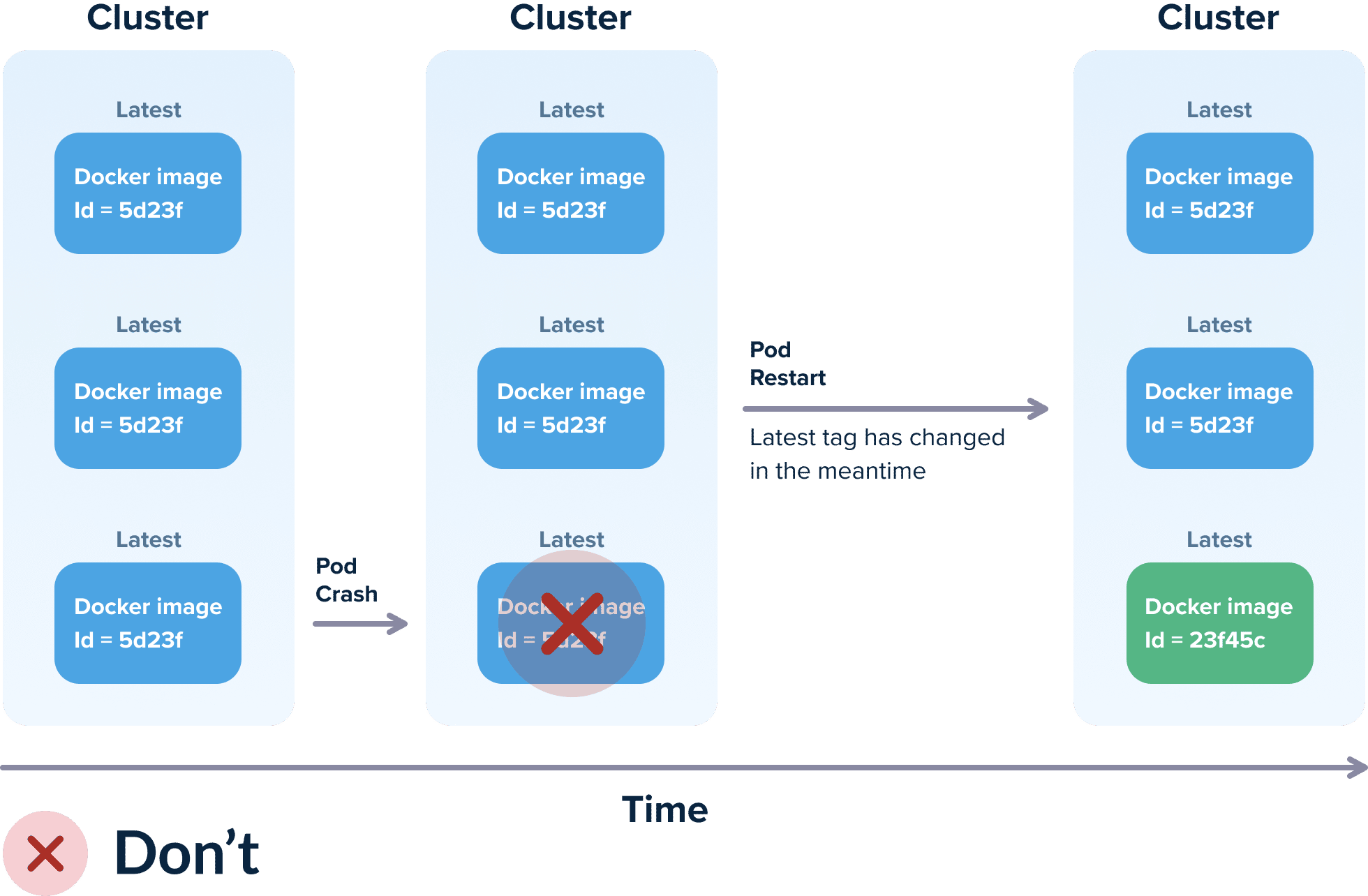
Kubernetes will reschedule the pod and if your pull policy allows this, it will pull the “latest” image again from your Docker registry! This means that, if in the meantime the “latest” tag has changed, you now have a new version in this particular pod which is different from what the other pods have. In most cases, this is not what you want.
It also goes without saying that performing “deployments” by killing pods manually and waiting for them to pull again your “latest” image is a recipe for success (if you do happen to use this form of “deployment”).
The correct deployment format in Kubernetes should follow a proper tagging strategy. The specific strategy is not that important as long as you have one.
Some suggestions are:
- Using tags with Git hashes (e.g.
docker.io/myusername/my-app:acef3e). This is straightforward to implement but may be overkill since a Git hash is not easily readable by non-technical people. - Using tags with the application version following semantic versions (e.g.
docker.io/myusername/my-app:v1.0.1). This method has many advantages for both developers and non-developers and is our personal recommendation. - Using tags that signify a consecutive number such as a build number or build date/time. This format is very hard to work with but can be easy to adopt with legacy applications.
The important thing is that you should agree that container tags should be treated as immutable. A Docker image that is marked as v2.0.5 should be created only once and should be promoted from one environment to another.
If you see a deployment that uses the image with tag v2.0.5, you should be able to…
- pull this image locally and be certain that it is the exact same one that is running on the cluster;
- easily track down the Git hash that it created it.
If your deployment workflows depend in any way on using “latest” tags, you are sitting on a time bomb.
Anti-pattern 2 – Baking the configuration inside container images
This is actually another anti-pattern that comes from building container images. Your images should be “generic” in the sense that they should be able to run in any environment.
This was a good practice even before containers appeared and is already documented as part of the 12-factor app. Your container images should be built once and then promoted from one environment to another. No configuration should be present in the container itself.
If your container image:
- has hardcoded IP addresses
- contains passwords and secrets
- mentions specific URLs to other services
- Is tagged with strings such as “dev”, “qa”, “production”
..then you have fallen into the trap of building environment-dependent container images.
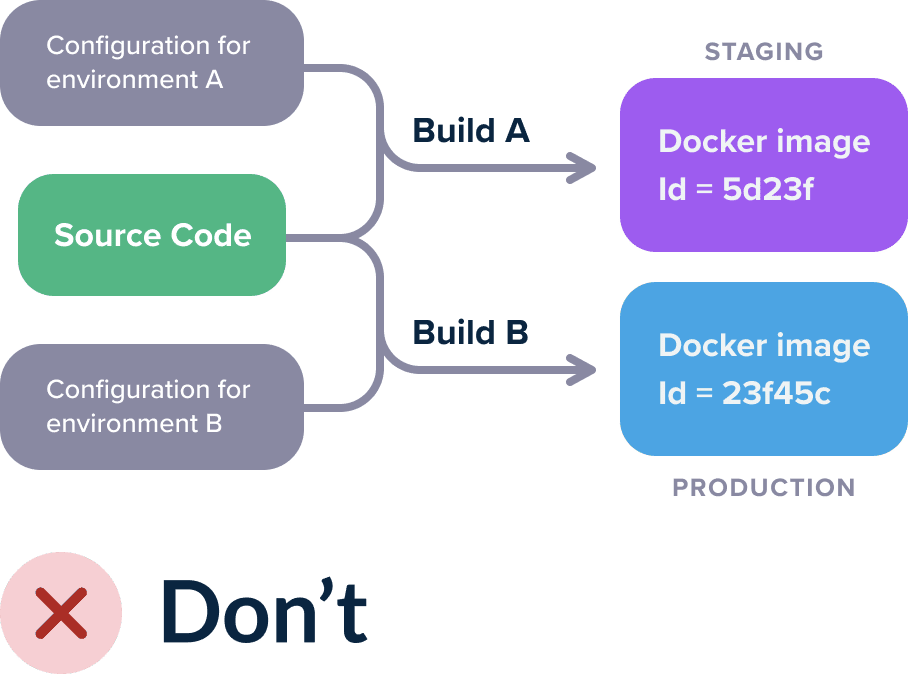
This means that for each different environment, you have to rebuild your image so you deploy to production something different than what was tested before.
The solution to this problem is very simple. Create “generic” container images that know nothing about the environment they are running on. For configuration, you can use any external method such as Kubernetes configmaps, Hashicorp Consul, Apache Zookeeper, etc.
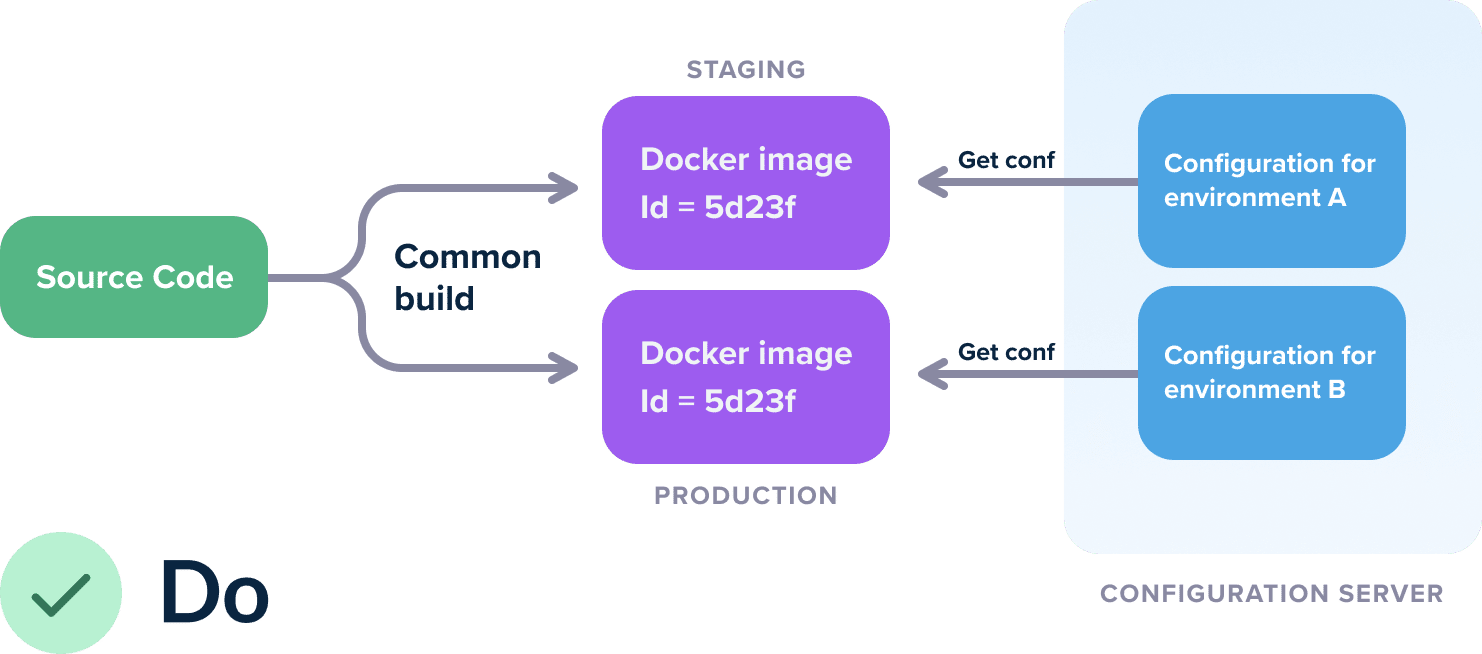
Now you have a single image that gets deployed in all your clusters. It is much easier to understand what it contains and how it was created.
A secondary advantage is that if you do need to change the configuration on your cluster, you can simply change the external configuration system instead of rebuilding the full container image from scratch. Depending on the programming language and framework that you use, you can even update the live configuration without any restarts or redeployments.
Anti-pattern 3 – Coupling applications with Kubernetes features/services for no reason
In the previous section, we explained why you should not store configuration inside a container and how a container should not know anything about the cluster it is running on.
We can take this to an extreme by requiring each container to not even know that it is running inside Kubernetes at all. Unless you are developing an application that is destined to handle a cluster, your application should not tamper with the Kubernetes API or other external services that are assumed to be inside the cluster.
This scenario is very common with overenthusiastic teams that adopt Kubernetes and fail to isolate their application from the cluster. Some classic examples are application that:
- expect a certain volume configuration for data sharing with other pods
- expect a certain naming of services/DNS that is set up by Kubernetes networking or assume the presence of specific open ports
- get information from Kubernetes labels and annotations
- query their own pod for information (e.g to see what IP address they have)
- need an init or sidecar container in order to function properly even in local workstations
- call other Kubernetes services directly (e.g. using the vault API to get secrets from a Vault installation that is assumed to also be present on the cluster)
- read data from a local kube config
- use directly the Kubernetes API from within the application
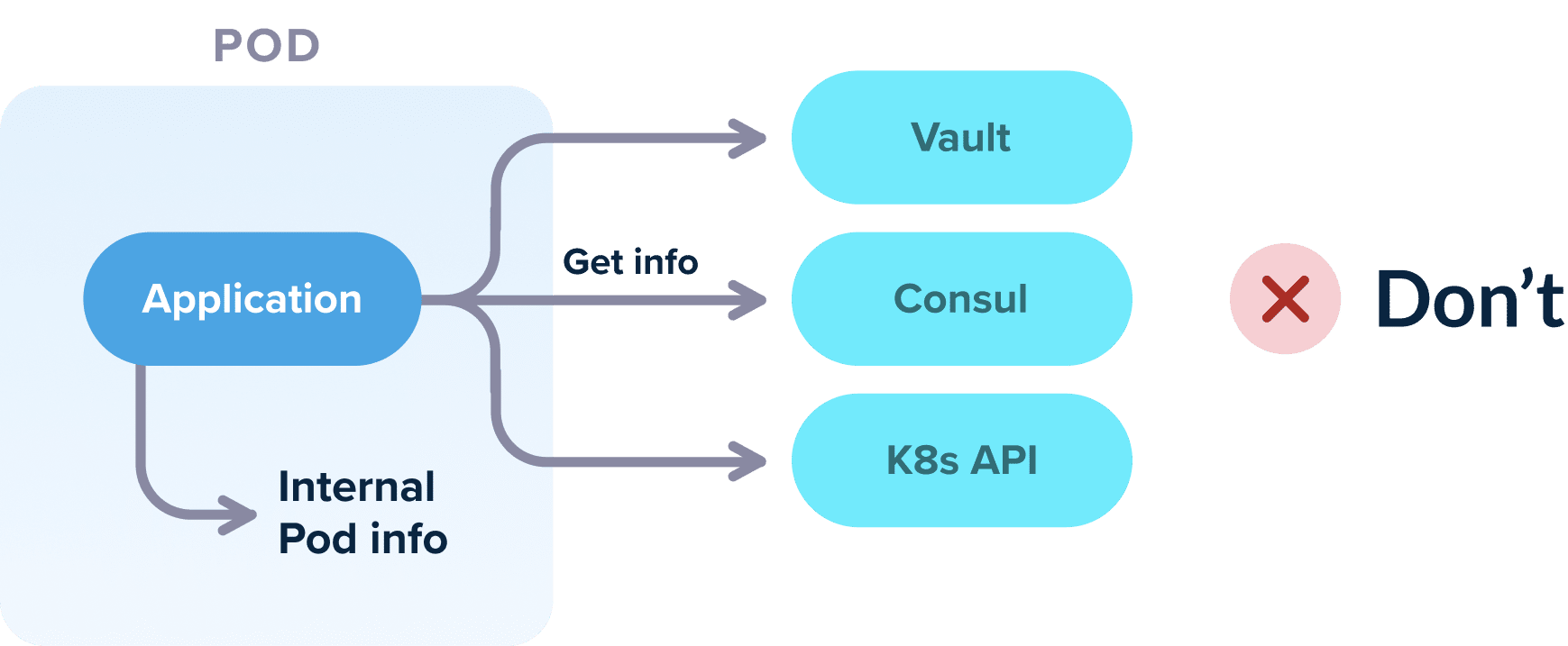
Now of course, if your application is Kubernetes specific (let’s say that you are creating an autoscaler or operator) then it indeed needs to access Kubernetes services directly. But for the other 99% of standard web applications out there, your application should be completely oblivious to the fact that it is running inside Kubernetes.
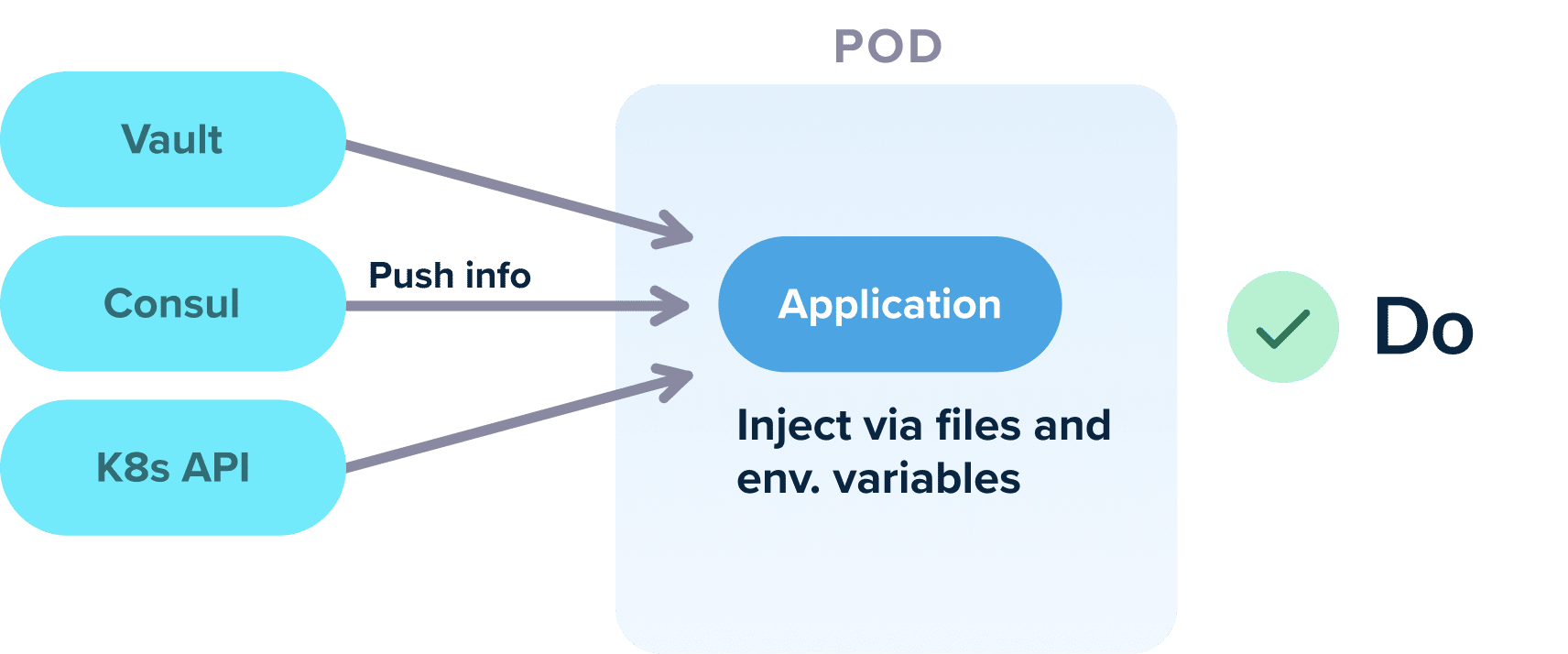
The litmus test that shows if your application is tied to Kubernetes or not is the ability to run your application with Docker compose. If creating a Docker compose file for your app is dead simple, then it means that you are following the 12-factor app principles and your application can be installed on any cluster without the need for special settings.
It is important to also understand the premise of local Kubernetes testing. There are several solutions today for local Kubernetes deployments (minikube, microk8s, kind etc). You might look at these solutions and think that if you are a developer working on an application that is deployed to Kubernetes you also need to run Kubernetes yourself.
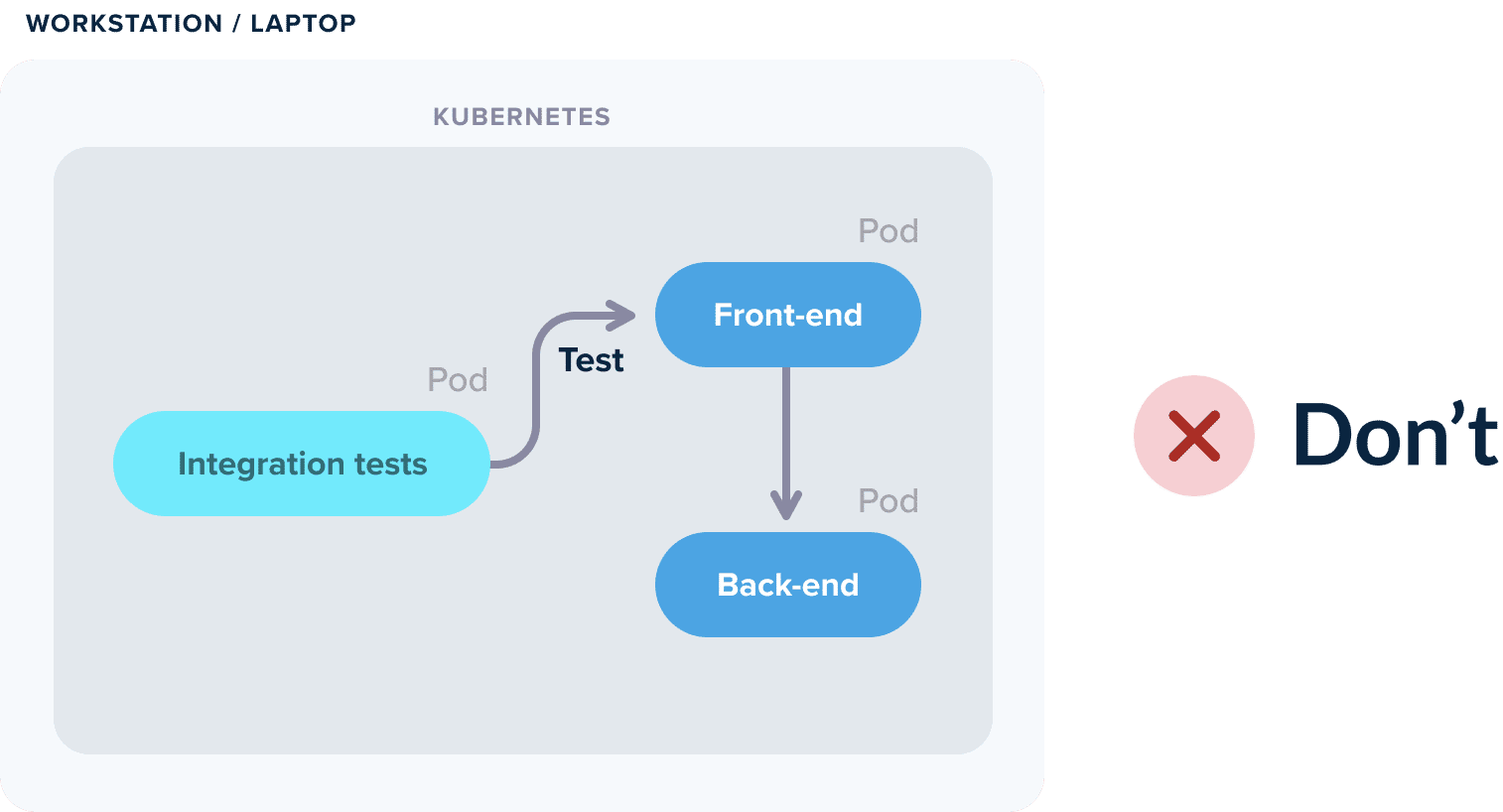
This could not be further from the truth. If your application is correctly designed you shouldn’t need Kubernetes for running integration tests locally. Just launch the application on its own (with Docker or Docker-compose) and hit it directly with the tests.
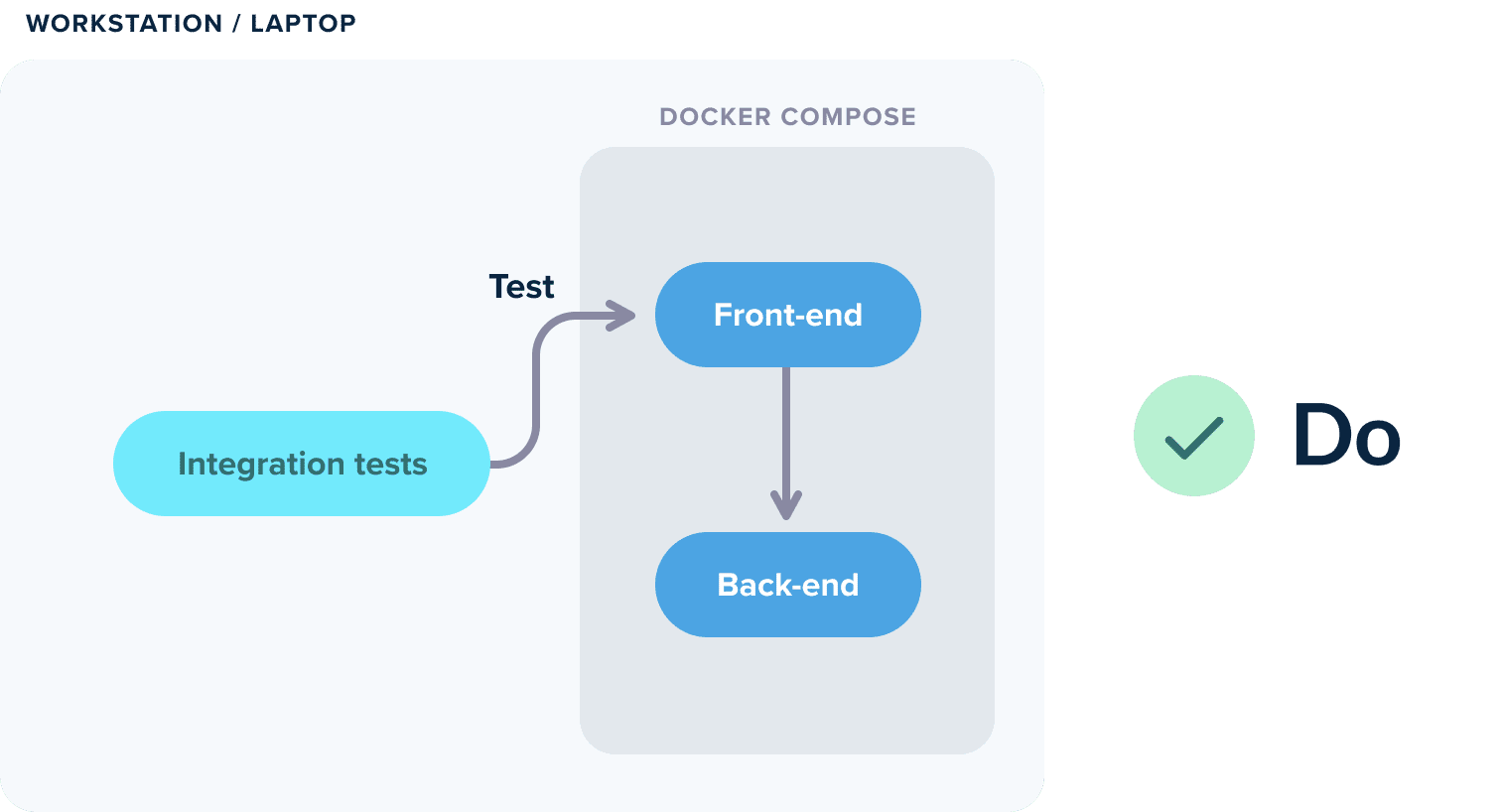
It is ok if some of your dependencies are running on an external Kubernetes cluster. But the application itself should not need to run inside Kubernetes while you are testing its functionality.
Alternatively, you can also use any of the dedicated solutions for local Kubernetes development such as Okteto, garden.io, and tilt.dev.
Anti-pattern 4 – Mixing application deployment with infrastructure deployment
In recent years, the rise of Terraform (and similar tools like Pulumi) has given rise to the “infrastructure as code” movement that allows teams to deploy infrastructure in the same way as code.
But just because you can deploy infrastructure in a pipeline, doesn’t mean that infrastructure and application deployment should happen all at once.
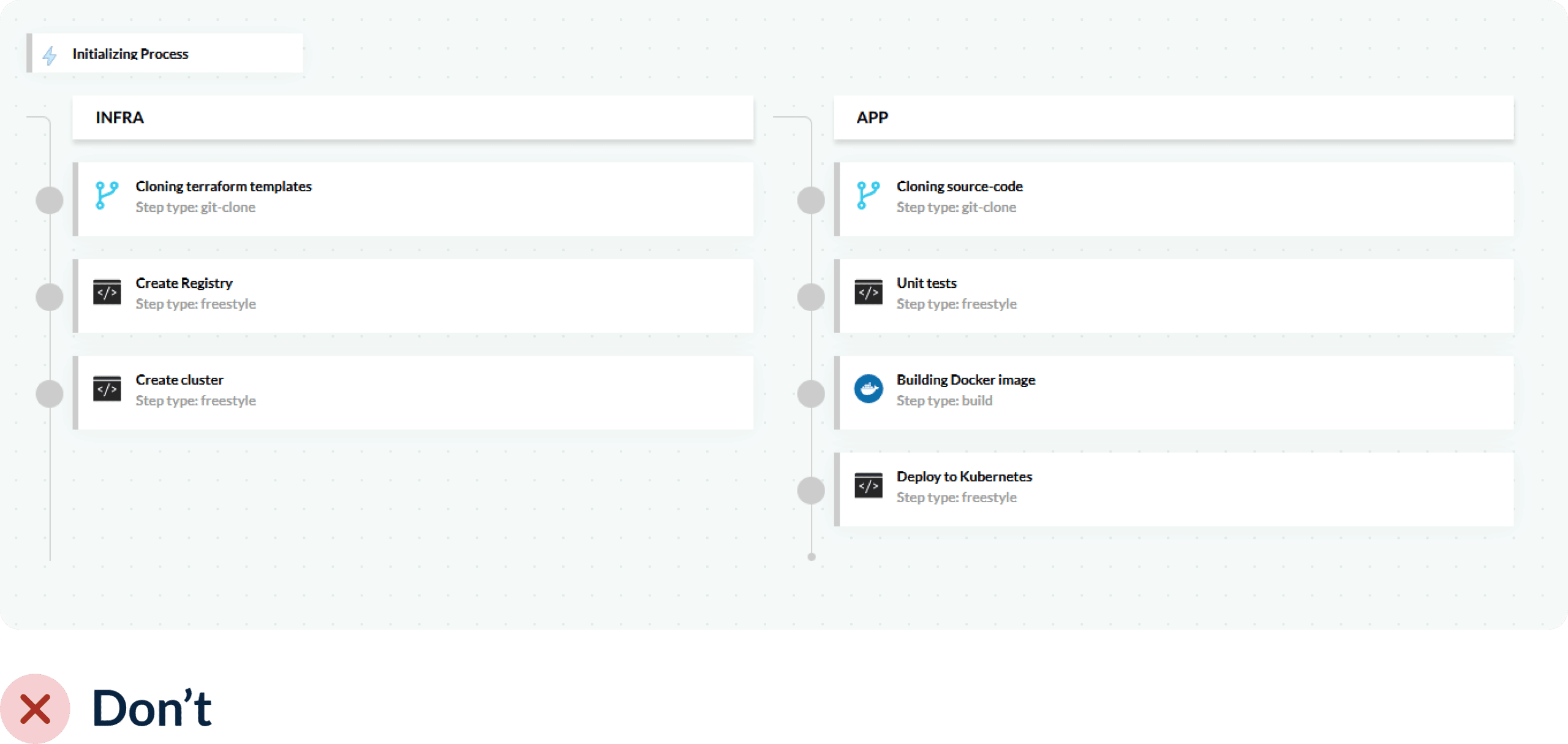
We see a lot of teams that create a single pipeline that both creates infrastructure (i.e. creating a Kubernetes cluster, container registry, etc.) and then deploys an application on top of it.
While this works great in theory, (as it means you are starting from scratch with each deployment) it is pretty wasteful in terms of resources and time.
In most cases, the application code will change much faster than the infrastructure. It is hard to generalize for all companies, but in most cases the rate the application changes might be 2x-10x more often than the infrastructure.
If you have a single pipeline that does both, then you are destroying/creating infrastructure that never changed simply because you want to deploy a new application version.
A pipeline that deploys everything (infra/app) might take 30 minutes, while a pipeline that deploys only the application might take only 5 minutes. You are spending 25 extra minutes on each deployment for no reason at all when the infrastructure has not changed.
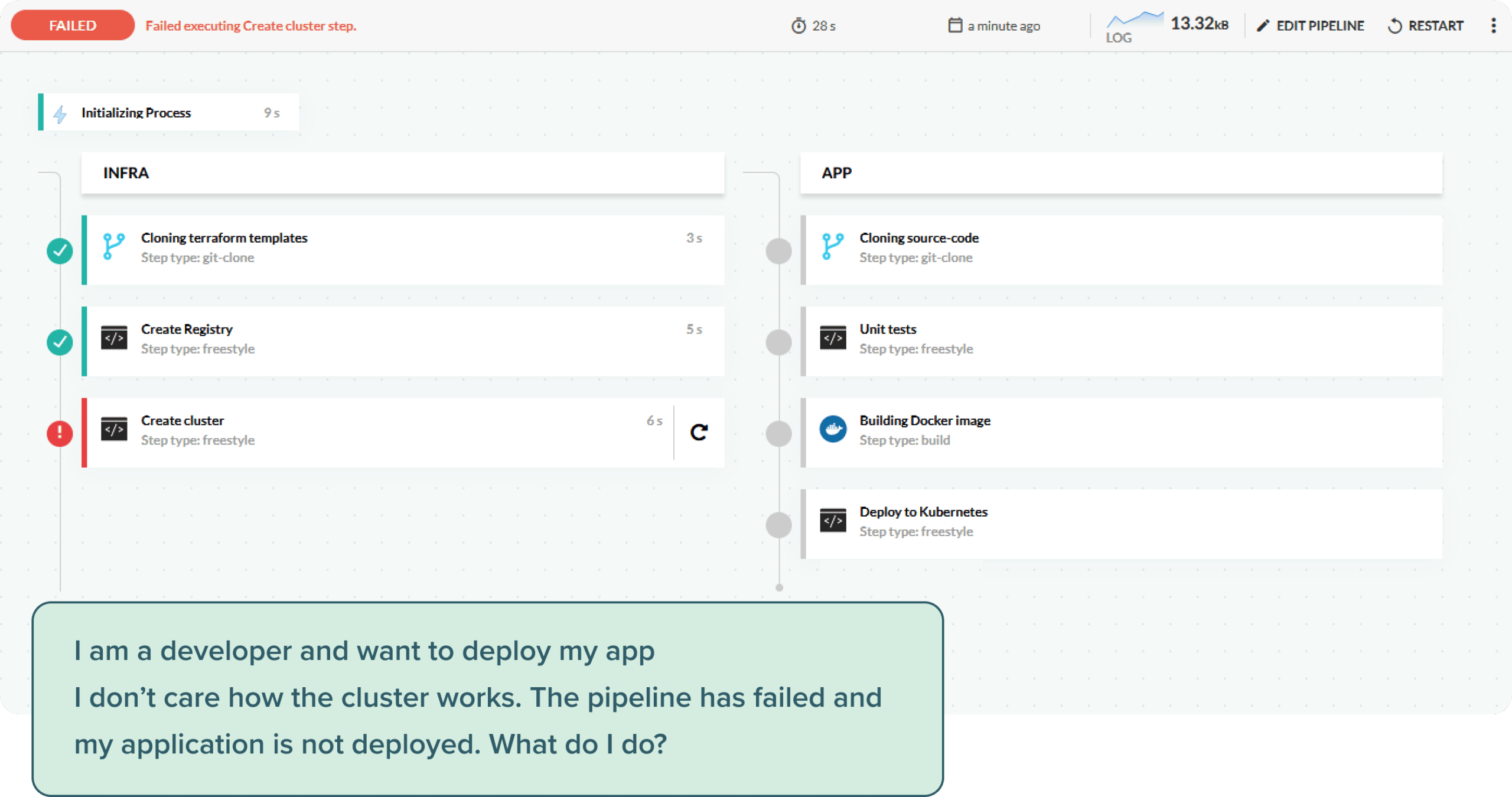
The second disadvantage is that if the single pipeline breaks, it is not clear who must look at it. If I am a developer and want to deploy my application on Kubernetes, I am not interested in Terraform errors, virtual networks, or storage volumes.
The whole point of DevOps is to empower developers with self-service tools. Forcing them to deal with infrastructure when they don’t need to, is a step backward.
The correct solution is of course to split deployment or infrastructure on their own pipelines. The infrastructure pipeline will be triggered less often than the application one, making application deployments faster (and cutting down on lead time).
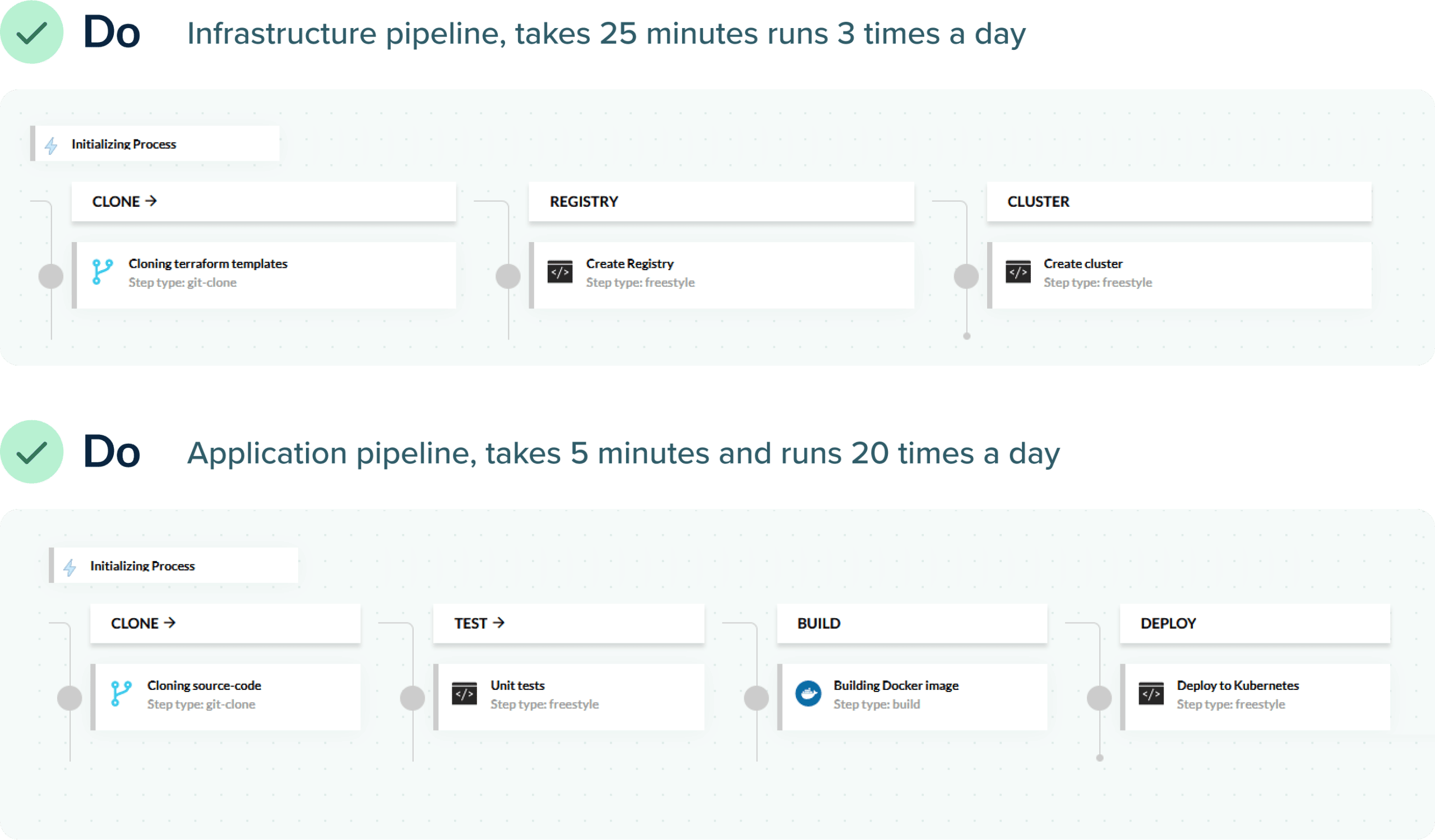
Developers will also know that when the application pipeline breaks, they don’t need to deal with infrastructure errors or care about how the Kubernetes cluster was created. Operators can fine-tune the infrastructure pipeline without affecting developers at all. Everybody can work independently.
We sometimes see this anti-pattern (mixing infrastructure with application) where companies believe that this is the only way forward as the application needs something provided by the infrastructure pipelines.
The classic example is creating something with Terraform and then passing the output of the deployment (e.g. an IP address) to the rest of the pipeline as input to the application code. If you have this limitation it means that you are suffering from the previous anti-pattern (coupling application to the details of the infrastructure) and you need to remove this coupling (i.e. your application code should not need a specific IP address to be deployed).
Notice that the same approach can be expanded to database upgrades. If you use pipelines for database changesets, then they should be independent of the application source code. You should be able to update only the DB schema or only the application code on their own, without having to do both for every deployment.
Anti-pattern 5 – Performing ad-hoc deployments with kubectl edit/patch by hand
Configuration drift is a well known problem that existed even before Kubernetes appeared. It happens when two or more environments are supposed to be the same, but after certain ah-hoc deployments or changes they stop having the same configuration.
As time goes on, the problem becomes even more critical and can result in extreme scenarios where the configuration of a machine is not known any more and has to be reverse-engineered from the live instance.
Kubernetes can also suffer from this problem. The `kubectl` command is very powerful and comes with built-in apply/edit/patch commands that can change resources in place on a live cluster.
Unfortunately this method is easily abused by both cowboy developers and ninja operators. When ad-hoc changes happen in the cluster, they are never recorded anywhere else.
One of the most frequent reasons for failed deployments is environment configuration. A production deployment fails (even though it worked in the staging environment) because the configuration of the two environments is not the same anymore.
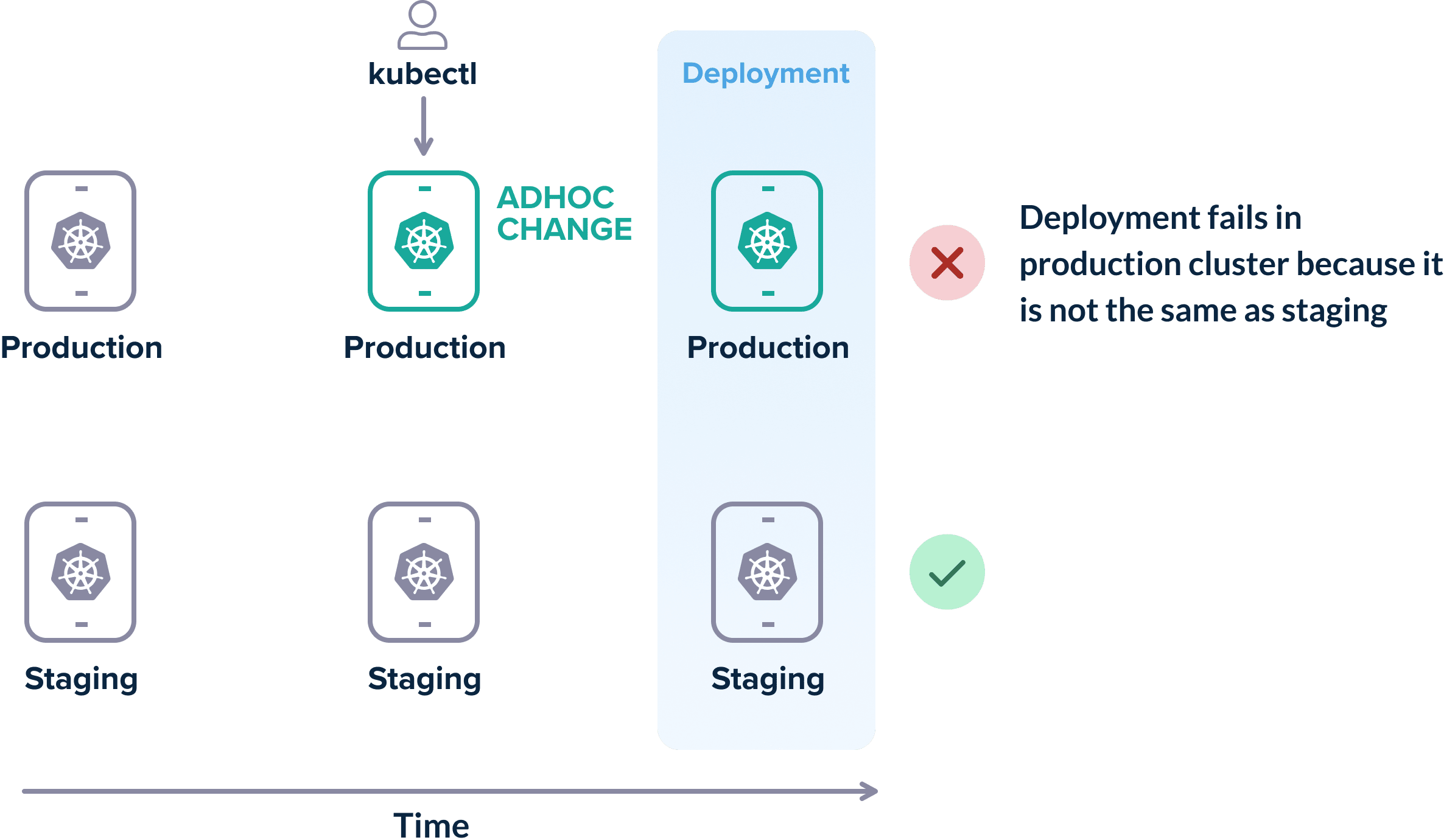
Falling into this trap is very easy. Hotfixes, “quick workarounds” and other questionable hacks are always the main reasons behind ad-hoc changes.
Kubectl should never be used for deployments by hand. All deployments should be taken care of by the deployment platform and ideally should also be recorded in Git following the GitOps paradigm.
If all your deployments happen via a Git commit:
- You have a complete history of what happened in your cluster in the form of Git commit history
- You know exactly what is contained on each cluster at any point in time and how environments differ among themselves
- You can easily recreate or clone an environment from scratch by reading the Git configuration.
- Rolling back configuration is trivial as you can simply point your cluster to a previous commit.
Most importantly, if a deployment fails, you can pinpoint really fast what was the last change that affected it and how it changed its configuration.
The patch/edit capabilities of `kubectl` should only be used for experimentation only. Changing live resources on a production cluster by hand is a recipe for disaster. Apart from having a proper deployment workflow, you should also agree with your time that abusing kubectl in this way should be avoided at all times.
Continued on part 2.
Download the ebook.
Cover photo by Unsplash.
Related Guides:
- What Is GitOps? How Git Can Make DevOps Even Better
- CI/CD: Complete Guide to Continuous Integration and Delivery
- Understanding Argo CD: Kubernetes GitOps Made Simple
Related Products: