
One of the most typical challenges when deploying a complex application is the handling of different deployment environments during the software lifecycle.
The most typical setup is the trilogy of QA/Staging/Production environments. An application developer needs an easy way to deploy to the different environments and also to understand what version is deployed where.
Specifically for Kubernetes deployments, the Helm package manager is a great solution for handling environment configuration. And with the power of Codefresh, you also have access to a visual dashboard for inspecting all your environments on a single screen.
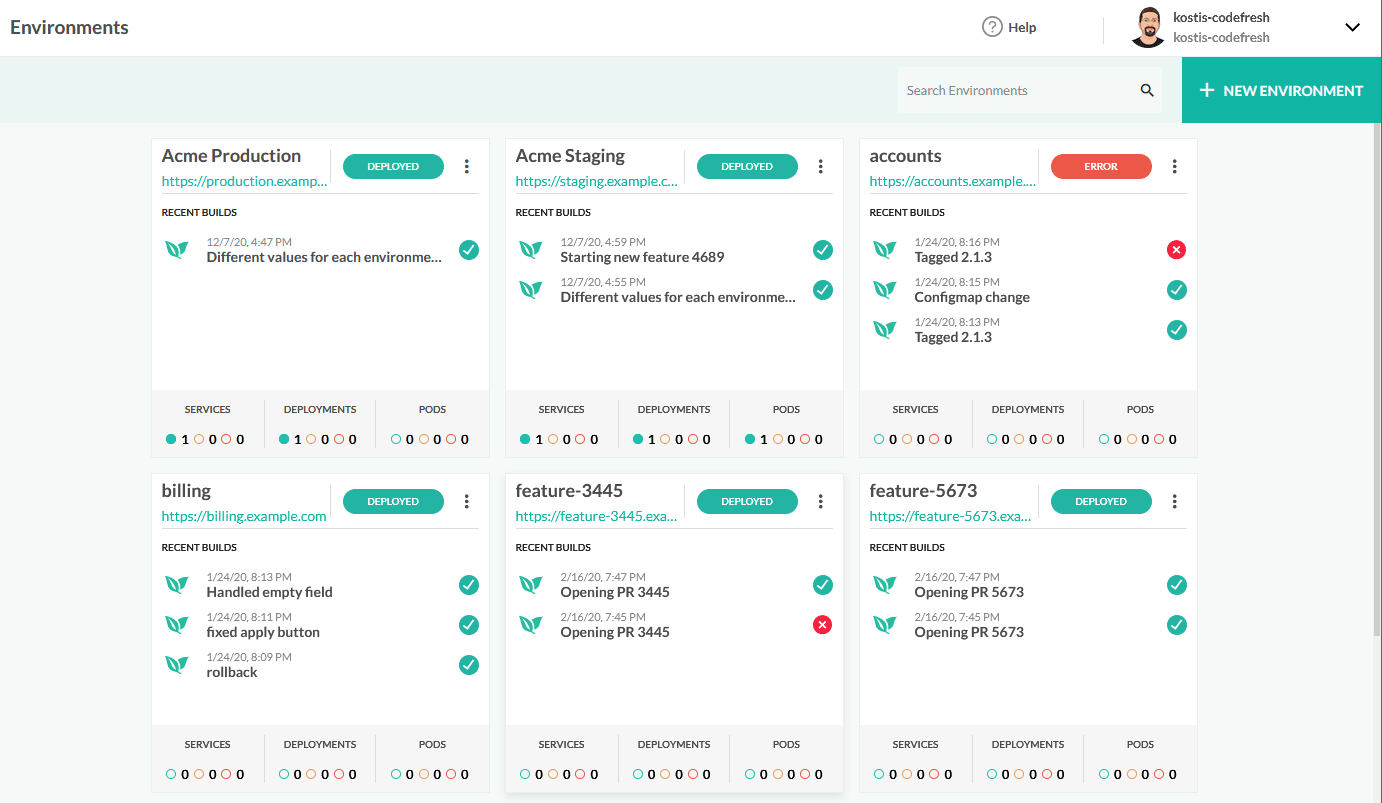
In this guide, we will see how you can deploy an example application to different environments using different Helm values and how to automate the whole process with Codefresh pipelines.
How Helm handles different environment configurations
Helm is the package manager of Kubernetes. Helm packages (called charts) are a set of Kubernetes manifests (that include templates) plus a set of values for these templates.
While normally a Helm chart contains only a single values file (for the default configuration), it makes sense to create different value files for all different environments.
You can find an example application that follows this practice at: https://github.com/codefresh-contrib/helm-promotion-sample-app/tree/master/chart
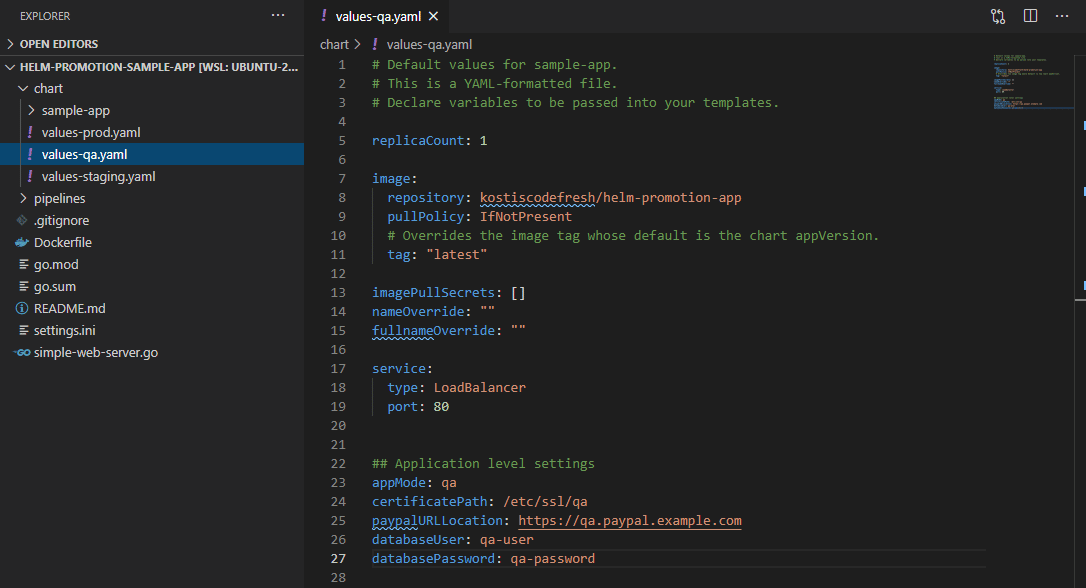
Here we have 3 values files for each environment:
If you look at the values you will see that we have defined both application level properties (e.g. username and password for a database) as well as properties for Kubernetes manifests (e.g. number of replicas).
Manual deployments with Helm
Before automating the deployment, let’s get familiar with how the application looks in different environments by installing it manually with the Helm executable.
Helm is using the same credentials as kubectl for cluster access, so before starting with Helm:
- Obtain access to a Kubernetes cluster (either on the cloud or a local one like microk8s or minikube or Docker for desktop)
- Setup your terminal with a kubeconfig (instructions differ depending on your cluster type)
- Download kubectl and make sure it can connect to the cluster
Feel free also to work with the cloud shell of your cloud provider if available, as it configures everything for you in advance (and in some cases, even Helm is preinstalled).
To verify your local kubeconfig type:
>kubectl get nodes NAME STATUS ROLES AGE VERSION aks-agentpool-36431463-1 Ready agent 55d v1.16.15 aks-agentpool-36431463-2 Ready agent 49d v1.16.15
If everything goes ok you should see a list of nodes that comprise your cluster.
Download the latest version of Helm on your local workstation and verify that it is working correctly by typing
helm ls
You should get an empty report since we haven’t deployed our application yet. Let’s do that now.
First let’s create 3 namespaces, one for each “environment”:
kubectl create namespace qa kubectl create namespace staging kubectl create namespace production
And then deploy the Helm chart on each environment by passing a different values file for each installation:
git clone https://github.com/codefresh-contrib/helm-promotion-sample-app.git cd helm-promotion-sample-app/chart helm install example-qa sample-app -n qa -f values-qa.yaml helm install example-staging sample-app -n staging -f values-staging.yaml helm install example-prod sample-app -n production -f values-prod.yaml
You should now wait a bit so that all deployments come up.
You can see all your deployments with:
>helm ls -A example-prod production 1 deployed sample-app-0.1.0 1.0.0 example-qa qa 1 deployed sample-app-0.1.0 1.0.0 example-staging staging 1 deployed sample-app-0.1.0 1.0.0
Each application also exposes a public endpoint. You can find the IP addresses with:
kubectl get svc -A
Look under the “external-ip” column. Open the respective URL in your browser and you will see how the application looks on each environment:

To uninstall your app you can also use Helm like below:
helm uninstall example-staging -n staging helm uninstall example-prod -n production helm uninstall example-qa -n qa
Note that if you are using a cloud Kubernetes cluster, the load balancers used in the apps cost extra, and it is best to delete your apps at the end of this tutorial.
You should also remove the namespaces if you want to clean-up your cluster completely.
Using Helm values in Kubernetes manifests
Now that you have seen how the application looks in each environment, we can dive into the details on how the Helm values are actually used.
For the values that deal with the Kubernetes cluster, the process is straightforward. Helm includes a templating mechanism that allows you to replace common properties in Kubernetes manifests.
As an example, the number of replicas of the application is parameterized.
apiVersion: apps/v1
kind: Deployment
metadata:
[...]
spec:
replicas: {{ .Values.replicaCount }}
Here we pass the replicaCount parameter to the deployment YAML.
You can see the definition of replicaCount inside the values YAML for each environment. For example, the production environment defines 2 replicas, while the QA and staging environments have only one.
For more information on templates see the Helm documentation page.
This explains the templating capabilities of Helm for Kubernetes manifests. But how do we pass values to the application itself?
Using Helm values in application code
There are many ways to pass values to an application, but one of the easiest ones is using plain files (for a small number of values you could also use environment variables.
The format of the file depends on your programming language and framework. Some popular solutions are Java properties, .env files, Windows INI, and even JSON or YAML.
The example application uses the INI file format and searches for the file /config/settings.ini. Here is an example of the file:
# possible values: production, development, staging, QA app_mode = development [security] # Path to SSL certificates certificates = /etc/ssl/dev [paypal] paypal_url = https://development.paypal.example.com [mysql] db_user = devuser db_password = devpassword
These settings are all dummy variables. They are not actually used in the application, they are only shown in the http response as plain text.
This means that once the application is deployed to the cluster, we need to provide a file in this format in the /config/settings.ini path inside the container.
There are many ways to do that in Kubernetes (init containers, volumes) but the simplest one is via the use of configmaps. A config map is a configuration object that holds specific variables that can be passed in the application container in multiple forms such as a file or as environment variables. In our case, we will use a configmap-passed-as-file as this is what our application expects.
Here is the content of our configmap.
apiVersion: v1
kind: ConfigMap
metadata:
name: application-settings
data:
settings.ini: |
# possible values : production, development, staging, qa
app_mode = {{ .Values.appMode }}
[security]
# Path to SSL certificates
certificates = {{ .Values.certificatePath }}
[paypal]
paypal_url = {{ .Values.paypalURLLocation }}
[mysql]
db_user = {{ .Values.databaseUser }}
db_password = {{ .Values.databasePassword }}
As you can see, because the configmap is part of the Helm chart, we have the capability to template the values of the configmap like any other Kubernetes manifest. Notice also that this configmap is named as application-settings (we will use this name later in the deployment).
The last piece of the puzzle is to tell Kubernetes to “mount” the contents of this configmap as a file at /config. Here is the part of the deployment YAML that does this:
containers:
[...]
volumeMounts:
- name: config-volume
mountPath: /config
[..]
volumes:
- name: config-volume
configMap:
name: application-settings
Now that we have seen all the pieces of the puzzle you should understand what happens behind the scenes when you deploy the application.
- Helm is gathering all the Kubernetes manifests (deployment + configmap+ service) along with the respective values file
- The properties that contain templates are replaced with their literal values. This also includes the configmap
- The resulting manifests are sent to Kubernetes by Helm
- Kubernetes is looking at the deployments and sees that it requires an extra configmap to be passed as a file
- The contents of the configmap are mounted at /config/settings.ini inside the application container
- The application starts and reads the configuration file (unaware of how the file was written there)
Using the Environment dashboard
Codefresh contains several graphical dashboards that allow you to get an overview of all your Helm releases and their current deployment status.
For this particular case, the Environment dashboard is the most helpful one, as it shows you the classical “box” view that you would expect.
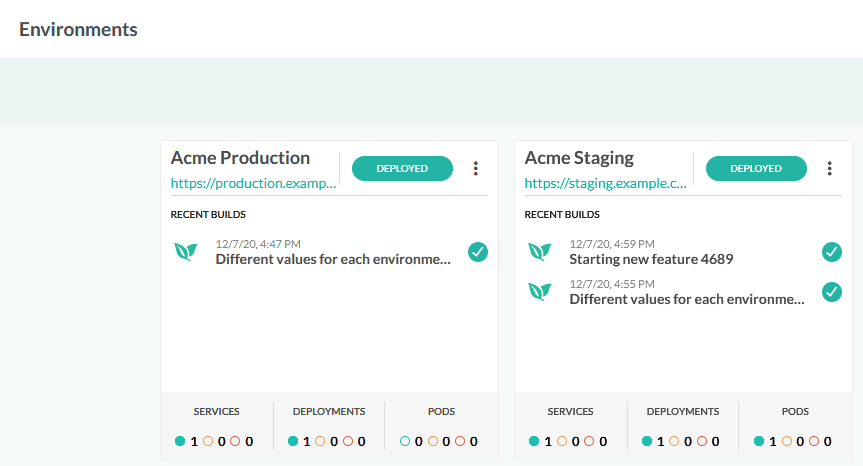
You can manually create entries in this dashboard by adding a new environment and pointing Codefresh to your cluster and the namespace of your release (we will automate this part as well with pipelines in the next section).
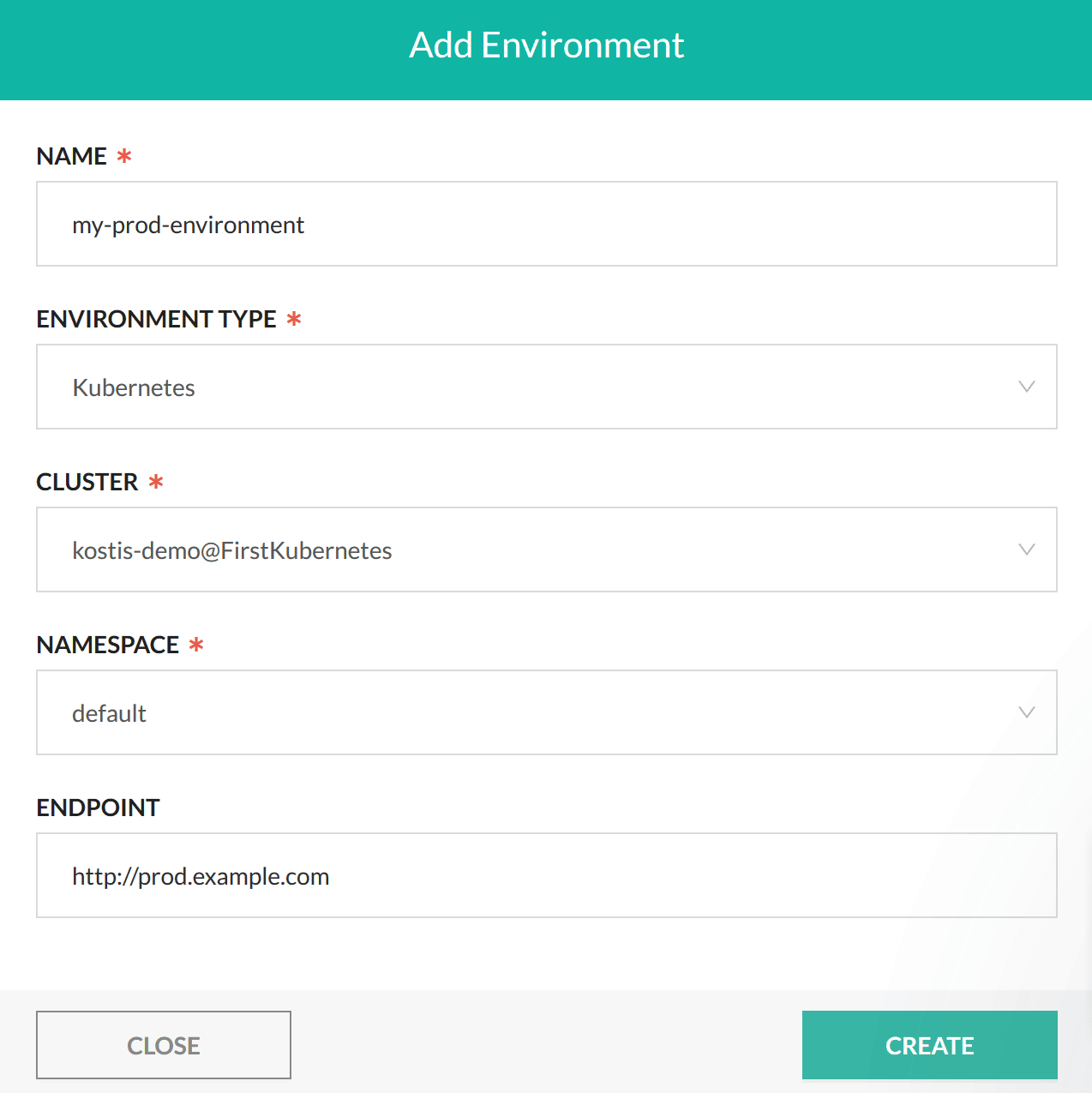
For more information on using the environment dashboard see the documentation page.
Automating deployment to different environments with Codefresh pipelines
Using manually the helm executable to deploy our application is great for experimentation, but in a real application, you should create a pipeline that automatically deploys it to the respective environment.
There are many ways to deploy in multiple environments and your own process will depend on your team and your organizational needs. Some popular workflows are:
- Using a single pipeline that deploys the master branch to production and all other non-master branches to staging and/or QA
- Using a single pipeline that deploys all commits to staging and then waiting for manual approval. If approval is granted the commit is also deployed to production
- Using multiple pipelines where one pipeline is responsible for production deployments only and another pipeline is deploying staging releases on a regular schedule (a.k.a. Nightly builds)
- Using multiple pipelines where one pipeline is deploying to production for the master branch and other pipelines are deploying to QA/stating only when a Pull request is created
There are more possibilities and all of them are possible with Codefresh. For our example we will focus on the first case, a single pipeline that depending on the branch name will deploy the application to the respective environment. Here is the graphical view:
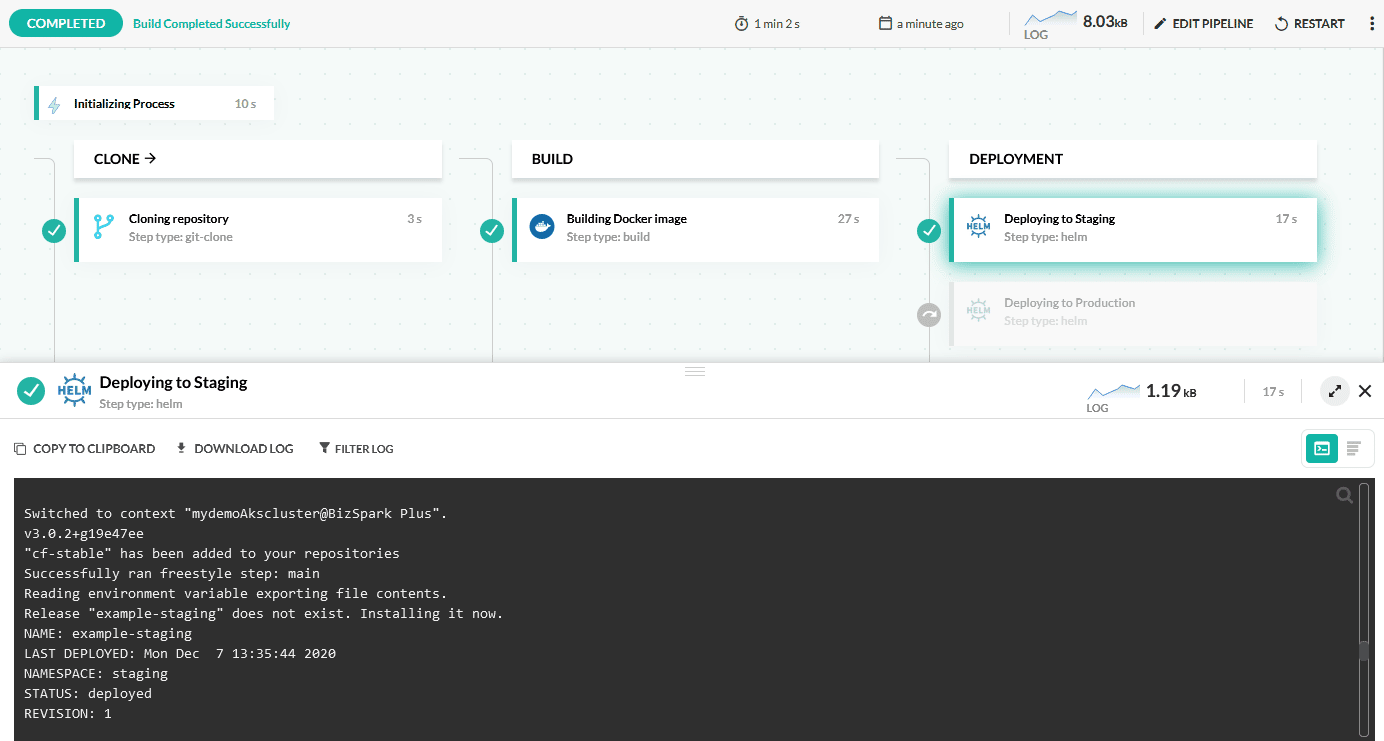
And here is the pipeline definition:
version: "1.0"
stages:
- "clone"
- "build"
- "deployment"
steps:
clone:
title: "Cloning repository"
type: "git-clone"
repo: "codefresh-contrib/helm-promotion-sample-app"
revision: '${{CF_REVISION}}'
stage: "clone"
build:
title: "Building Docker image"
type: "build"
image_name: "kostiscodefresh/helm-promotion-app"
working_directory: "${{clone}}"
tags:
- "latest"
- '${{CF_SHORT_REVISION}}'
dockerfile: "Dockerfile"
stage: "build"
registry: dockerhub
deployStaging:
title: Deploying to Staging
type: helm
stage: deployment
working_directory: ./helm-promotion-sample-app
arguments:
action: install
chart_name: ./chart/sample-app
release_name: example-staging
helm_version: 3.0.2
kube_context: 'mydemoAkscluster@BizSpark Plus'
namespace: staging
custom_value_files:
- ./chart/values-staging.yaml
when:
branch:
ignore:
- master
env:
name: Acme Staging
endpoints:
- name: app
url: https://staging.example.com
type: helm-release
change: ${{CF_COMMIT_MESSAGE}}
filters:
- cluster: 'mydemoAkscluster@BizSpark Plus'
releaseName: example-staging
deployProd:
title: Deploying to Production
type: helm
stage: deployment
working_directory: ./helm-promotion-sample-app
arguments:
action: install
chart_name: ./chart/sample-app
release_name: example-prod
helm_version: 3.0.2
kube_context: 'mydemoAkscluster@BizSpark Plus'
namespace: production
custom_value_files:
- ./chart/values-prod.yaml
when:
branch:
only:
- master
env:
name: Acme Production
endpoints:
- name: app
url: https://production.example.com
type: helm-release
change: ${{CF_COMMIT_MESSAGE}}
filters:
- cluster: 'mydemoAkscluster@BizSpark Plus'
releaseName: example-prod
The pipeline has 4 steps
- A clone step that fetches the code from git when a commit is pushed
- A build step that creates a docker image and pushes it a registry
- A Helm deploy step that deploys to production if the branch is “master”
- A Helm deploy step that deploys to “staging” if the branch is not “master”
The last two steps use pipeline conditionals, so only one of them will be executed according to the branch name. They also define which environments are affected in the environment dashboard.
If you start committing and pushing to the different branches you will see the appropriate deploy step executing (you can also run the pipeline manually and simply choose a branch by yourself).
For alternative workflows regarding environment deployments see the documentation page.
Moving from predefined environments to dynamic environments
As you have seen, using helm for different environments is straightforward and trivial to automate with Codefresh pipelines. But can we improve the process any further?
Using predefined environments is the traditional way of deploying applications and works well for several scenarios. Given the elastic nature of Kubernetes however, static environments are not always cost-effective.
A more advanced practice would be to have dynamic environments (apart from production) that are created on-demand when a Pull Request is opened and torn down when a pull request is closed. We will see this scenario in our next tutorial.
New to Codefresh? Create Your Free Account today!