
In our extensive guide of best ci/cd practices we included a dedicated section for database migrations and why they should be completely automated and given the same attention as application deployments. We explained the theory behind automatic database migrations, but never had the opportunity to talk about the actual tools and give some examples on how database migrations should be handled by a well disciplined software team.
In this article we will dive into database migrations for Kubernetes microservices and also explain why traditional database techniques are no longer applicable when working with Kubernetes native applications.\
Rethinking database migration techniques
The traditional way of performing database migrations is during application startup. This is a very popular database pattern and popular programming languages support it natively via dedicated frameworks and libraries such as liquibase, rails:migrate, django:migrate etc.
This technique might work effectively for monolithic applications that are deployed infrequently, but is very problematic for Kubernetes microservices. As a starting point, Kubernetes services are often launched in groups/replicas, so having multiple applications trying to migrate the same database at the same time is a recipe for trouble.
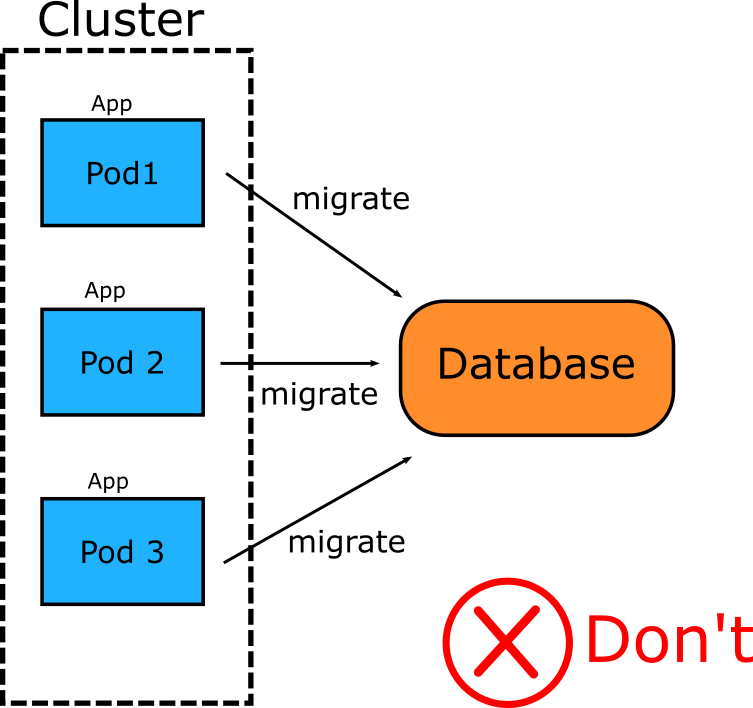
But the most important issue is how database failures are handled. Database migrations can (and often do) fail. By linking the database migration to application startup, you now have a bunch of containers in your clusters that not only have failed completely, but also stopped serving traffic. This causes downtime to your users and breaks one of the basic premises of Kubernetes which is minimized downtime because of rolling updates.
There is also the matter of security which is especially critical for financial organizations or other companies that are highly regulated. One of the best practices for containers is to make them as simple as possible in order to minimize their attack surface. Including database upgrade tools in your production deployments goes against this advice. Additionally, most databases have different roles/privileges for database commands that change the schema versus database commands that simply read/write data.
Even if you account for all these issues, the core mechanism behind a Kubernetes cluster is the scheduler which at any point in time can decide to kill your pods and provision them in a different node. This operation should be fast and completely seamless to end users. Forcing the pod to run database migrations first will result in a hit in performance (even if all tables have already been migrated). The performance hit will be evident when multiple containers need to run migrations in parallel, in which case, due to mutual exclusion essentially they will boot sequentially (which makes it “O(n)” of the number of containers booting).
It should be obvious that in the case of Kubernetes microservices we need to decouple database migrations from application startup. In fact, we should treat database migrations as a standalone entity that has its own lifecycle which is completely unrelated to the source code. This was already a good practice (even before Kubernetes) and can easily be achieved if all database migrations are forwards/backwards compatible with the application code.
Creating a separate lifecycle for database migrations
Let’s see an actual example. We will use:
- Migration statements in SQL format stored in a Git repository
- A PostgreSQL database hosted in ElephantSQL
- Codefresh as a CI/CD system
- Atlas as the migration engine
Atlas is an open source DB migration tool that natively supports PostgreSQL as a deployment target. Apart from direct SQL migrations it also has the capability to perform declarative migrations using a language very similar to Hashicorp HCL. You can find more information about its capabilities in the official documentation.
The first step is to create a Docker image that contains the SQL files for our application plus the Atlas migration engine. Atlas already offers a public dockerhub image that we can use as base
FROM arigaio/atlas:latest-alpine as atlas FROM alpine:3.17.3 WORKDIR / COPY --from=atlas /atlas . RUN chmod +x /atlas COPY migrations /migrations
Here we create a Docker image that contains the “migrations” folder from the Github repository and also bundles the Atlas executable. Atlas is written in Go, and therefore is very easy to package and distribute as there is only a single file for the whole engine (Liquibase for example requires a JDK).
Once we have the Dockerfile, we can create a very simple Codefresh pipeline (or reuse an existing build/push pipeline) that updates our PostgreSQL DB to the latest schema:
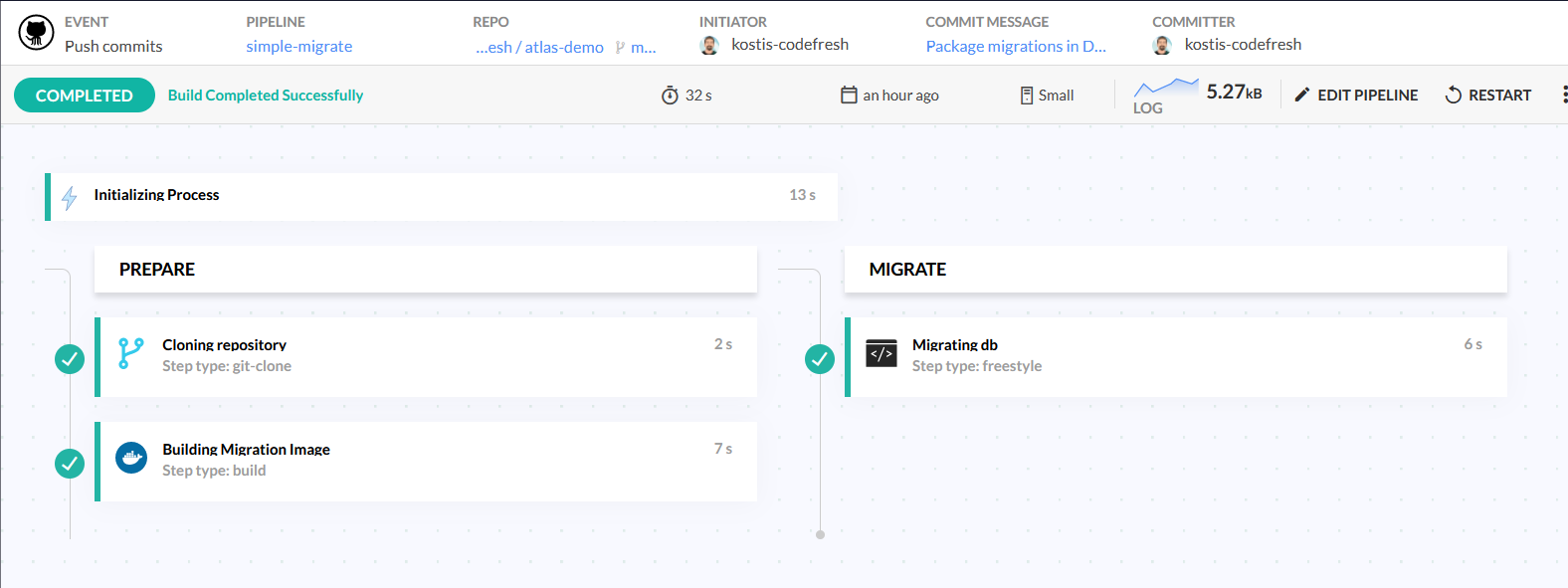
This Codefresh pipeline:
- Checks out the Github repo that contains the SQL migration files
- Builds the dockerfile packaging all SQL files with the Atlas migration engine
- Uses the docker image that was just built to apply the changes to our database
Here is the pipeline definition.
# More examples of Codefresh YAML can be found at
# https://codefresh.io/docs/docs/yaml-examples/examples/
version: "1.0"
# Stages can help you organize your steps in stages
stages:
- "prepare"
- "migrate"
steps:
clone:
title: "Cloning repository"
type: "git-clone"
repo: "kostis-codefresh/atlas-demo"
# CF_BRANCH value is auto set when pipeline is triggered
# Learn more at codefresh.io/docs/docs/codefresh-yaml/variables/
revision: "master"
git: "github-1"
stage: "prepare"
build_migration_image:
title: Building Migration Image
type: build
image_name: my-migrations
disable_push: true
working_directory: ${{clone}}
tag: 'latest'
dockerfile: Dockerfile
stage: "prepare"
migrate:
title: "Migrating db"
type: "freestyle" # Run any command
image: ${{build_migration_image}} # The image in which command will be executed
working_directory: "${{clone}}" # Running command where code cloned
commands:
- /atlas migrate apply -u "$DB_URL"
stage: "migrate"
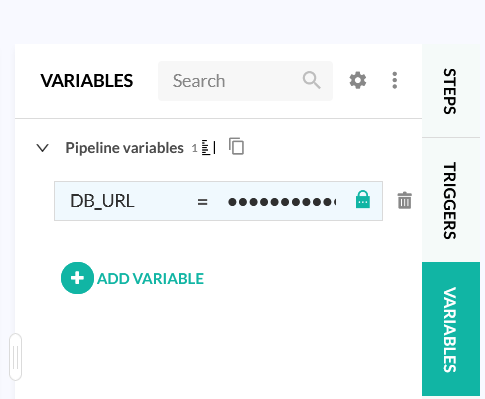
The pipeline expects a database in the DB_URL environment variable that we must provide in the pipeline settings (the value can be fetched from the ElephantSQL UI)
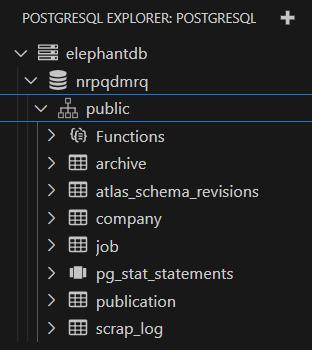
We can run the pipeline and see the database migrated. You can use any DB dashboard (or even the PSQL UI) to verify the tables. Here is an example from VScode.
We have now created a pipeline specifically for database migrations! Here are some important points to consider:
- The pipeline deals only with database migrations and nothing else. It is not tied in any way to the application startup workflow.
- When you created the pipeline a Git trigger was also created automatically by Codefresh. If you change the SQL files, then it will automatically run again to bring the DB to the new schema
- Atlas also created an internal table called “atlas_schema_revisions” which tracks which SQL files have been applied and which have not. If you run the pipeline multiple times, Atlas will detect that everything matches Git and it will take no action.
- The docker image that we created can be used with any solution that uses containers and not just Codefresh. It could also be used in a Kubernetes Job or an Argo CD pre-sync job
We have achieved our goal (decoupling db upgrades from application deployments) but we can improve the process even further. Let’s see what other tricks Atlas has.
Previewing SQL migrations with a temporary database
Anybody who has worked with raw SQL statements knows that applying them in a database (especially in production) can often present errors and failures for various reasons (syntax errors, db constraints, wrong validations etc).
The pipeline we created in the previous section will work great in the perfect situation where no errors are happening, but will leave our database in an inconsistent state if any of the SQL files cannot be applied.
Atlas has a great feature where you can verify the safety of your SQL statements in a secondary database. If this database is present it will apply the migrations there first and only if they succeed it will apply them to the “main” database. This will allow us to catch early any errors before they reach our “production” DB (which in our case is the live instance hosted by ElephantSQL). Normally you would run this process in CI for Pull requests, but for brevity reasons (and as an extra safeguard) let’s do it in the main pipeline .
The verification process does the following:
- Checks the syntax of the migration files
- Simulates the upgrade process to ensure replayability
- Checks for conflicts within migrations
- Detects breaking (or destructive) changes
Here is our updated pipeline:
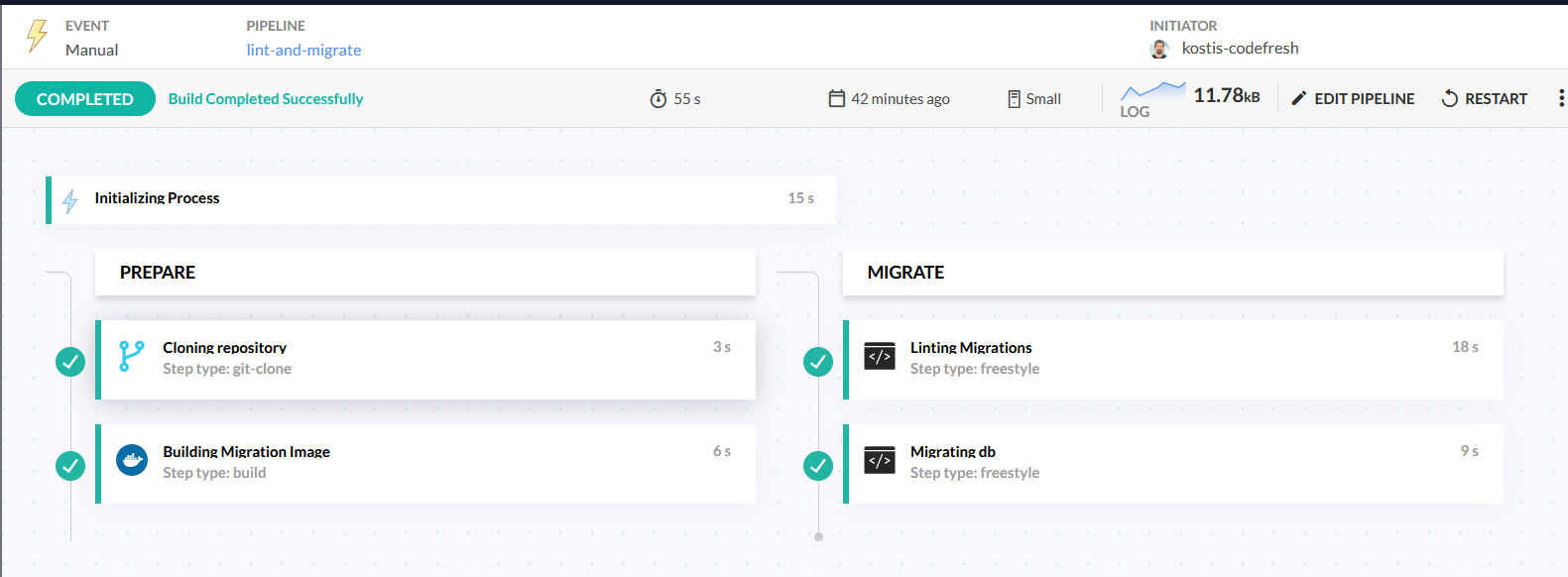
There is now a new step called “Linting migrations” with the following definition
preview:
title: "Linting Migrations"
type: "freestyle" # Run any command
image: ${{build_migration_image}} # The image in which command will be executed
working_directory: "${{clone}}" # Running command where code cloned
commands:
- /atlas migrate lint --latest 1 --dev-url "postgres://root:admin@postgres/demo?search_path=public&sslmode=disable"
stage: "migrate"
services:
composition:
postgres:
image: postgres:11.5
ports:
- 5432
environment:
- POSTGRES_USER=root
- POSTGRES_PASSWORD=admin
- POSTGRES_DB=demo
readiness:
timeoutSeconds: 30
periodSeconds: 15
image: postgres:11.5
commands:
- "pg_isready -h postgres"
Here we take advantage of service containers, a Codefresh feature that allows you to launch a custom container within the context of a pipeline. We launch a PostgreSQL database (same version as that found in ElephantSQL) and define a custom username/password. We also check that the database is actually ready (with the pg_isready command) before we pass it to Atlas.
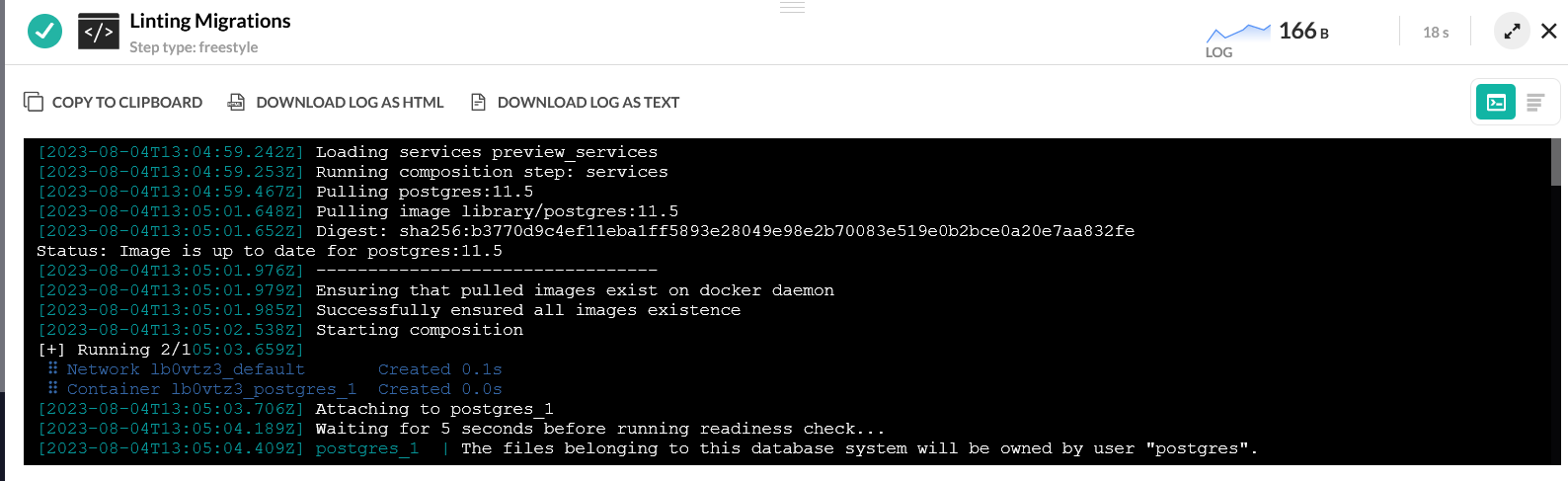
We then call Atlas with the –dev-url parameter that defines this temporary database. Atlas will now apply all the migrations first in the preview database and only if everything was successful it would continue with the real database. Note that “latest 1” will only scan the latest file. The lint command has several more options.
The important point here is that Codefresh will automatically launch the preview database before this step and will tear it down after Atlas is finished with it. There is no other cleanup action you need to take on your own. You can see the status of the DB itself in the dedicated window in the Codefresh UI.
We have now strengthened our database migration workflow. Not only it is completely independent from application deployments, but it also guards us against syntax errors and other misconfigurations.
Getting full visibility in Database migrations using Atlas cloud
The combination of Codefresh and Atlas is very powerful as it gives you a complete system for deploying both application code and database migration. In a big enterprise environment however, most teams would also have the need of getting more visibility into the state of the database for each migration
Wouldn’t it be nice if you could also
- See a graphical overview of the schema of your migrations?
- See how each SQL file affects the schema?
- Understand which pipelines affect a database and which just validate SQL statements?
- Get an overview of all database migrations across all your databases and pipelines (even outside of CI?)
- Get a slack notification when someone is about to change the schema?
This is where Atlas Cloud comes in. Atlas cloud is a SaaS solution that integrates natively with the Atlas CLI. It can easily supercharge your DB migration skills and offer you full traceability on how your databases evolve over time with each application deployment.
You can sign up at https://auth.atlasgo.cloud/signup. Once you have an account you need to perform the following tasks
- Create a bot token so that Codefresh can notify Atlas about new DB deployments
- Add your Github repository as a migration directory so that Atlas knows where your SQL files are stored. Name your directory as “demo”.
We are now ready to define an Atlas cloud configuration file.
variable "cloud_token" {
type = string
default = getenv("ATLAS_TOKEN")
}
atlas {
cloud {
token = var.cloud_token
}
}
data "remote_dir" "migration" {
name = "demo"
}
env {
name = atlas.env
url = getenv("DATABASE_URL")
migration {
dir = data.remote_dir.migration.url
}
}
This configuration file should also be included in the Dockerfile. We will now modify our Codefresh pipeline as below:
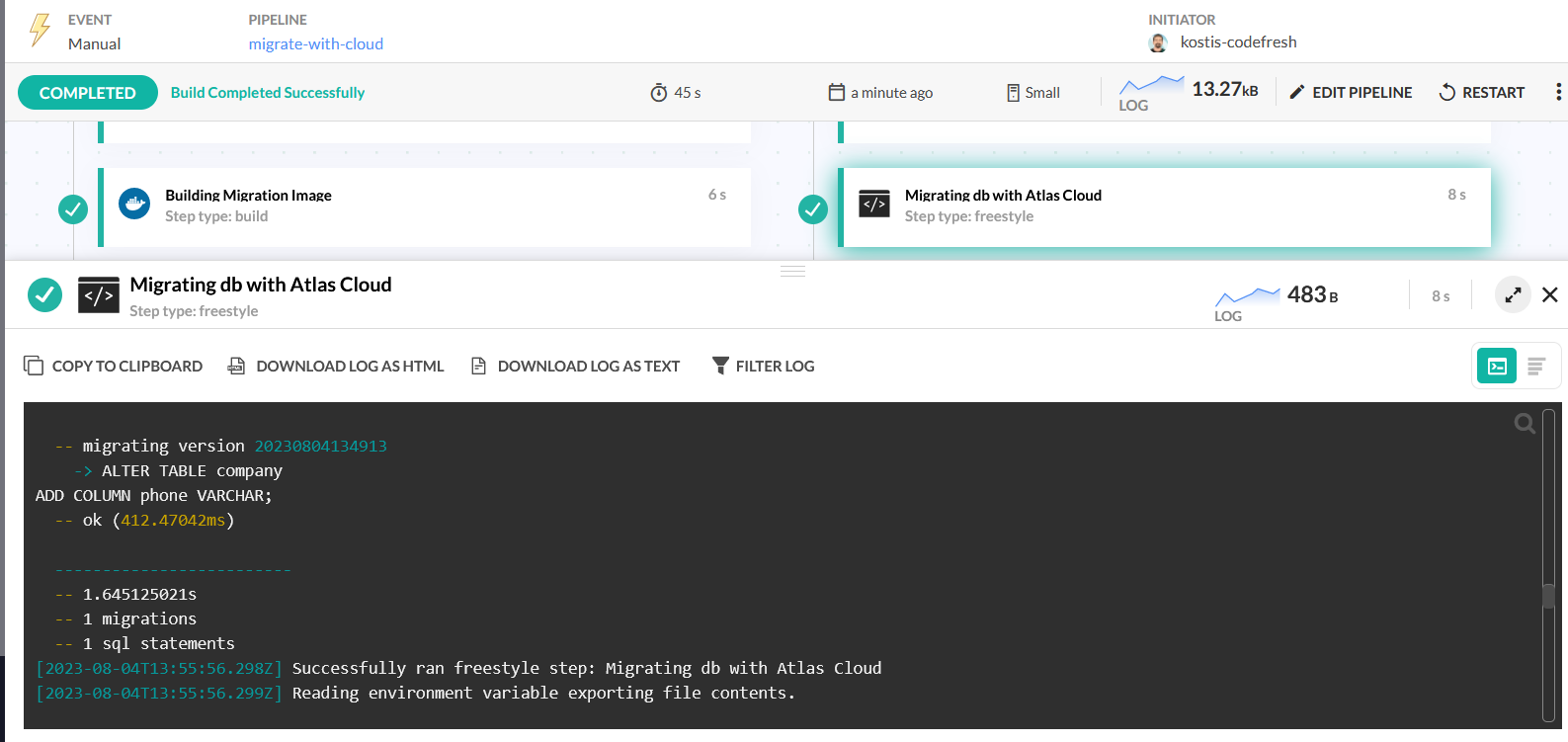
We changed the definition of the YAML step to the following:
migrate:
title: "Migrating db with Atlas Cloud"
type: "freestyle" # Run any command
image: ${{build_migration_image}} # The image in which command will be executed
working_directory: "${{clone}}" # Running command where code cloned
commands:
- /atlas migrate apply --env codefresh
stage: "migrate"
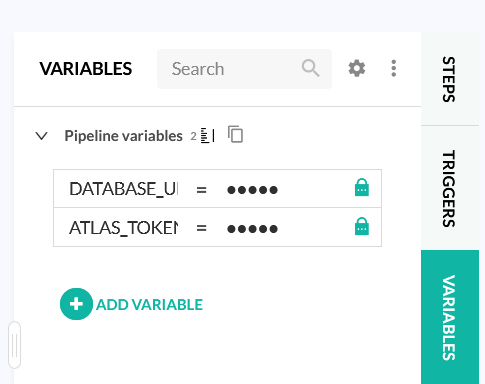
We also define our two new variables as defined in the Atlas configuration file. One variable is the same as before (the ElephantSQL instance) and the other one is the bot token you created in the Atlas Cloud UI.
If you run the pipeline again, the database will be migrated to the schema (the end result is the same). But you can now visit Atlas cloud and get access to a lot more information than Codefresh can provide.
First of all you get a list of database deployments, so you can easily see which database was affected by each pipeline.
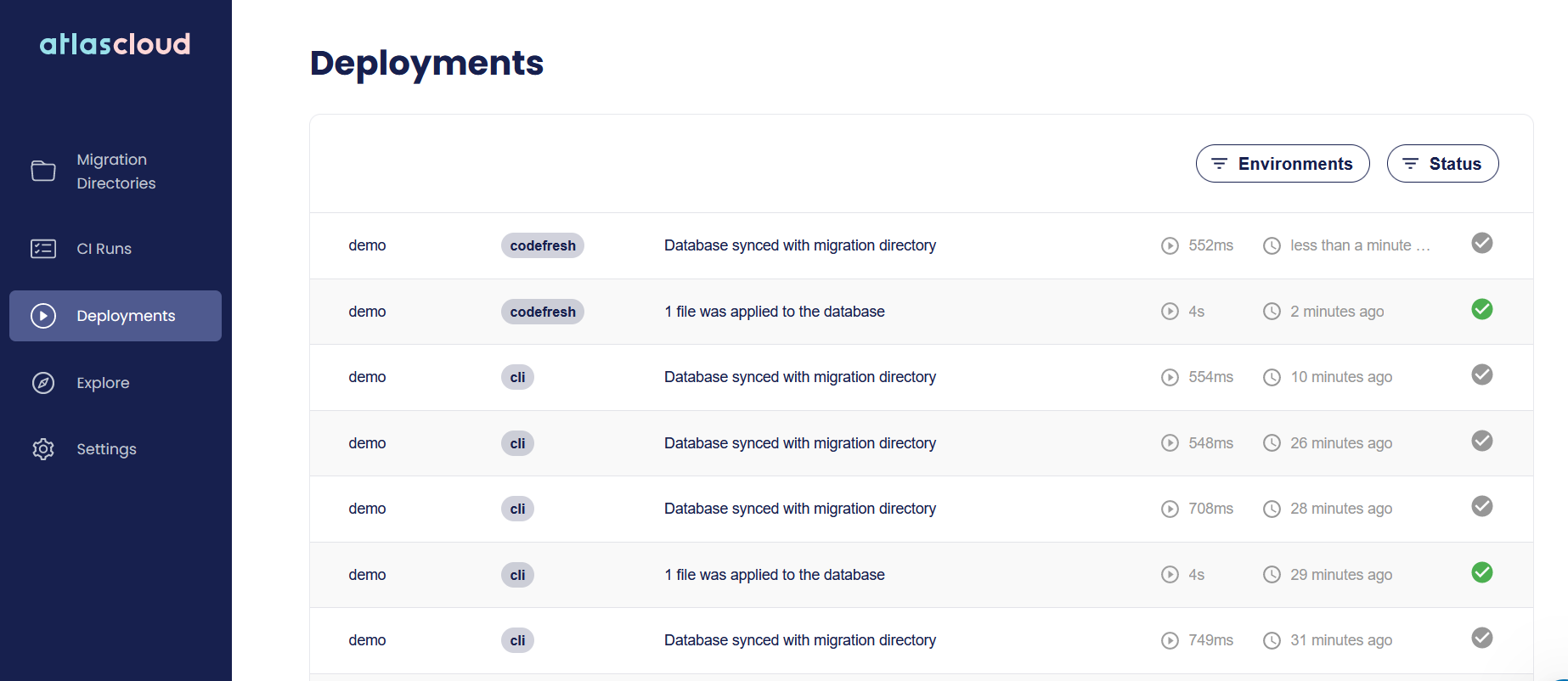
Clicking on a deployment will also show you what happened with the Database. Notice that the deployment screen aggregates all database migrations and not just those from Codefresh.
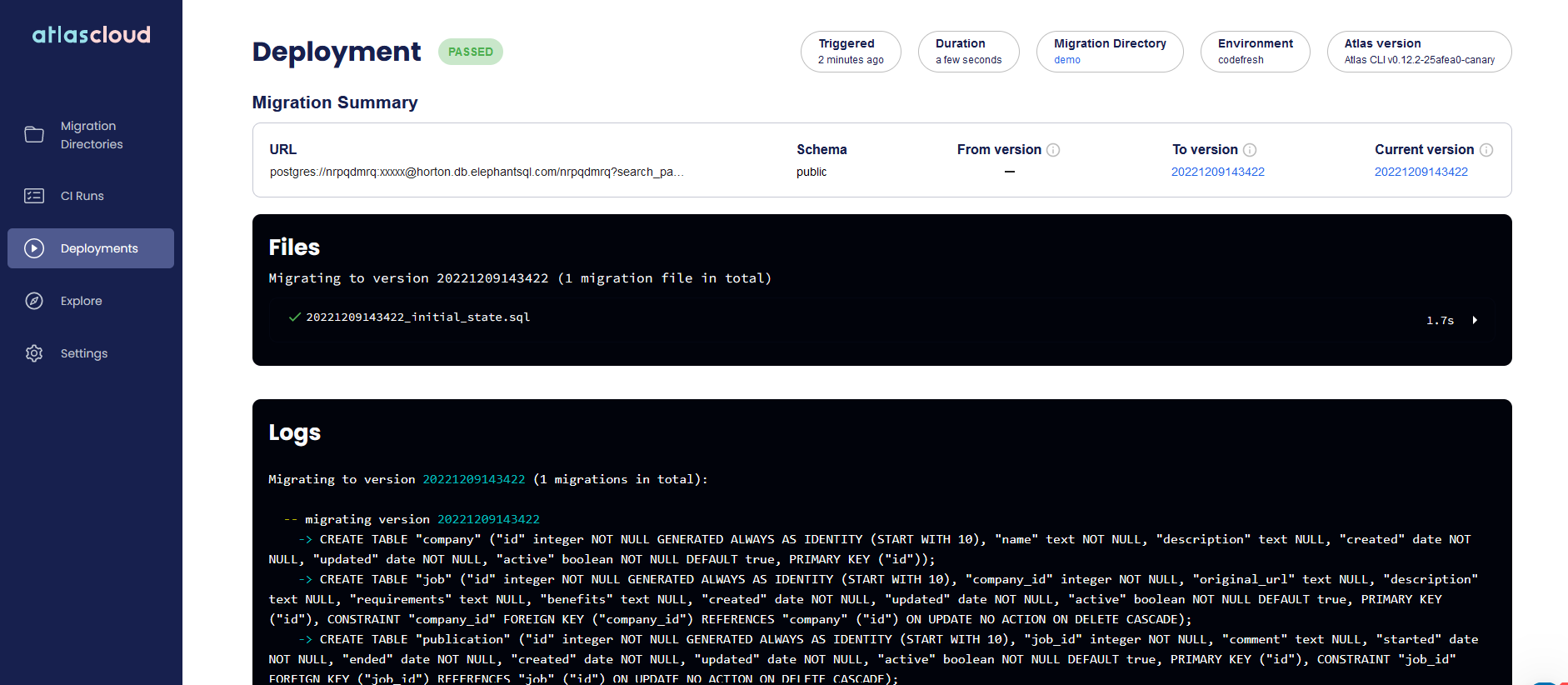
But the killer feature of Atlas cloud is that now you can get a graphical representation of your schema and also see how it changes over time.
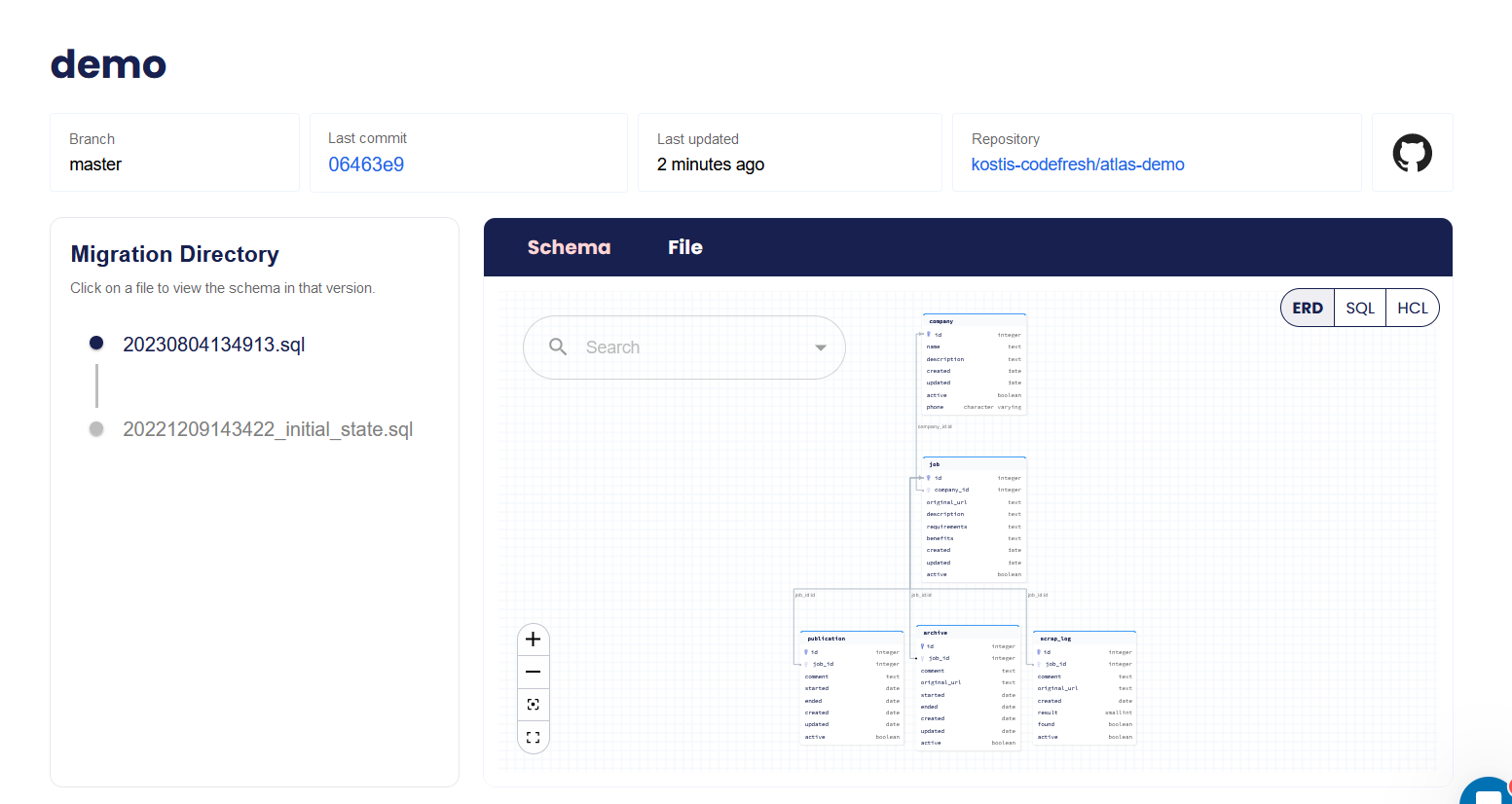
This is a very powerful feature as you can click on each changeset and go backwards and forwards in time to see how your schema looked at each iteration.
Finally, now that Atlas Cloud knows where your migrations live, it will automatically perform some basic checks when you update them with a Git commit.
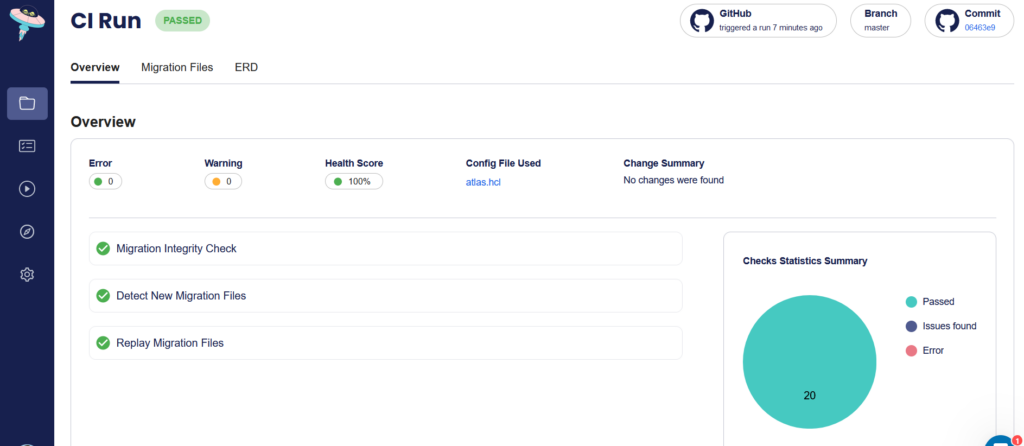
Atlas cloud works also with any CI system and not just Codefresh.
Moving your databases in the Kubernetes era
In this article we have explained that you need to treat your database migrations in a different way than with monolithic applications and how Kubernetes microservices change the assumptions of using application startup as a migration mechanism.
We have also seen how you can decouple completely database migrations from application deployments using Codefresh pipelines and the Atlas migration engine. Finally we have seen how Atlas cloud can offer even more visibility in how your database schema evolves over time.
In the next articles of the series we will introduce the new Kubernetes operator that will finally move your database migrations in the GitOps World. We will also see other advanced workflows such as db rollbacks, cloning production DBs and more.
Learn more about Atlas cloud. If you are not using Codefresh yet, get started today by creating an account and we would love to hear from you!
Photo by Pascal Meier on Unsplash