
In the previous article in this series, we explained how Argo CD application Sets work and how to use them for organizing your applications in different environments or groups. We received a lot of positive feedback from our readers, and many teams now use the associated Git repository as a starting point for their own Argo CD setup.
Even though we covered Application Sets, and more specifically the Git generator, we never explained how to assign different applications to different clusters. This is a common question from teams managing multiple clusters with different application settings per environment.
In this article, we complete the Application Set puzzle and analyze:
- How to decide which application goes to which cluster
- How to have different application settings per environment
- How to split your clusters into different groups with cluster labels
- How to combine the Argo CD Git Generator with the Cluster generator
- How you can simplify your day-to-day operations using cluster labels.
For more details, we’ve again included an example Git repository.
Managing multiple Kubernetes clusters with Argo CD
Argo CD ApplicationSets let you automate your Application manifests in Argo CD. If you adopt ApplicationSets, you no longer need to deal with individual Argo CD applications’ YAML. You can simply point Argo CD to your clusters and folders, and all the possible combinations get created on the fly for you.
We’ve already seen that you can use ApplicationSets to deploy multiple applications on a single cluster.
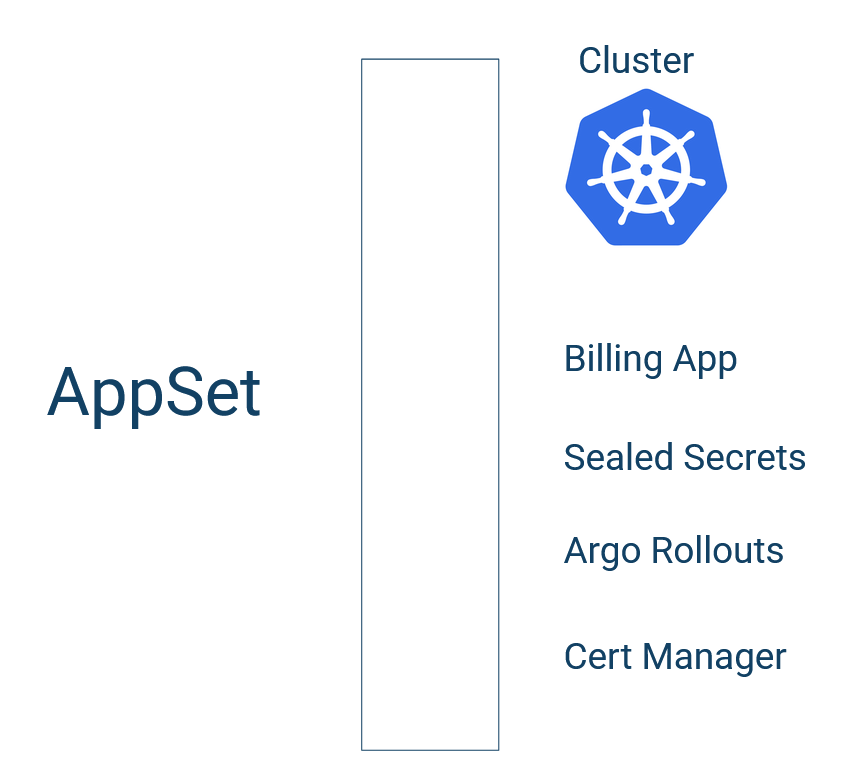
We’ve also seen the other dimension—how to deploy the same application to different clusters:
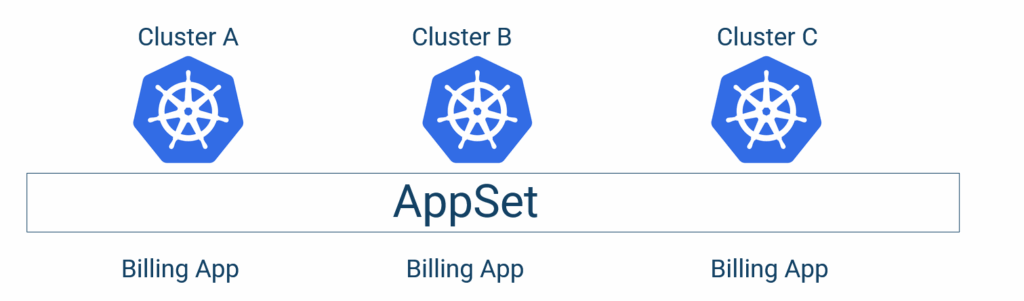
In this guide, we cover the most complex scenario where we have multiple applications and multiple clusters.
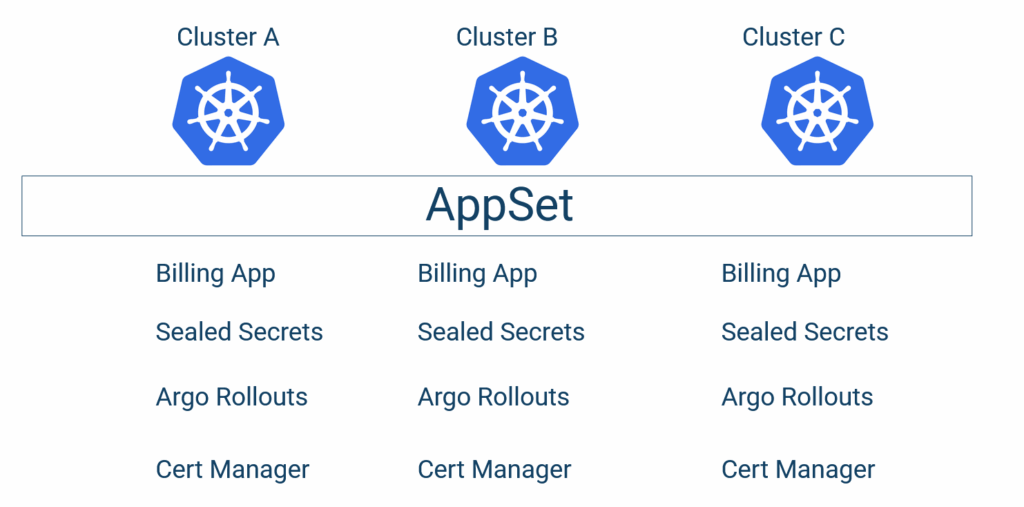
To achieve this scenario, we need to use the Cluster Generator of Argo CD. This means you need to connect all your clusters to a single Argo CD instance. This is the hub-and-spoke setup of Argo CD. See our Argo CD architecture guide for different configurations and the advantages and disadvantages of each one.
Using a combination of the cluster and the Git generator, we can create a 2-dimensional matrix of all the pairs (cluster-app) and have Argo CD deploy everything with a single file.
This approach is a great starting point, but in a real organization, we need 2 more capabilities:
- The ability to enable/disable some applications for some clusters
- The ability to have different configurations (for example, Helm values) according to the cluster the application belongs to.
The final result is not a full 2-D matrix because some applications won’t exist in all environments. We want to achieve this:
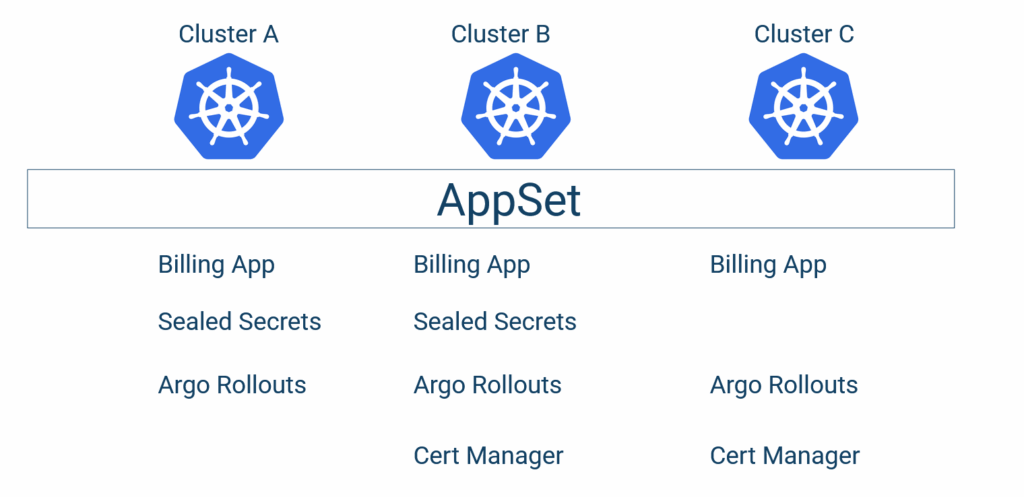
In the example above, Sealed Secrets is NOT present in Cluster C. And the Cert manager is not present in Cluster A. In addition, the “Billing Application” needs to have a different configuration for each cluster.
So, can we achieve these requirements with Application Sets?
Anti-pattern – Creating Snowflake servers with ad-hoc combinations
When faced with the problem of distributing different applications to different clusters, many teams jump straight into very complex solutions that combine multiple Application Set generators. Unfortunately, most hard code custom combinations in the application set files.
A classic example of this approach is trying to individually enable/deactivate a specific application for a particular cluster. We advise AGAINST using such Application Set structures.
## DO NOT DO THIS
- merge:
mergeKeys:
- app
generators:
- list:
elements:
- app: external-dns
appPath: infra/helm-charts/external-dns
namespace: dns
- app: argocd
appPath: infra/helm-charts/argocd
namespace: argocd
- app: external-secrets
appPath: infra/helm-charts/external-secrets
namespace: external-secrets
- app: kyverno
appPath: infra/helm-charts/kyverno
namespace: kyverno
- list:
elements:
- app: external-dns
enabled: "true"
- app: argocd
enabled: "true"
- app: external-secrets
enabled: "false"
- app: kyverno
enabled: "true"
selector:
matchLabels:
enabled: "true"
This file creates snowflake/pet servers where you need to define exactly what they contain. The final result is brittle, requiring significant effort when any major change happens. There are several challenges with this setup:
- It works directly on individual clusters (instead of cluster groups, as we’ll see later in the guide), so it never scales as your requirements change.
- It forces you to hardcode application combinations inside Application Sets. This makes the generators your new unit of work instead of your Kubernetes manifests.
- It makes all day-2 operations lengthy and cumbersome procedures.
- It makes reasoning about your clusters super difficult. Understanding what’s deployed where is no longer trivial.
The final two points cannot be overstated. This approach might look ok at first glance, but the more clusters you have, the more complex it will become.
- If somebody asks which clusters contain kyverno, you need to scan all individual files for the “enabled” property of the “kyverno” line.
- Every time you add a new cluster to your setup, you need to copy/paste the list of components from another cluster and start enabling/deactivating each individual component. If you have many components and many clusters, this is an error-prone process that you should avoid at all costs.
- If you add a new component, you need to go to all your existing files and add it to all the enabled/deactivated lists.
- It only addresses the first requirement (enabling/deactivating applications for clusters) but not the second one (having different configurations per cluster for the same application).
There is a better way to distribute applications to Argo CD clusters. The approach we DO recommend is using cluster generator labels.
Working with cluster groups instead of individual clusters
In a large organization, you don’t really care about individual clusters. You care about cluster groups. Argo CD doesn’t model the concept of a cluster group on its own, but you can replicate it using cluster labels.
You need to spend some time thinking about the different types of clusters you have and then assign labels to them.
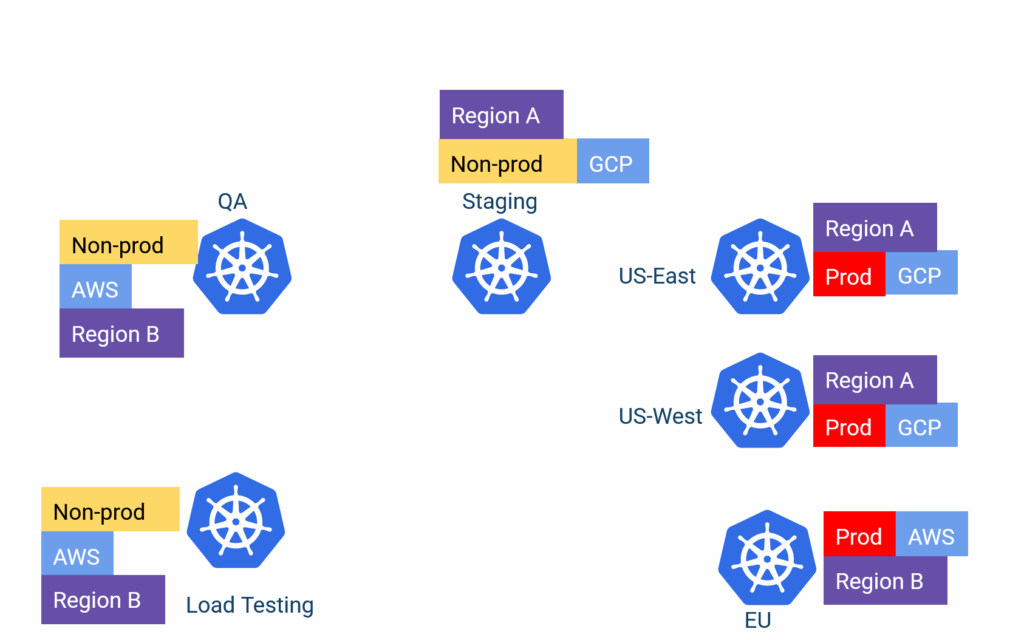
The labels can be anything that makes sense to your organization
- Environment types (for example, QA/staging/prod)
- Regions or countries
- Department or teams
- Cloud provider or other technical difference
- Any other special configuration that distinguishes one or more clusters from the rest
After you have those labels, you can slice and dice your cluster across any dimension and start thinking about cluster groups instead of individual cluster labels.
Because, ultimately, 99% of use cases resolve around cluster groups rather than individual clusters.
- “I want all my production clusters to have application X with Y settings.”
- “I want all my AWS clusters to have X authentication enabled.”
- “Team X will control this environment while team Y will control that environment.”
- “All European clusters need this application.”
- “Application X is installed on both US-East and US-West regions, but with different configurations.”
- “Just for our QA environment, we need this load testing app deployed.”
We’ll see in detail all the advantages when using cluster labels, but one of the easiest ways to understand the flexibility of this approach is to examine what happens for a very common scenario—adding a brand new cluster.
In most cases, a new cluster is “similar” to another cluster. A human operator needs to “clone” an existing cluster, or at the very least, define the new properties of the new cluster in the configuration file.
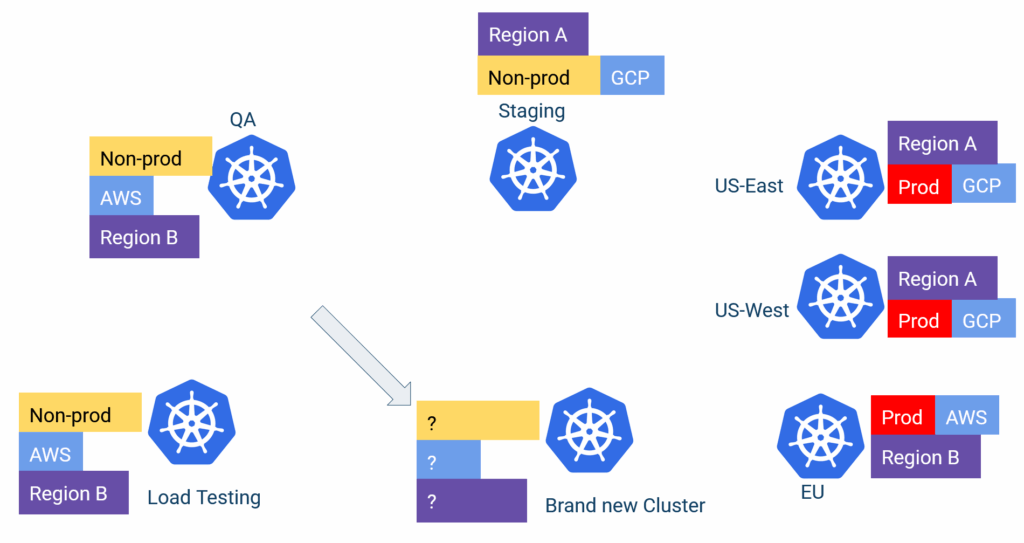
If you use cluster labels (as we suggest), the whole process requires zero modifications to your application set files.
- You create the cluster with your favorite infra tool (Terraform/Pulumi/Crossplane, etc)
- You assign the labels on this cluster (for example, it’s a new QA cluster in US East)
- Finished!
Argo CD automatically detects this new cluster when it collects all its clusters, and deploys everything that needs to be deployed in the cluster according to its labels. There’s no configuration file to edit to “enable/deactivate” your apps. The process cannot get any easier than this.
Notice that this setup also helps with communication between developers and operators/infrastructure people. Opening a ticket for a new cluster and having several discussions about the contents of the new cluster significantly slows down development time.
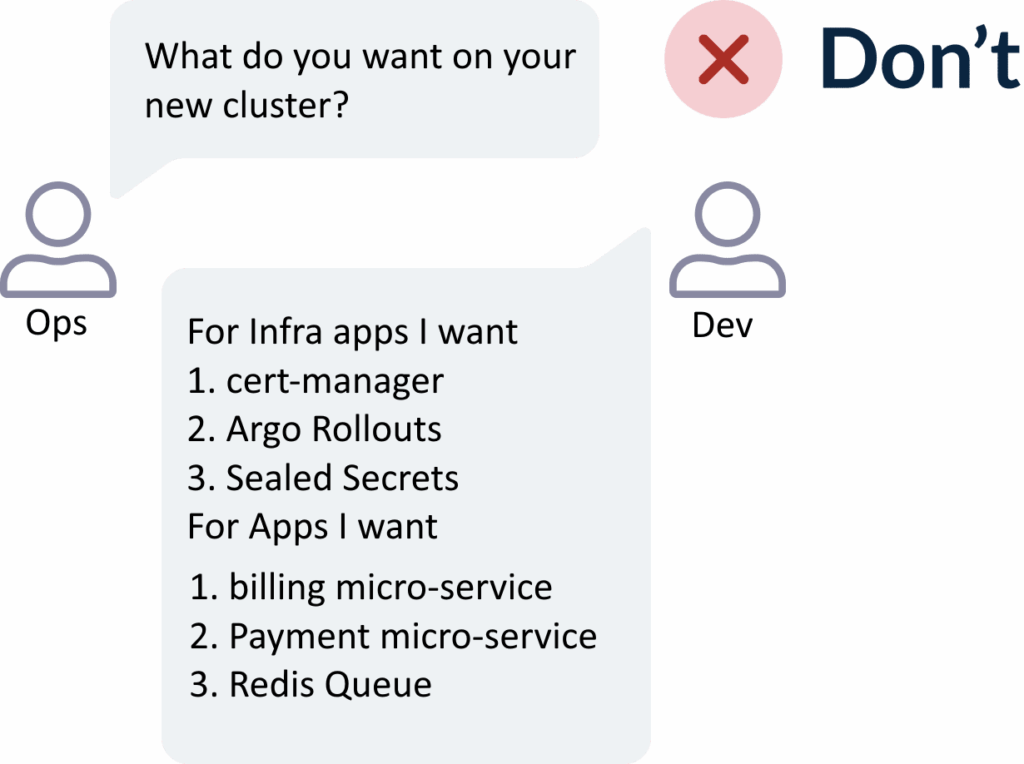
In most cases, developers want a cluster that either mimics an existing one or has similar configuration to another cluster group. This makes your job very easy, as you can map directly to cluster labels what developers need.
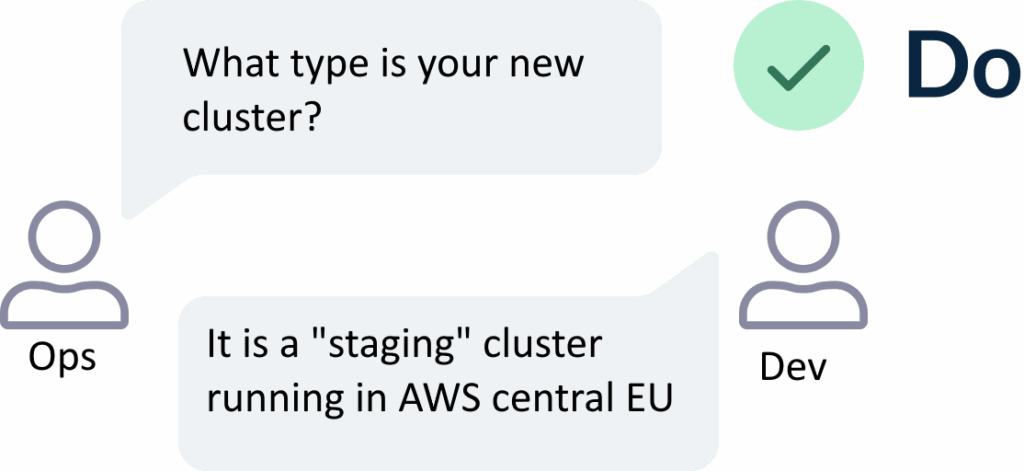
Creating a new cluster can be a hectic process because you need to validate that it matches the expected workloads and is “similar” to your other clusters. If you use cluster labels, then Argo CD takes care of everything in minutes instead of hours.
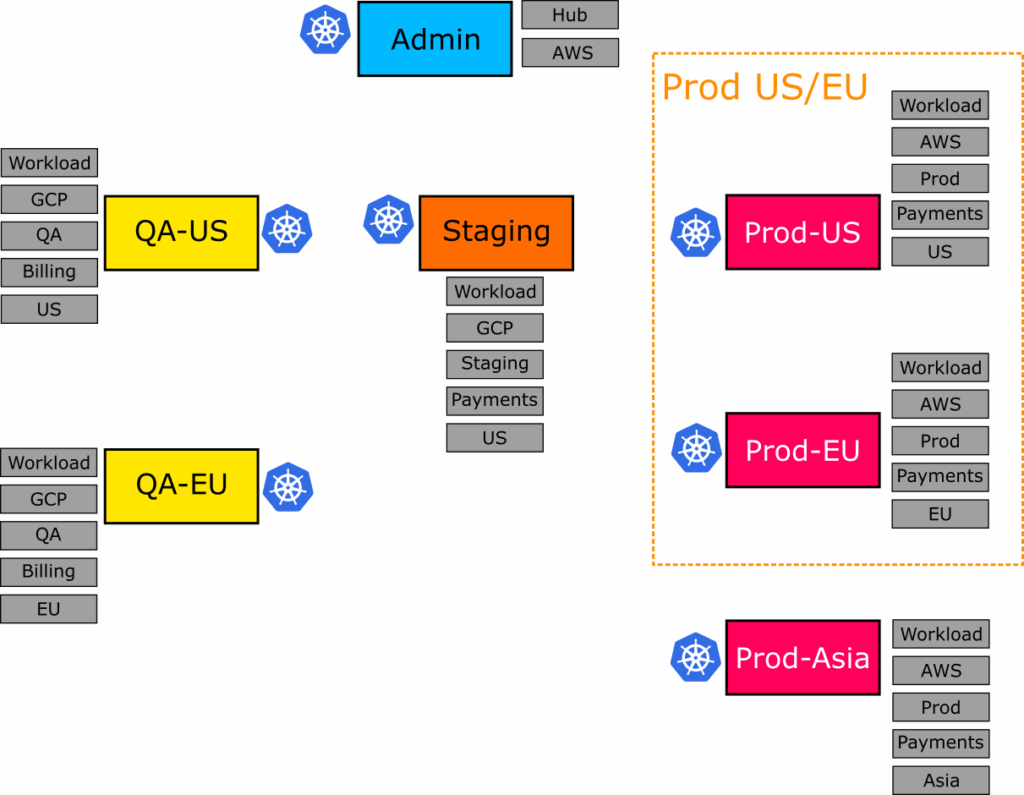
Organizing your Argo CD clusters with different labels
Let’s see how all our use cases can work together with a semi-realistic example. You can find all Argo CD manifests at https://github.com/kostis-codefresh/multi-app-multi-value-argocd if you want to follow along.
The repository contains:
- A set of scripts to create 7 clusters running on the same machine using K3d
- Different labels for organizing those clusters into different groups
- Example Application Sets that distribute applications to those cluster groups
- Helm charts and Kustomize overlays for placeholder applications
Here are the 7 clusters that we define with K3d. In a real organization, these clusters would be created with Terraform or another similar tool.
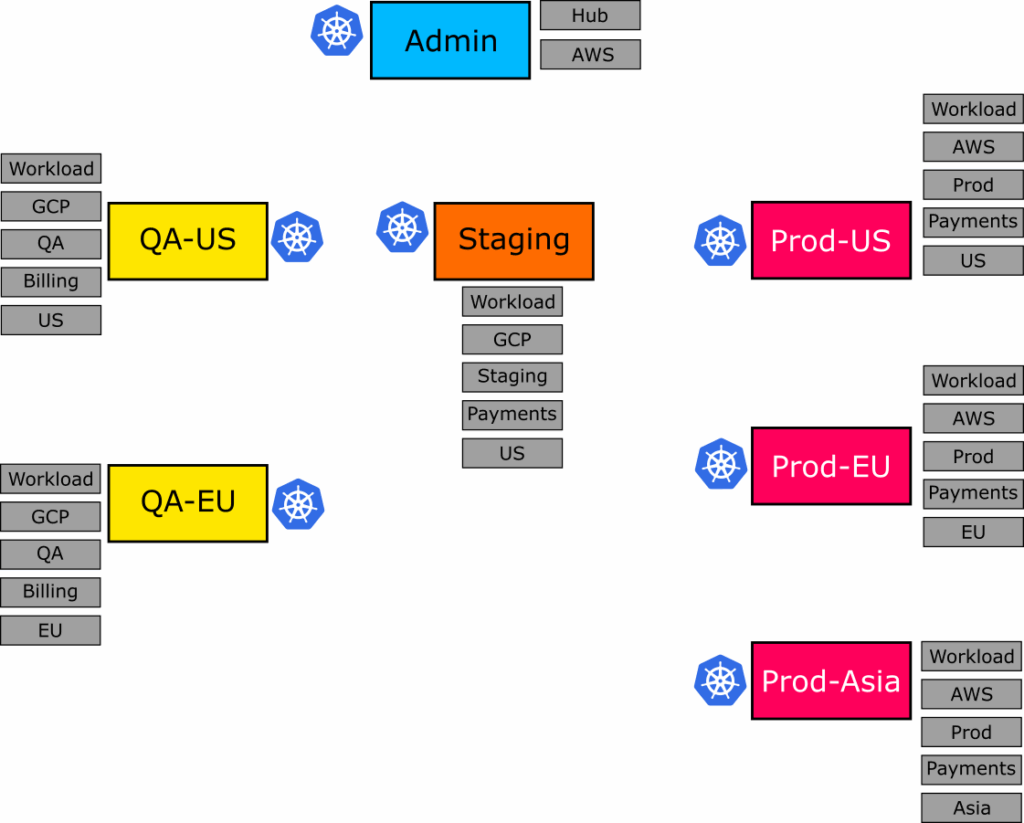
We’ve assigned several example labels on those clusters. Notice that even before talking about applications, the clusters themselves exist in 2 dimensions:
- A promotion flow (QA -> staging -> production) on the horizontal axis
- A region setting (US/EU/Asia) on the vertical axis
The “hub” cluster contains the Argo CD instance that manages all the other clusters. In our example, this cluster only has Argo CD and no end-user applications, so it doesn’t take part in our application sets (it has a label type=hub instead of type=workload).
You can verify or change the labels of each cluster by the Cluster Secret in the main Argo CD instance. Here’s an example of a QA cluster that shows the assigned labels as created by our example GitHub repository.
apiVersion: v1
data:
[...snip..]
kind: Secret
metadata:
annotations:
managed-by: argocd.argoproj.io
labels:
argocd.argoproj.io/secret-type: cluster
cloud: gcp
department: billing
env: qa
region: eu
type: workload
name: cluster-k3d-qa-eu-serverlb-1347542961
namespace: argocd
We’re now ready to look at some typical scenarios. It’s impossible to cover all possible use cases, so we’ll see some representative scenarios for each use case.
The major question that you need to ask yourself is whether you want to deploy an application across different environments with the exact same configuration OR you want a different configuration per environment. The latter is obviously more complex and requires a good understanding of your Kustomize Overlays and Helm value hierarchies, but it’s closer to how a real organization works:
Here are the scenarios we’ll see:
| Scenario | Type | Configuration |
|---|---|---|
| 1 – “workload clusters” | Plain Manifests | Same across all environments |
| 2 – “GCP only” | Plain Manifests | Same across all environments |
| 3 – “Europe only” | Plain Manifests | Same across all environments |
| 4 – “Production/Asia” | Plain Manifests | Same across all environments |
| 5 – “QA US and EU” | Kustomize | Same across all environments |
| 6 – “Production EU/US” | Kustomize | Different per environment |
| 7 – “QA US and EU” | Helm | Same across all environments |
| 8 – “Europe Only” | Helm | Different per environment |
| 9 – “Production EU/US/Asia” | Helm | Different per environment |
Notice that in our example repository, our applications are grouped in folders by type: manifests, Kustomize, or Helm apps.
In a real organization, you might have different sub-folders for each type, but it’s simpler if you only have to manage one type of application (for example, Kustomize for your own developers and Helm charts for external applications).
Scenario 1 – Run some applications on all workload clusters
Let’s see a very simple use case. We want to deploy all the following common applications to all our clusters only, excluding the Argo CD “hub” cluster. We can take advantage of the “workload” label and point Argo CD to a folder that has all our common applications.
spec:
goTemplate: true
goTemplateOptions: ["missingkey=error"]
generators:
- matrix:
generators:
- git:
repoURL: https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git
revision: HEAD
directories:
- path: simple-apps/*
- clusters:
selector:
matchLabels:
type: "workload"
You can see the full Application Set at 01-common-apps.yml. This file instructs Argo CD to:
- Gather all connected clusters that have the “type=workload” label
- Gather all the Kubernetes manifests found under “simple-apps”
- Create all the combinations between those clusters and those apps
- Deploy the resulting Argo CD applications.
If you’re not familiar with generators, please read our Application Set Guide. If you deploy this file, you’ll see the following:
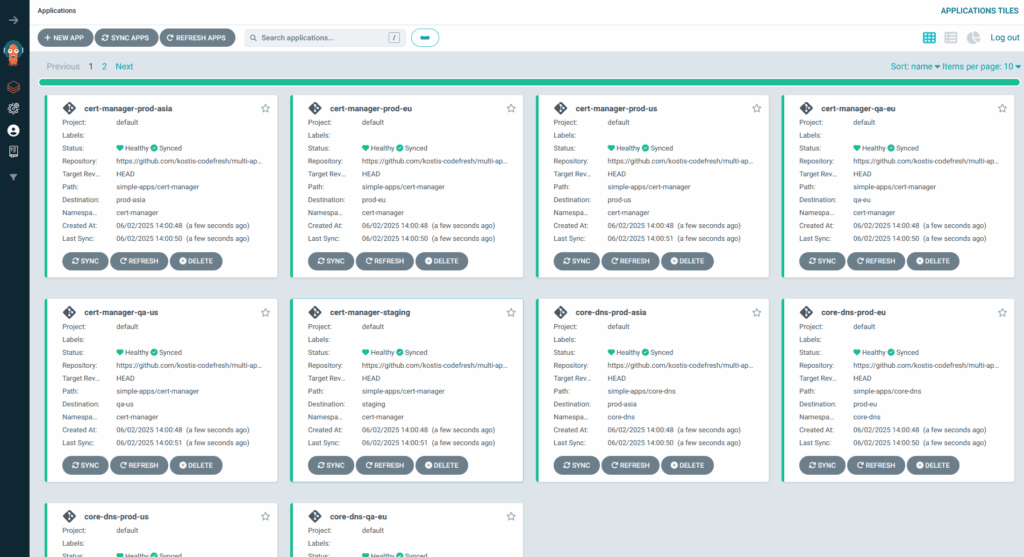
We got 18 applications (6 clusters multiplied by 3 apps) in a single step. Isn’t this cool?
Scenario 2- Choose only GCP clusters and exclude those in AWS
In the next example, we want to install all the applications under `simple-apps` folder only in our Google Cloud clusters, but those applications should not exist in our Amazon clusters. Again, we have created the appropriate labels in advance. In our imaginary organization, all non-production servers run in GCP.
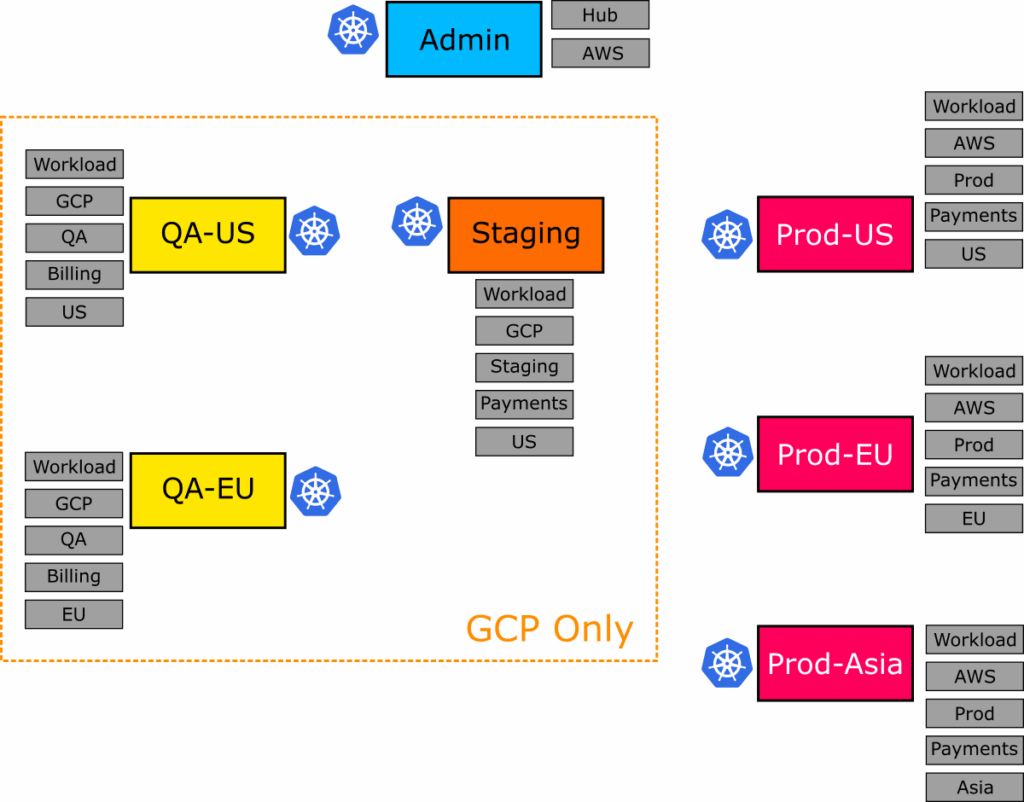
The admin server also runs in AWS, and this is why it won’t get picked up by our application set. You can find the full manifest at 02-gcp-only.yml.
spec:
goTemplate: true
goTemplateOptions: ["missingkey=error"]
generators:
- matrix:
generators:
- git:
repoURL: https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git
revision: HEAD
directories:
- path: simple-apps/*
- clusters:
selector:
matchLabels:
type: "workload"
cloud: "gcp"
This Application Set is similar to the previous one, but now we’re matching 2 labels—one for Google Cloud and one for all our “workload” clusters.
If you apply it, you get several applications, but only to non-prod environments.

Argo CD created a list of applications for only the QA and Staging cluster groups, as they contain clusters that run on Google Cloud.
Scenario 3 – Choose only European Clusters
The big power of labels will become clear when you get requirements that need to work with clusters in an unusual or non-linear way. Let’s imagine a scenario where you need to do something specific to all European clusters because of GDRP regulations.
At this point, most teams realize that the primary way of organizing their clusters was by type (qa/staging/prod), and they modelled the region as a secondary parameter. This creates several challenges and makes people ask the same question, “Does product X support deployments in regions?”.
But when using the cluster generator, all labels are first-level constructs, allowing you to make any selection possible. We can focus on European clusters by just defining our region the same way as any other scenario.
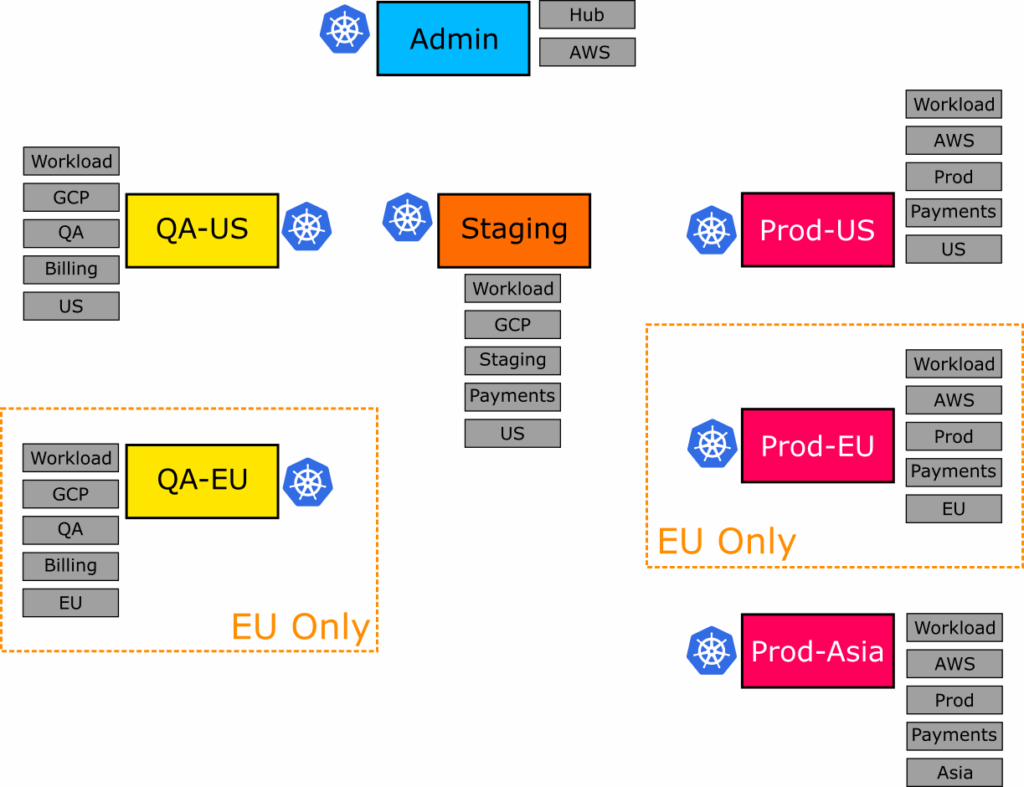
Today, only the QA and Production environments have a European server. But tomorrow, you might add one in the Staging environment WITHOUT any modifications in your application Set.
We select all European servers by region with file 03-eu-only.yml
spec:
goTemplate: true
goTemplateOptions: ["missingkey=error"]
generators:
- matrix:
generators:
- git:
repoURL: https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git
revision: HEAD
directories:
- path: simple-apps/*
- clusters:
selector:
matchLabels:
type: "workload"
region: "eu"
Deploying this application set will instruct Argo CD to place all the applications under simple-apps folder only in the European servers:
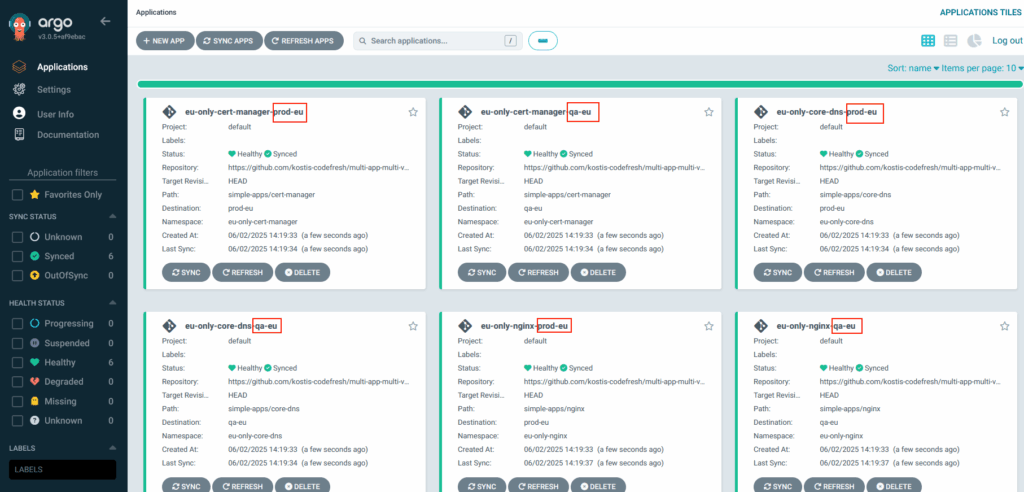
If you add a new European Region in the Staging environment, then in the next Argo CD sync, that cluster also gets all applications defined for Europe, with zero effort from the administrator.
Scenario 4 – Choose a specific cluster among a cluster group
If it wasn’t clear from the previous examples, the label selector for clusters works in an “AND” manner by default. So the more labels you add in the selector, the more specific the application set becomes.
This means that even if you really want to select a single cluster among a group, you can just define all the labels that correctly identify it.
We want to select the Asian Environment for Production (which is a specific Kubernetes cluster).
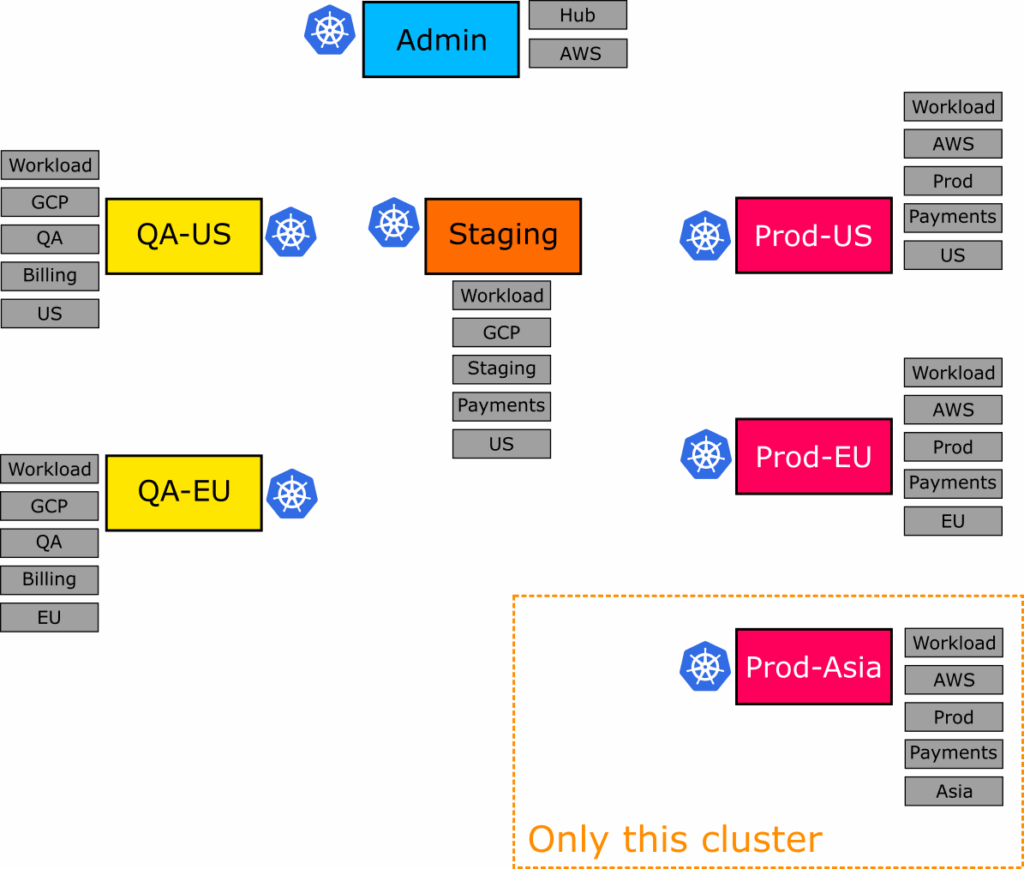
The application set that selects this cluster is at 04-specific-cluster.yml.
spec:
goTemplate: true
goTemplateOptions: ["missingkey=error"]
generators:
- matrix:
generators:
- git:
repoURL: https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git
revision: HEAD
directories:
- path: simple-apps/*
- clusters:
selector:
matchLabels:
type: "workload"
region: "asia"
env: "prod"
The labels we have defined in the application set map only to one cluster. Argo CD will look at this application set and find all clusters that have type=workload AND region=asia AND env=prod.
Applying the file you will see the following
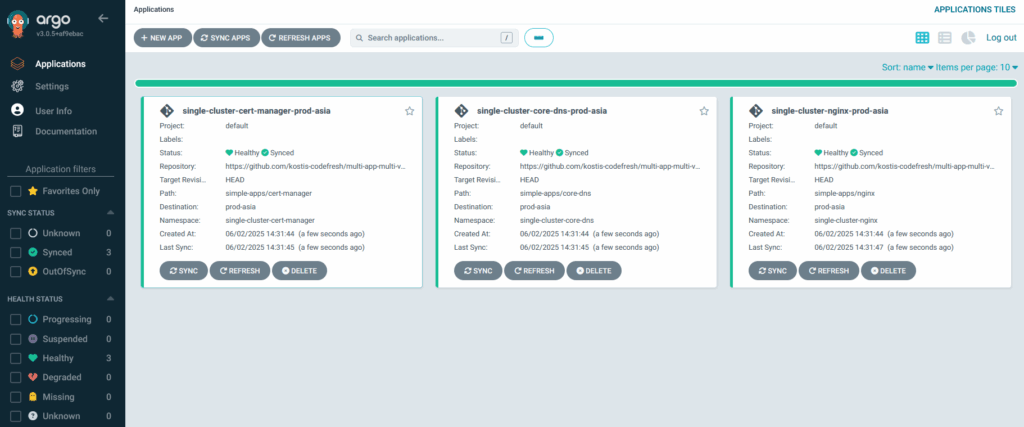
As expected, Argo CD deployed all the applications under simple-apps folder only to the production cluster in Asia.
Scenario 5 – Different Kustomize overlays for the QA clusters
For simplicity, in all the previous examples, all our applications use the same configuration across all clusters. So even if our cluster generator selected multiple clusters, they all used the plain manifests we defined.
While this approach can work for some trivial applications, you almost certainly want to use a different configuration per cluster. This can take the form of DNS names, database credentials, security controls, rate limiting settings, etc.
For our next example, we’ll use Kustomize overlays. For each application, we have the base configuration plus extra settings in overlays or Kustomize components.

We have covered Kustomize overlays in detail in the promotion article and explained how they work with Argo CD in our Application Set guide, so make sure you read those first if you’re not familiar with overlays.
For the cluster selector, we’ll choose the QA environment this time (which corresponds to 2 clusters).
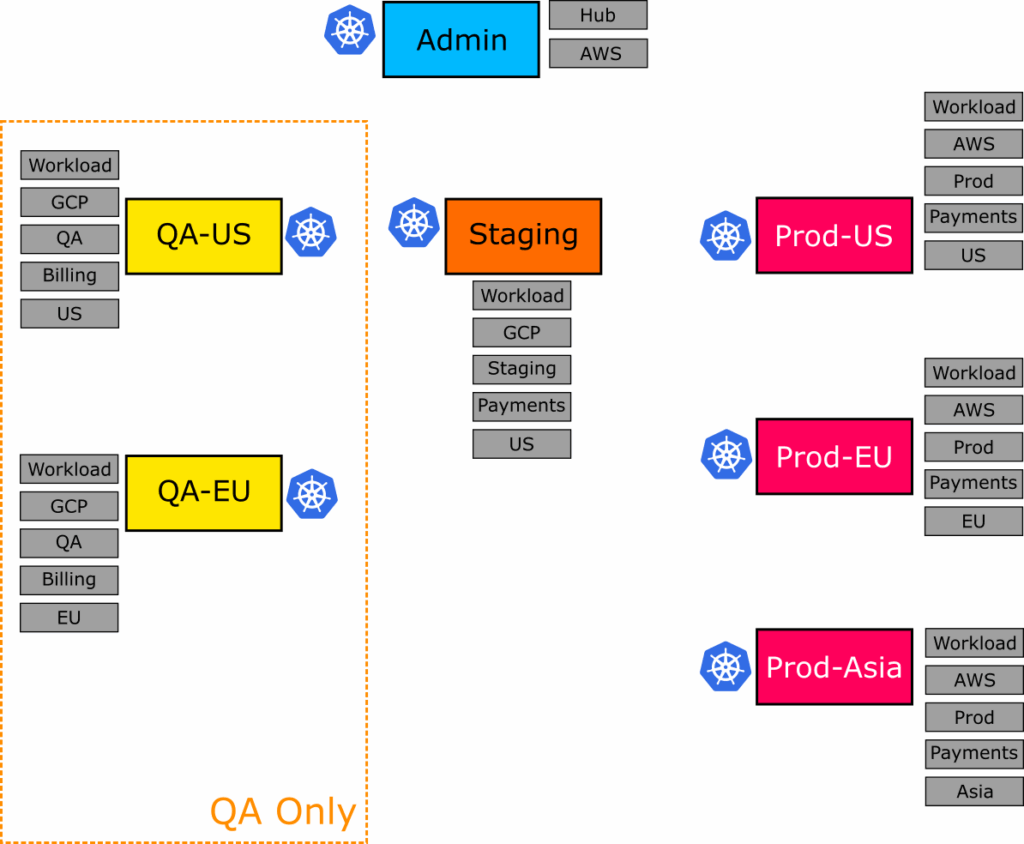
The application set that selects the QA clusters and deploys applications with the respective configuration is at 05-my-qa-appset.yml.
spec:
goTemplate: true
goTemplateOptions: ["missingkey=error"]
generators:
- matrix:
generators:
- git:
repoURL: https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git
revision: HEAD
directories:
- path: kustomize-apps/*/envs/qa
- clusters:
selector:
matchLabels:
type: "workload"
env: "qa"
The Matrix generator selects all clusters that match the QA/Workload labels and applies only the applications that have a QA overlay.
Apply the file, and you see all QA deployments:
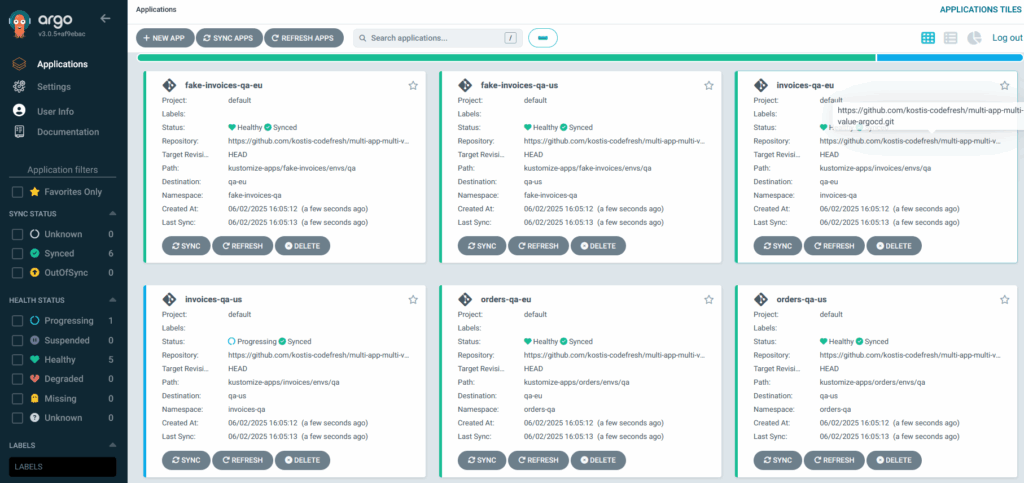
The important point here is that for each application, only the QA overlay is selected.
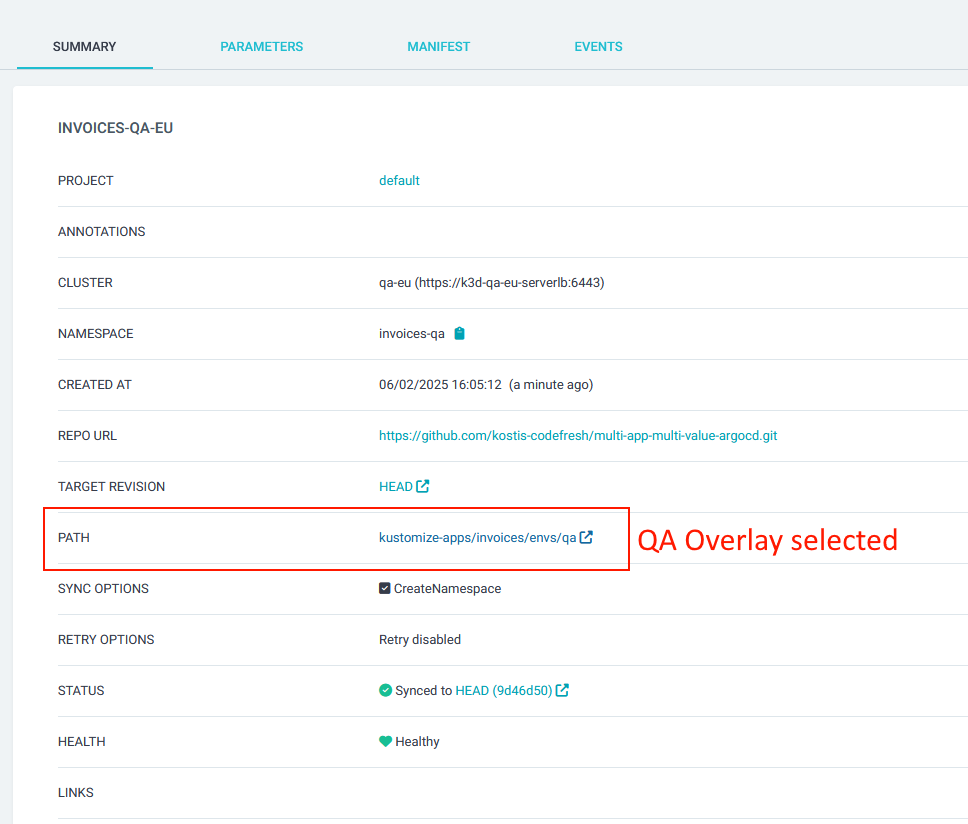
You can see in the Git repository that the “Invoices” application comes with configurations for all environments, but we appropriately employ only the QA one in our application set.
Scenario 6 – Different Kustomize settings for US and EU in production
There are many more examples we can show with this setup. Be sure to read the documentation of the cluster generator. One important point is that you can use the output of this generator as input to another generator.
As a final example with Kustomize, let’s see a scenario where we want to deploy our applications to Production Europe and Production US, but not in Asia.
Remember that by default, server labels work in “AND” mode. So if we simply list “us” and “eu” as labels, Argo CD will try to find all clusters that have both labels at the same time. We don’t want this, as no cluster matches this description.
Also, unlike the previous example where we specifically asked for the “QA” overlay, now we want to choose the overlays that match whatever the cluster type/region is (either prod-us or prod-eu).
You can find the full application set at 06-my-prod-appset.yml.
spec:
goTemplate: true
goTemplateOptions: ["missingkey=error"]
generators:
- matrix:
generators:
- clusters:
selector:
matchLabels:
type: "workload"
env: "prod"
matchExpressions:
- key: region
operator: In
values:
- "eu"
- "us"
- git:
repoURL: https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git
revision: HEAD
directories:
- path: 'kustomize-apps/*/envs/{{.name}}'
The first thing to show here is the matchExpressions block. This lets you choose clusters in an “OR” manner. We want all clusters that are either EU or US AND in production.
The second point is using the output of the cluster generator as input to the Git generator. The “{{.name}}” variable will render to the name of the cluster matched, forcing the Git generator to load the respective Kustomize overlay for each environment.
Apply the file and you will see production deployment in EU and US but not in Asia:
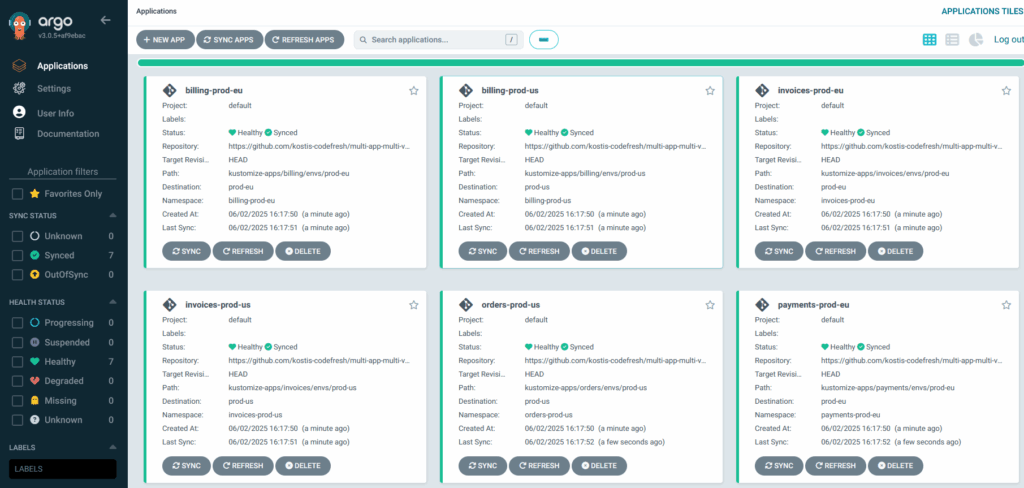
And most importantly, you see that each server loads the configuration for its own region:
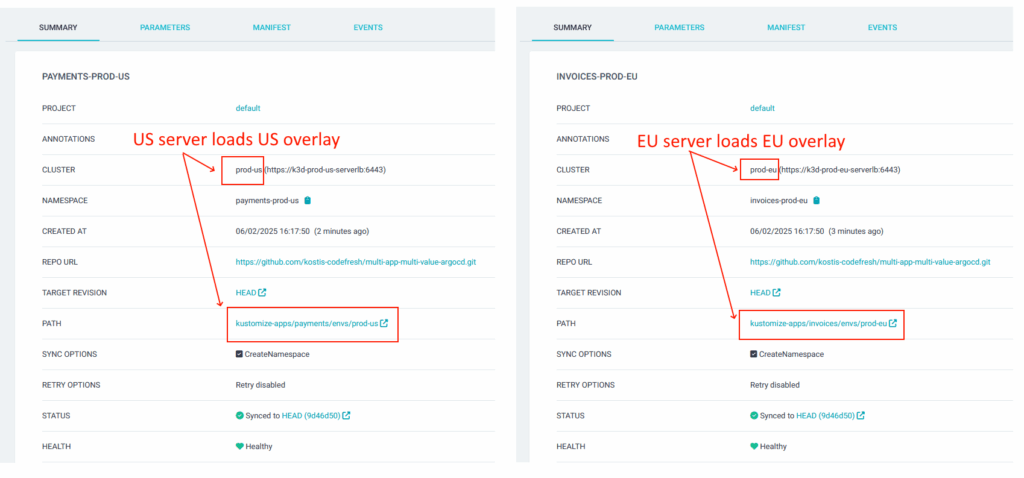
You should now understand how to select any combination of clusters and apply your exact choice of Kustomize overlays according to the “type” of each cluster.
Scenario 7 – A Helm hierarchy of values for the QA environment
Cluster labels can also work with your Helm charts and values.
As a starting example, let’s deploy our Helm charts to the two QA clusters using the same configuration for both.
You can find the full application set at 07-helm-qa-only.yml.
spec:
goTemplate: true
goTemplateOptions: ["missingkey=error"]
generators:
- matrix:
generators:
- git:
repoURL: https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git
revision: HEAD
directories:
- path: charts/*
- clusters:
selector:
matchLabels:
type: "workload"
env: "qa"
The generator part of the file selects our charts and applies them to all clusters with the QA/workload label.
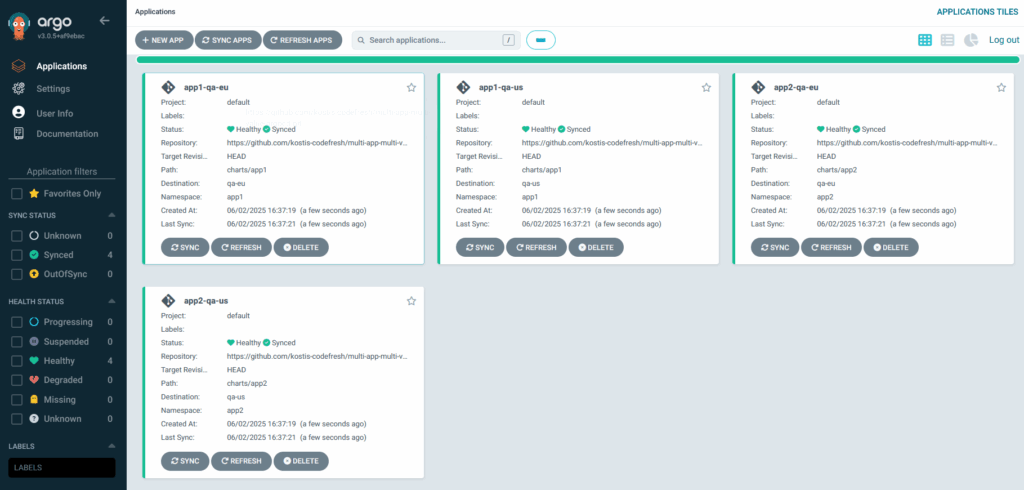
We have 2 example charts in the Git repository, so Argo CD created 4 applications for us (1 for each region).
Scenario 8 – Different Helm values for the European environments
Like the Kustomize example, we want to make our examples more advanced and have different value files per environment.
The same Git repository also contains a set of Helm values for each environment.
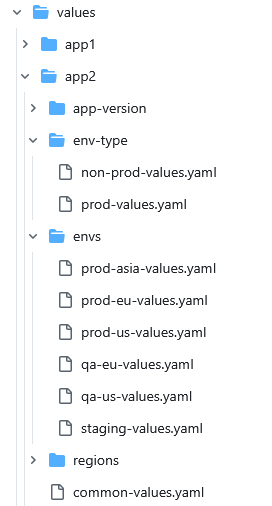
We have covered Helm value hierarchies and Argo CD applications in our Helm guide, so please read that guide first if you don’t know how to create your own value hierarchies.
Let’s deploy our Helm charts at all European servers:
This time, however, we want to specifically load the European values only instead of all values.
You can find the full application set at 08-helm-eu.yml
spec:
goTemplate: true
goTemplateOptions: ["missingkey=error"]
generators:
- matrix:
generators:
- clusters:
selector:
matchLabels:
type: "workload"
region: "eu"
- git:
repoURL: https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git
revision: HEAD
directories:
- path: charts/*
The generator part is straightforward. It applies all charts to clusters with the EU/Workload labels. The smart selection of values happens in the “sources” section of the generated application:
sources:
- repoURL: https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git
path: '{{.path.path}}'
targetRevision: HEAD
helm:
valueFiles:
- '$my-values/values/{{index .path.segments 1}}/common-values.yaml'
- '$my-values/values/{{index .path.segments 1}}/app-version/{{index .metadata.labels "env"}}-values.yaml'
- '$my-values/values/{{index .path.segments 1}}/regions/eu-values.yaml'
- '$my-values/values/{{index .path.segments 1}}/envs/{{index .metadata.labels "env"}}-eu-values.yaml'
- repoURL: 'https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git'
targetRevision: HEAD
ref: my-values
Here we apply the appropriate values according to:
- The chart name (index .path.segments 1)
- The environment label that exists on the cluster (index .metadata.labels “env”)
In this example, you see how you can query the cluster itself for its own metadata.
If you apply this file, you see both charts deployed in the European servers.
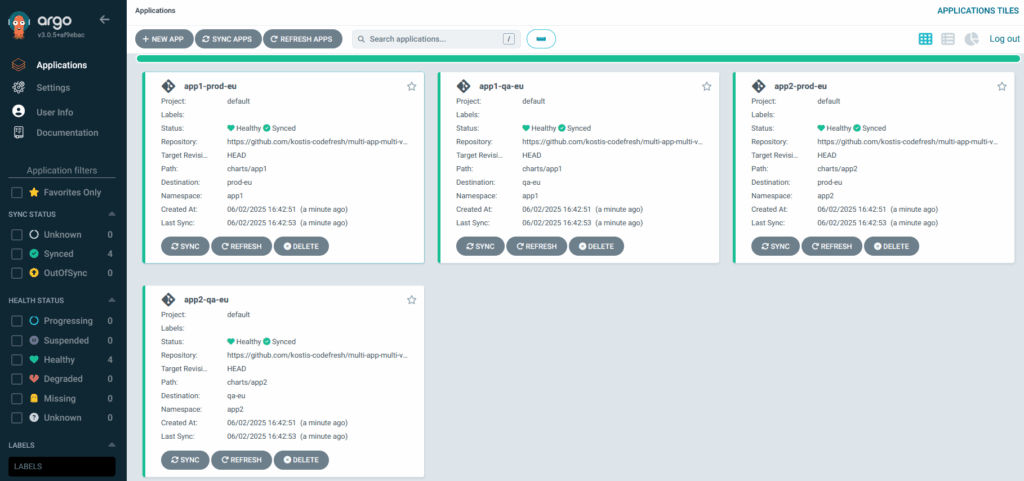
But most importantly, you see that each environment gets the correct values according to its type:
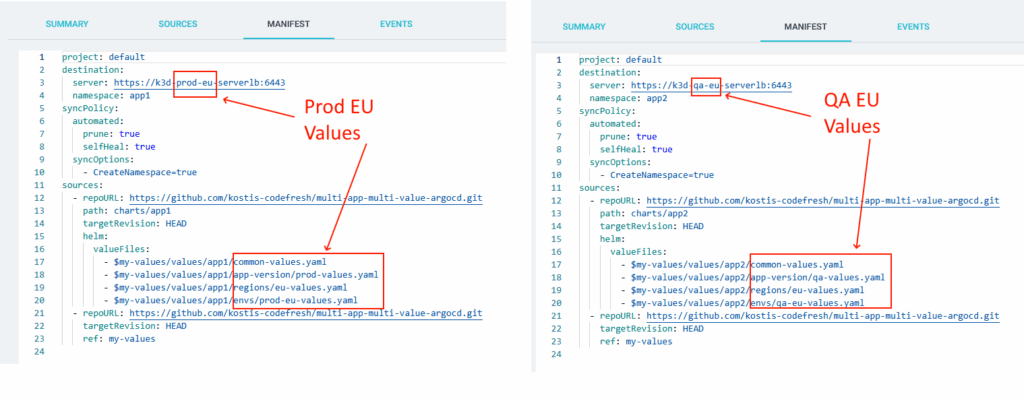
Notice that in both cases, we still have some common values that apply to both environments.
Scenario 9 – Different Helm values for all 3 Production regions
As a final example with Helm, let’s deploy to all production regions with the appropriate settings for each one.
We choose all 3 regions in our cluster generator.
You can find the full application set at 09-helm-prod.yml.
Like before, we select all 3 regions in an “OR” manner and apply our charts.
spec:
goTemplate: true
goTemplateOptions: ["missingkey=error"]
generators:
- matrix:
generators:
- clusters:
selector:
matchLabels:
type: "workload"
env: "prod"
matchExpressions:
- key: region
operator: In
values:
- "eu"
- "us"
- "asia"
- git:
repoURL: https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git
revision: HEAD
directories:
- path: charts/*
For each application, we query each cluster for its environments and region.
sources:
- repoURL: https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git
path: '{{.path.path}}'
targetRevision: HEAD
helm:
valueFiles:
- '$my-values/values/{{index .path.segments 1}}/common-values.yaml'
- '$my-values/values/{{index .path.segments 1}}/app-version/{{index .metadata.labels "env"}}-values.yaml'
- '$my-values/values/{{index .path.segments 1}}/env-type/{{index .metadata.labels "env"}}-values.yaml'
- '$my-values/values/{{index .path.segments 1}}/regions/{{index .metadata.labels "region"}}-values.yaml'
- '$my-values/values/{{index .path.segments 1}}/envs/{{index .metadata.labels "env"}}-{{index .metadata.labels "region"}}-values.yaml'
- repoURL: 'https://github.com/kostis-codefresh/multi-app-multi-value-argocd.git'
targetRevision: HEAD
ref: my-values
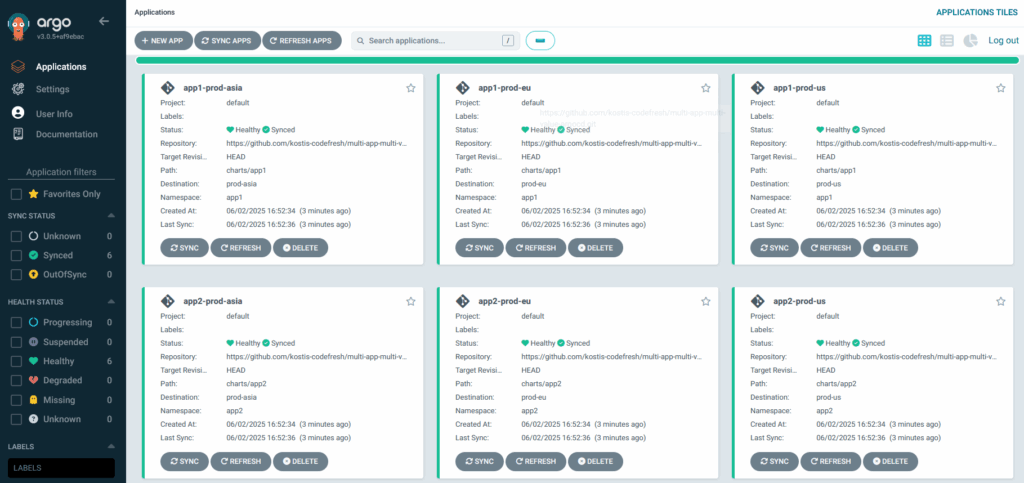
All charts are now deployed in all regions:
You can also verify that each environment picks the correct settings from the value hierarchy:
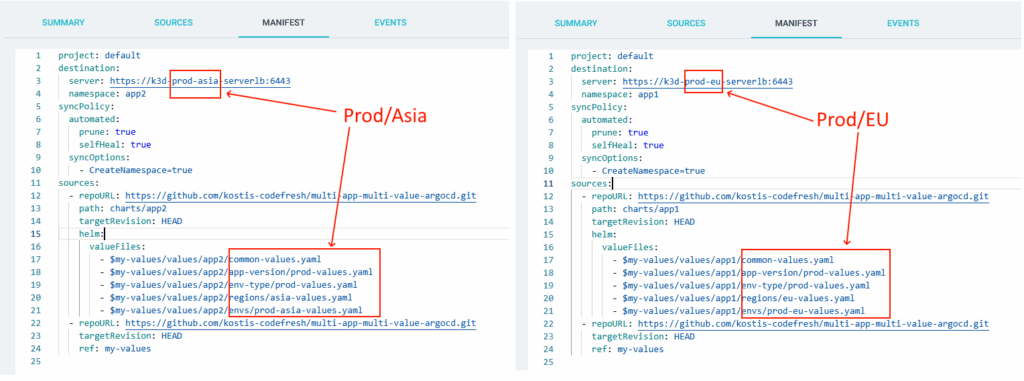
You have now seen how to apply value hierarchies with Application Sets and cluster labels.
Day 2 operations
We now reach the most important point of this guide. We’ve seen how cluster labels let you define exactly what goes into which cluster. You might be wondering why this is the recommended solution and how it’s better than other approaches you’ve seen.
The answer is that with cluster labels you treat your application sets in a “create-and-forget” function. After the initial set up, you shouldn’t need to touch your application sets at all. This means that maintenance effort is zero, which is always the OPTIMAL way of evaluating any architecture decision.
Let’s see some semi-realistic scenarios of using our recommendation in a real organization.
Imagine you just organized all your application sets with cluster labels. All files are committed in Git, and all applications are successfully deployed. Everything runs smoothly.
Scenario A – Removing a server
On Monday, you need to decommission the US/prod server. You remove the “us” and “prod” tags from the server. In the next sync, the cluster generator from all related appsets doesn’t pick it up and nothing gets deployed there. You don’t really care how many application sets touched this cluster. They will all stop deploying there automatically.
Changes you had to do in your Application Sets: ZERO
Scenario B – Deploying a new application
On Tuesday, a developer wants a new application in the QA environment. You commit a new overlay for QA configuration for that app. All QA application sets pick it up in the next sync and deploy it to any/all clusters that deal with QA. You don’t really care how many application sets affect QA or how many clusters are contained in QA. They will all get the new application in the same manner.
Changes you had to do in your Application Sets: ZERO
Scenario C – Adding a new Cluster
On Wednesday, you need to add a new cluster to replace the decommissioned one. You create the new cluster with Terraform/Pulumi/Crossplane/whatever and just assign it the appropriate tags (“us”,”prod”, “workload”,”aws”). All respective Application Sets see the new cluster in the next sync and deploy whatever needs to be deployed there. You don’t really care how many Application Sets touch this cluster. The cluster will get the exact same applications as it had before.
Changes you had to do in your Application Sets: ZERO
Scenario D – Copying an application
On Thursday, a developer says that a specific application that exists in staging also needs to go to QA.
You copy the staging overlay to a QA overlay for this application and ask the developer about the correct settings. In the next sync, all the QA Application Sets pick it up and deploy it. The developer doesn’t need to know anything about application sets or cluster labels. In fact, they could just do this deployment on their own if they had access to the Kustomize overlays.
Changes you had to do in your Application Sets: ZERO
Scenario E – Central cluster change
On Friday, you’re told that ALL your clusters now need sealed-secrets installed. You add a new configuration for sealed secrets in your “common” folder and commit it to Git. Then the “Common” Application Set (that applies to all clusters) picks it up and applies it to all clusters.
Changes you had to do in your Application Sets: ZERO
Essentially, the Application Sets only need to change when you need to add another dimension to your servers (i.e., new labels) for something that was not expected. If you completed a proper evaluation in the beginning, and communicated to all parties how all the servers are going to be used, then this scenario won’t happen very often. For daily operations, the Application Sets just sit in the Git repository without anybody (operators or developers) having to make any changes at all.
The other big advantage of cluster labels is that they work the same, regardless of how many servers you have. The Application Sets that work with labels will automatically update on their own, even if they manage 1, 10, or 100s of servers that you connect to the central Argo CD instance.
Let’s compare those same scenarios with the approach we do NOT recommend, where application sets explicitly enable/deactivate components/apps in each specific server.
## Do not do this
- merge:
mergeKeys:
- app
generators:
- list:
elements:
- app: external-dns
appPath: infra/helm-charts/external-dns
namespace: dns
- app: argocd
appPath: infra/helm-charts/argocd
namespace: argocd
- app: external-secrets
appPath: infra/helm-charts/external-secrets
namespace: external-secrets
- app: kyverno
appPath: infra/helm-charts/kyverno
namespace: kyverno
- list:
elements:
- app: external-dns
enabled: "true"
- app: argocd
enabled: "true"
- app: external-secrets
enabled: "false"
- app: kyverno
enabled: "true"
selector:
matchLabels:
enabled: "true"
What actions do you need for each scenario?
- Scenario A – Removing a server
- You need first to locate all Application Sets that “choose” this server.
- You then need to edit all application Sets and “deactivate” all the components they contain.
- You need to commit and sync all changes.
- There is a risk that you either forgot an application set or forgot to “deactivate” a line
- The more servers you have, the more complex is the process
- Scenario B – Deploying a new application
- You first need to locate all Application Sets that choose the servers that need this application.
- You need to edit all those application Sets and add a new line for this application.
- You need to commit and sync all changes.
- There’s a risk that you either forgot an application set or forgot to add a line for the new application.
- The more servers you have, the more complex the process.
- Scenario C – Adding a new Cluster
- You need to understand how this cluster is “similar” to other clusters.
- You either need to create a new Application Set for this cluster or locate all Application Sets that touch it.
- You need to add all new lines of enabled/disabled components for this cluster.
- There’s a risk that you either forgot an application set or forgot to add a line for the new application.
- Scenario D – Copying an application
- You need first to locate all Application Sets that choose the news servers for this application.
- You need to edit all those application Sets and locate the line for this application and change it to “enabled”.
- You need to commit and sync all changes.
- There’s a risk that you either forgot an application set or forgot to “enable” the component.
- The more servers you have, the more complex the process.
- Scenario E – Central change
- You need first to locate all Application Sets that you manage.
- You need to edit all those application Sets and add a new line for this common application.
- You need to commit and sync all changes.
- There’s a risk that you either forgot an application set or forgot to add a line for the new application
- The more servers you have, the more complex the process.
It shouldn’t be a surprise that having snowflake servers where you must enable/deactivate each application individually is a much more complex process than working with cluster groups identified by labels.
Developers and self-service
At the start of this guide, we talked about effective communication with developers. Another major reason that makes cluster labels the optimal solution is that they’re fully automated. At each sync, the Argo CD cluster generator detects which clusters have the appropriate labels and does whatever needs to be done (deploy or undeploy an application).
Your developers don’t need to know anything about cluster labels. In fact, they don’t even need to know about Application Sets. Developers can work with a Git repository that holds standard Helm charts/Kustomize overlays/plain manifests, and their instructions are super simple:
- If they add a new overlay in the QA folder, then that application will be deployed in the QA environments regardless of the number of servers.
- If they delete an overlay, that application will be undeployed.
- If they want a brand new application, they can just commit the new overlays or Helm values in a specific folder, and Argo CD will pick it up.
Developers can work on their own without opening any tickets or waiting for you to do something for them.
This comes in complete contrast to the anti-pattern we explained above, where you manually enable/deactivate applications in each specific cluster. If you follow this approach, all actions become a two-step process:
- The developer adds their overlay or Helm values in a Git repository.
- Then you MUST go to all your Application Sets and manually “enable” the new application.
Preventing developers from deploying their applications and waiting for you to do something is the fastest way to create bottlenecks in your organization.
There is no reason for this complexity when using cluster labels is a much better choice.
Conclusion
In this guide, we explained in detail how to create cluster groups with Argo CD using custom labels. We have also seen:
- How to use the cluster generator to select a cluster in an “AND” and “OR” fashion.
- How to deploy applications to multiple clusters using the same configuration.
- How to deploy Kustomize applications with different overlays per cluster.
- How to deploy Helm applications with different value sets per cluster.
- How to perform common day-2 operations with many Argo CD clusters.
- Why our recommended approach is the optimal one, as the number of clusters and developers grows in your organization.
You can find all Application Sets and manifests at https://github.com/kostis-codefresh/multi-app-multi-value-argocd.
Happy labeling 🙂