
This is the third and last part in our Kubernetes Anti-patterns series. See also part 1 and part 2 for the previous anti-patterns. You can also download all 3 parts in a PDF ebook.
Anti-pattern 11 – Misusing Health probes
Apart from resource limits, if you are moving your application to Kubernetes you should take into account the health probe settings.
By default, a Kubernetes application has no health probes unless you explicitly set them up. Like resource limits, you should consider health probes an essential part of your Kubernetes deployments. This means that all your applications should have resource limits AND health probes when deployed in any cluster of any type.
Health probes decide when and if your application is ready to accept traffic. As a developer you need to understand how Kubernetes is going to use your readiness and liveness endpoints and the implications of each one (especially what a timeout for each one means).
In summary:
- Startup probe => Checks the initial boot of your applications. It runs only once
- Readiness probe => Checks if your application can respond to traffic. Runs all the time. If it fails Kubernetes will stop routing traffic to your app (and will try later)
- Liveness probe => Checks if your application is in a proper working state. Runs all the time. If it fails Kubernetes will assume that your app is stuck and will restart it.
Spend some time to understand the effects of each health probe and evaluate all the best practices for your programming framework.
Some of the common pitfalls are:
- Not accounting for external services (e.g. DBS) in the readiness probe
- Using the same endpoint for both the readiness and the liveness probe
- Using an existing “health” endpoint that was created when the application was running on a Virtual machine (instead of a container)
- Not using the health facilities of your programming framework (if applicable).
- Creating too complex health checks with unpredictable timings (that cause internal denial of service attacks inside the cluster)
- Creating cascading failures when checking external services in the liveness health probe
Creating cascading failures by mistake is a very common problem that is destructive even with Virtual machines and Load balancers (i.e., it is not specific to Kubernetes).
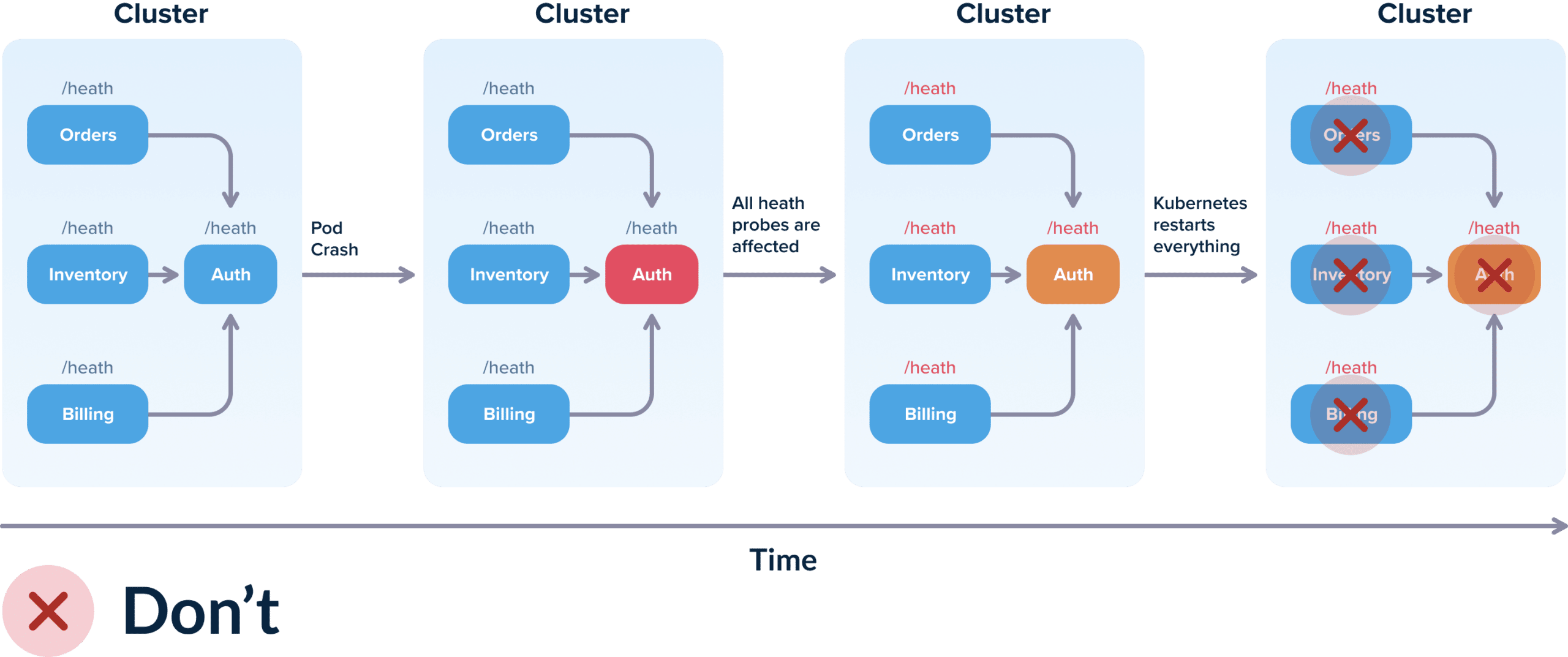
You have 3 services that all use the Auth service as a dependency. Ideally the liveness probe for each service should only check if the service itself can respond to queries. However, if you setup the liveness probe to check for the dependencies then the following scenario can happen:
- Initially, all 4 services work correctly.
- The auth service has a hiccup (maybe its DB is overloaded) and is not responding to requests fast enough.
- All 3 services correctly detect that the auth service has issues.
- Unfortunately, they set their OWN health status to down (or unavailable) even though they all work fine.
- Kubernetes runs the liveness probes and decides that all 4 services are down and restarts all of them (while in reality only one of them had issues).
For more advanced cases, you should also become familiar with circuit breakers as they allow you to decouple the “liveness” of an application with its ability to respond.
Anti-pattern 12 – Not using the Helm package manager
There is only one package manager right now for Kubernetes and that is Helm. You can think of Helm as the apt/rpm utility for your Kubernetes clusters.
Unfortunately, people often misunderstand the capabilities of Helm and choose another “alternative”. Helm is a package manager that also happens to include templating capabilities. It is not a templating solution and comparing it to one of the various templating solutions misses the point.
All templating solutions for Kubernetes suffer from the same issue. They can do their magic during application deployment, but after the deployment has finished Kubernetes only knows a set of manifests and nothing more. Any concept of “application” is lost and can only be recreated by having the original source files at hand.
Helm, on the other hand, knows about the whole application and stores application-specific information in the cluster itself. Helm tracks the application resources AFTER the deployment. The difference is subtle but important.
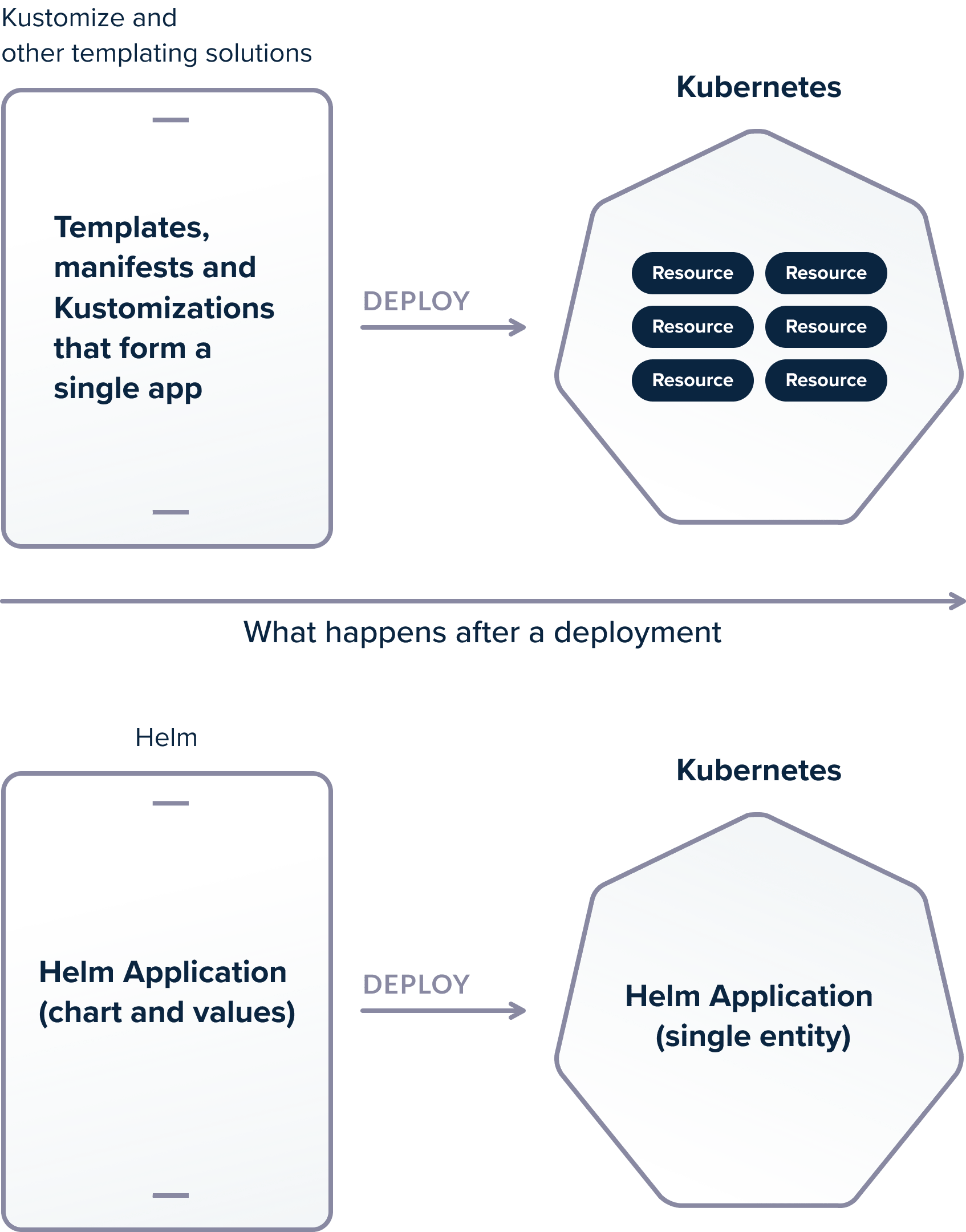
Let’s say that you get kubectl access on a cluster that has 4 applications (where each one is composed of multiple resources) in the same namespace. Your task is to delete one of these applications.
If you have used a simple templating solution (such as Kustomize), you cannot easily understand the application structure by looking at the running resources. If you don’t have the original templates (i.e. kustomizations and original patches) you need to manually inspect resources with kubectl and make the correlations between the application components.
Helm on the other hand tracks the application inside the cluster. You can simply do:
helm ls(to look at the list of applications in the namespace)helm uninstall my-release(to remove the application)
That’s it! No access to the original templates is needed or to a CI pipeline.
Comparing Helm to Kustomize/k8compt/kdeploy and other templating tools is unfair to Helm as Helm is much more than a templating solution.
One of the killer features of Helm is also the rollback function. You are paged at 3 am in the morning and want to perform the fastest rollback possible in a Kubernetes cluster that you are not familiar with. There is simply no time to track the original source files and identify what is the “previous” versions of the templates in Git.
With Helm it is trivial to do:
helm ls(to see releases)helm history my-release(to see previous versions of deployments)helm rollback my-release my-previous-version
All this, right from the cluster because Helm knows what an application is unlike templating solutions that stop their work after a deployment has finished.
Another misconception is that Helm packages are managed with Git Repos and changing a chart involves cloning/copying the chart locally. Helm charts should actually be managed with Helm repositories. It is ok if you also have a copy in Git (following the GitOps paradigm) but deploying a Helm chart to a cluster should happen from a Helm repository and not a Git repo.
It is also worth noting that since Helm 3, there is no server-side component anymore (the infamous Tiller), so if the last time you evaluated Helm you had concerns regarding the security of the cluster, you need to take a fresh look at Helm a second time now that Tiller is gone.
Unless you have a really strange workflow, not using Helm is like not using apt/rpm for package management. If you decide that Helm is not for you, it should be a conscious choice (after careful consideration) and not based on misinformation about selecting “a better templating solution than Helm”.
Anti-pattern 13 – Not having deployment metrics
We have mentioned metrics several times in the previous anti-patterns. By “metrics” we actually mean the whole trilogy of:
- logging – to examine the events and details of requests (usually post-incident)
- tracing – to dive deep in the journey of a single request (usually post-incident)
- metrics – to detect an incident (or even better to predict it)
Metrics are more important in Kubernetes than traditional Virtual machines, because of the distributed nature of all services in a cluster (especially if you use micro-services). Kubernetes applications are fully dynamic (they come and go unlike virtual machines) and it is vital that you know how they adapt to your traffic.
The exact solution that you choose for your metrics is not that important, as long as you have sufficient metrics for all your use cases such as:
- Getting critical information in a timely manner instead of using kubectl (see antipattern 6)
- Understanding how traffic enters your cluster and what is the current bottleneck (see antipattern 7)
- Verifying/adapting your resource limits (see antipattern 10)
The most important use case however is that you need to understand if your deployment has succeeded. Just because a container is up, doesn’t mean that your application is in a running state or can accept requests (see also anti-pattern 11).
Ideally, metrics should not be something that you look at from time to time. Metrics should be an integral part of your deployment process. Several organizations follow a workflow where the metrics are inspected manually after a deployment takes place, but this process is sub-optimal. Metrics should be handled in an automated way:
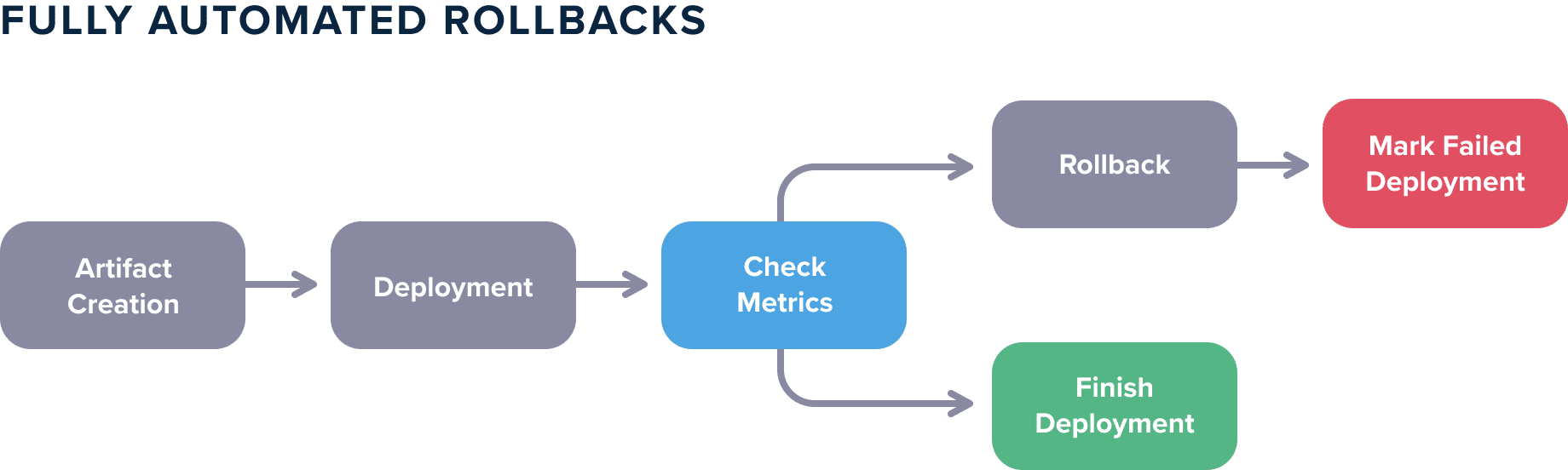
- A deployment takes place
- Metrics are examined (and compared to base case)
- Either the deployment is marked as finished or it is rolled back
Note that there is no manual step involved in these actions.
Making your metrics affecting your deployments is not an easy task. It shows however what is the end goal and how important are metrics for Kubernetes deployments.
Anti-pattern 14 – Not having a strategy for secrets
In the second anti-pattern we explained why baking configuration in containers is a bad practice. This is even more true for secrets. If you use a dynamic service for configuration changes, it makes sense to use the same (or similar) service for handling secrets.
Secrets should be passed during runtime to containers. There are many approaches to secret handling from simple storage to git (in an encrypted form) to a full secret solution like Hashicorp vault.
Some common pitfalls here are:
- Using multiple ways for secret handling
- Confusing runtime secrets with build secrets
- Using complex secret injection mechanisms that make local development and testing difficult or impossible.
The important point here is to choose a strategy and stick to it. All teams should use the same method for secret handling. All secrets from all environments should be handled in the same way. This makes secret tracking easy (knowing when and where a secret was used).
You should also pass to each application only the secrets it actually needs.
Runtime secrets are the secrets that an application needs AFTER it is deployed. Examples would be database passwords, SSL certificates, and private keys.
Build secrets are secrets that an application needs ONLY while it is packaged. An example would be the credentials to your artifact repository (e.g. Artifactory or Nexus) or for file storage to an S3 bucket. These secrets are not needed in production and should never be sent to a Kubernetes cluster. Each deployed application should only get exactly the secrets it needs (and this is true even for non-production clusters).
As we also mentioned in anti-pattern 3, secret management should be handled in a flexible way that allows for easy testing and local deployment of your app. This means that the application should not really care about the source of the secrets and should only focus on their usage.
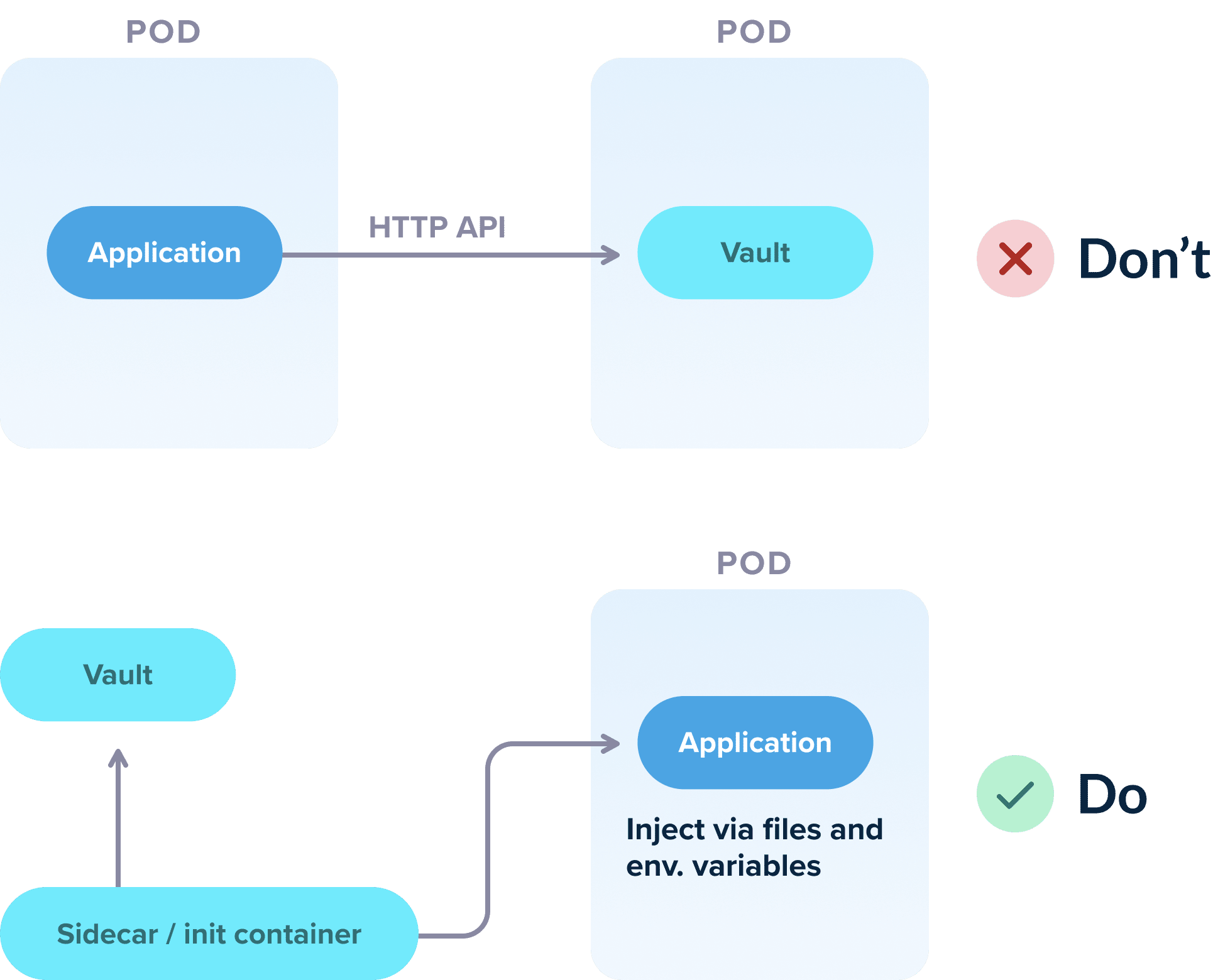
As an example, even though Hashicorp Vault has a flexible API for getting secrets and tokens, your Kubernetes application should NOT use that API directly in order to get the required information. If you do this, then testing the application locally becomes a nightmare, as a developer would need to set up a vault instance locally or mock the vault responses just to run the application.
Anti-pattern 15 – Attempting to solve all problems with Kubernetes
As with all technologies before it, Kubernetes is a specific solution that solves a specific set of problems. If you already have those problems then you will find that adopting Kubernetes greatly simplifies your workflow and gives you access to a clustering solution that is well designed and maintained.
It is important however to understand the benefits and drawbacks of adopting Kubernetes. At least in the beginning it is much easier to use Kubernetes for stateless services that will exploit the elasticity and scalability of the cluster.
Even though technically Kubernetes supports stateful services as well, it is best to run such services outside the cluster as you begin your migration journey. It is ok if you keep databases, caching solutions, artifact repositories, and even Docker registries outside the cluster (either in Virtual machines or cloud-based services).
Moving ahead
Kubernetes is a complex solution that requires a new way of thinking across all fronts (networking, storage, deployments, etc). Deploying to a Kubernetes cluster is a completely different process than deploying to Virtual machines.
Instead of reusing your existing deployment mechanisms, you should spend some time to examine all the implications of Kubernetes applications and not fall into the traps we have seen in this guide:
- Deploying images with the “latest” tag
- Hardcoding configuration inside container images
- Coupling the application with cluster constructs
- Mixing infrastructure deployments with application releases
- Doing manual deployments using kubectl
- Using kubectl for debugging clusters
- Not understanding the Kubernetes network model
- Wasting resources on static environments instead of dynamic ones
- Mixing production and non-production workloads in the same cluster
- Not understanding memory and CPU limits
- Misusing health probes
- Not understanding the benefits of Helm
- Not have effective application metrics
- Handling secrets in an ad-hoc manner
- Adopting Kubernetes even when it is not the proper solution.
Happy deployments!
Download the ebook.
Cover photo by Unsplash.