
This is the third and last part in our “Enterprise CI/CD best practices” series. See also part 1 and part 2 for the previous best practices. You can also download all 3 parts in a PDF ebook.
Best Practice 16 – Database Updates have their own Lifecycle
As more and more companies adopt continuous delivery we see an alarming trend of treating databases as an external entity that exists outside of the delivery process. This could not be further from the truth.
Databases (and other supporting systems such as message queues, caches, service discovery solutions, etc.) should be handled like any other software project. This means:
- Their configuration and contents should be stored in version control
- All associated scripts, maintenance actions, and upgrade/downgrade instructions should also be in version control
- Configuration changes should be approved like any other software change (passing from automated analysis, pull request review, security scanning, unit testing, etc.)
- Dedicated pipelines should be responsible for installing/upgrading/rolling back each new version of the database
The last point is especially important. There are a lot of programming frameworks (e.g., rails migrations, Java Liquibase, ORM migrations) that allow the application itself to handle DB migrations. Usually the first time the application startup it can also upgrade the associate database to the correct schema. While convenient, this practice makes rollbacks very difficult and is best avoided.
Database migration should be handled like an isolated software upgrade. You should have automated pipelines that deal only with the database, and the application pipelines should not touch the database in any way. This will give you the maximum flexibility to handle database upgrades and rollbacks by controlling exactly when and how a database upgrade takes place.
Best Practice 17 – Database Updates are Automated
Several organizations have stellar pipelines for the application code, but pay very little attention to automation for database updates. Handling databases should be given the same importance (if not more) as with the application itself.
This means that you should similarly automate databases to application code:
- Store database changesets in source control
- Create pipelines that automatically update your database when a new changeset is created
- Have dynamic temporary environments for databases where changesets are reviewed before being merged to mainly
- Have code reviews and other quality checks on database changesets
- Have a strategy for doing rollbacks after a failed database upgrade
It also helps if you automate the transformation of production data to test data that can be used in your test environments for your application code. In most cases, it is inefficient (or even impossible due to security constraints) to keep a copy of all production data in test environments. It is better to have a small subset of data that is anonymized/simplified so that it can be handled more efficiently.
Best Practice 18 – Perform Gradual Database Upgrades
Application rollbacks are well understood and we are now at the point where we have dedicated tools that perform rollbacks after a failed application deployment. And with progressively delivery techniques such as canaries and blue/green deployments, we can minimize the downtime even further.
Progressive delivery techniques do not work on databases (because of the inherent state), but we can plan the database upgrades and adopt evolutionary database design principles.
By following an evolutionary design you can make all your database changesets backward and forwards compatible allowing you to rollback application and database changes at any time without any ill effects
As an example, if you want to rename a column, instead of simply creating a changeset the renames the column and performing a single database upgrade, you instead follow a schedule of gradual updates as below:
- Database changeset that only adds a new column with the new name (and copies existing data from the old column). A trigger is also created that copies continuously data that is inserted in the old column to the new one. The application code is still writing/reading from the old column
- Application upgrade where the application code now writes to old column, but reads from new column
- Application upgrade where the application code writes/reads only to the new column. Trigger is dropped and you can optionally create a reverse trigger to copy data from new to old (in case of rollback)
- Database upgrade that removes the old column
The process needs a well-disciplined team as it makes each database change span over several deployments. But the advantages of this process cannot be overstated. At any stage in this process, you can go back to the previous version without losing data and without the need for downtime.
For the full list of techniques see the database refactoring website.
Best Practice 19 – All deployments must happen via the CD platform only (and never from workstations)
Continuing the theme of immutable artifacts and deployments that send to production what was deployed, we must also make sure the pipelines themselves are the only single path to production.
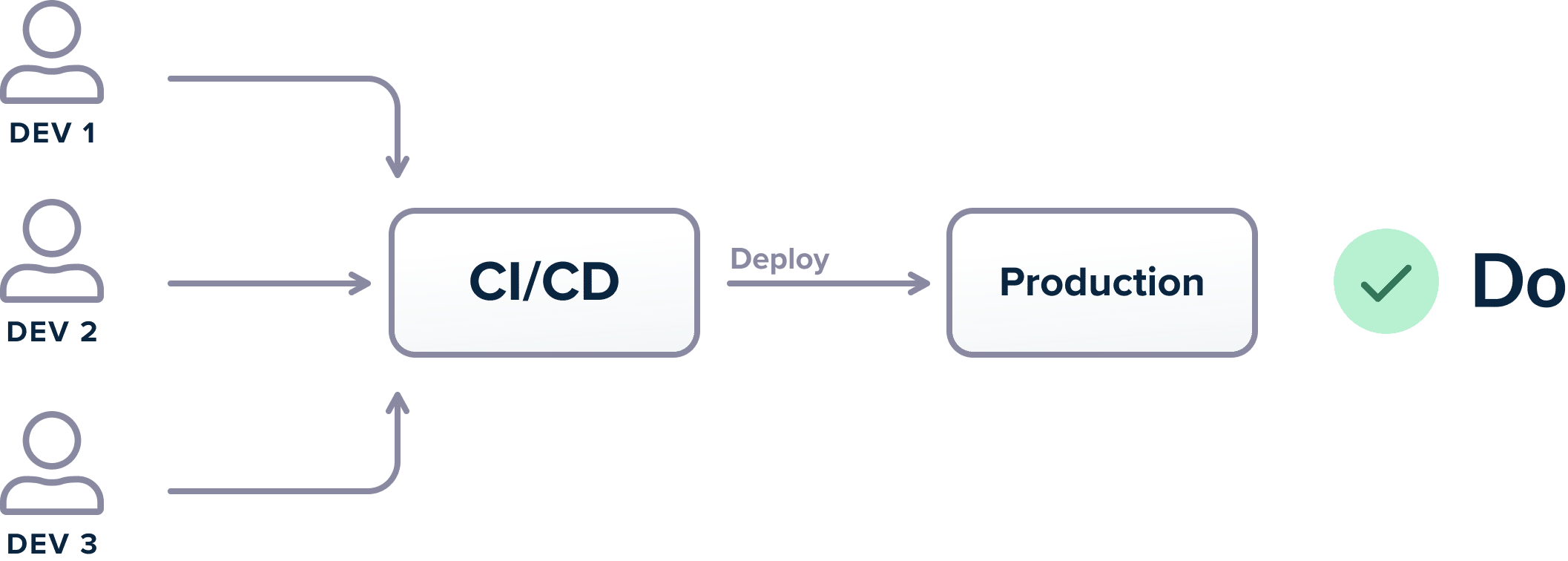
The main way to use CI/CD pipelines as intended is to make sure that the CI/CD platform is the only application that can deploy to production. This practice guarantees that production environments are running what they are expected to be running (i.e., the last artifact that was deployed).
Unfortunately, several organizations either allow developers to deploy directly from their workstations, or even to “inject” their artifacts in a pipeline at various stages.
This is a very dangerous practice as it breaks the traceability and monitoring offered by a proper CI/CD platform. It allows developers to deploy to production features that might not be committed in source control in the first place. A lot of failed deployments stem from a missing file that was present on a developer workstation and not in source control.
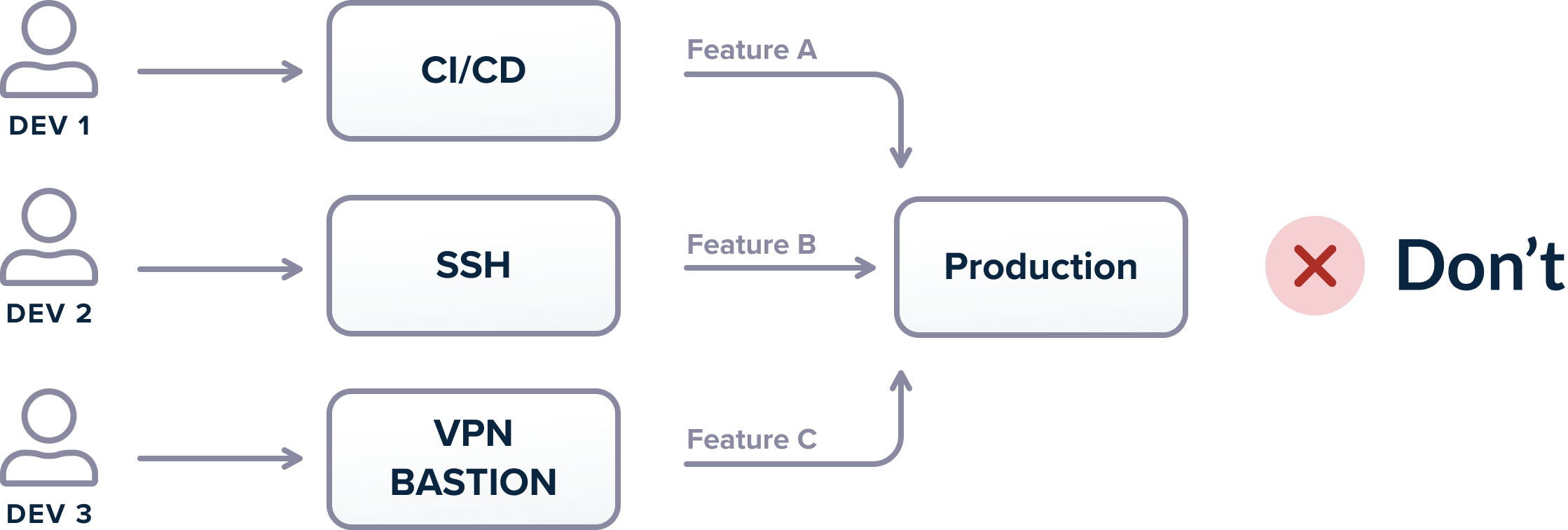
In summary, there is only a single critical path for deployments, and this path is strictly handed by the CI/CD platform. Deploying production code from developer workstations should be prohibited at the network/access/hardware level.
Best Practice 20 – Use Progressive Deployment Patterns
We already talked about database deployments in best practice 18 and how each database upgrade should be forwards and backward compatible. This pattern goes hand-in-hand with progressive delivery patterns on the application side.
Traditional deployments follow an all-or-nothing approach where all application instances move forward to the next version of the software. This is a very simple deployment approach but makes rollbacks a challenging process.
You should instead look at:
- Blue/Green deployments that deploy a whole new set of instances of the new version, but still keep the old one for easy rollbacks
- Canary releases where only a subset of the application instances move to the new version. Most users are still routed to the previous version
If you couple these techniques with gradual database deployments, you can minimize the amount of downtime involved when a new deployment happens. Rollbacks also become a trivial process as in both cases you simply change your load balancer/service mesh to the previous configuration and all users are routed back to the original version of the application.
Make sure to also look at involving your metrics (see best practices 21 and 22) in the deployment process for fully automated rollbacks.
Best Practice 21 – Metrics and logs can detect a bad deployment
Having a pipeline that deploys your application (even when you use progressive delivery) is not enough if you want to know what is the real result of the deployment. Deployments that look “successful” at first glance, but soon prove to introduce regressions is a very common occurrence in large software projects.
A lot of development teams simply perform a visual check/smoke test after a deployment has finished and call it a day if everything “looks” good. But this practice is not enough and can quickly lead to the introduction of subtle bugs or performance issues.

The correct approach is the adoption of application (and infrastructure) metrics. This includes:
- Detailed logs for application events
- Metrics that count and monitor key features of the application
- Tracing information that can provide an in-depth understanding of what a single request is doing
Once these metrics are in place, the effects of deployment should be judged according to a before/after comparison of these metrics. This means that metrics should not be simply a debugging mechanism (post-incident), but should act instead as an early warning measure against failed deployments.

Choosing what events to monitor and where to place logs is a complex process. For large applications, it is best to follow a gradual redefinition of key metrics according to past deployments. The suggested workflow is the following:
- Place logs and metrics on events that you guess will show a failed deployment
- Perform several deployments and see if your metrics can detect the failed ones
- If you see a failed deployment that wasn’t detected in your metrics, it means that they are not enough. Fine-tune your metrics accordingly so that the next time a deployment fails in the same manner you actually know it in advance
Too many times, development teams focus on “vanity” metrics, i.e., metrics that look good on paper but say nothing about a failed deployment.
Best Practice 22 – Automatic Rollbacks are in place
This is a continuation of the previous best practice. If you already have good metrics in place (that can verify the success of a deployment) you can take them to the next level by having automated rollbacks that depend on them.
A lot of organizations have great metrics in place, but only manually use them:
- A developer looks at some key metrics before deployment
- Deployment is triggered
- The developer looks at the metrics in an ad-hoc manner to see what happened with the deployment
While this technique is very popular, it is far from effective. Depending on the complexity of the application, the time spent watching metrics can be 1-2 hours so that the effects of the deployment have time to become visible.
It is not uncommon for deployments to be marked as “failed” after 6-24 hours either because nobody paid attention to the correct metrics or because people simply disregarded warnings and errors thinking that was not a result of the deployment.
Several organizations are also forced to only deploy during working hours because only at that time there are enough human eyes to look at metrics.
Metrics should become part of the deployment process. The deployment pipeline should automatically consult metrics after a deployment happens and compare them against a known threshold or their previous state. And then in a fully automated manner, the deployment should either be marked as finished or even rolled back.
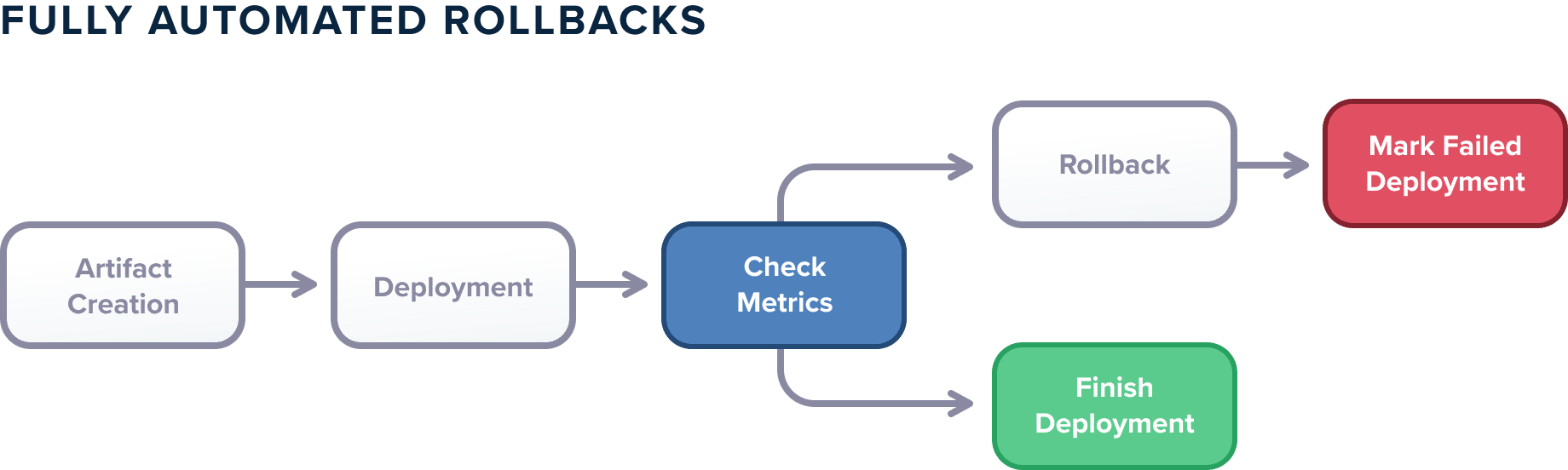
This is the holy grail of deployments as it completely removes the human factor out of the equation and is a step towards Continuous Deployment (instead of Continuous Delivery). With this approach:
- You can perform deployments at any point in time knowing that metrics will be examined with the same attention even if the time is 3 am
- You can catch early regressions with pinpoint accuracy
- Rollbacks (usually a stressful action) are now handled by the deployment platform giving easier access to the deployment process by non-technical people
The result is that a developer can deploy at 5 pm on Friday and immediately go home. Either the change will be approved (and it will be still there on Monday) or it will be rolled back automatically without any ill effects (and without any downtime if you also follow best practice 20 for progressive delivery)
Best Practice 23 – Staging Matches Production
We explained in best practice 12 that you should employ dynamic environments for testing individual features for developers. This gives you the confidence that each feature is correct on its own before you deploy it in production.
It is also customary to have a single staging environment (a.k.a. pre-production) that acts as the last gateway before production. This particular environment should be as close to production as possible so that any configuration errors can and mismatches can be quickly discovered before pushing the application deployment to the real production environment.
Unfortunately, most organizations treat the staging environment in a different way than the production one. Having a staging environment that is separate from production is a cumbersome practice as it means that you have to manually maintain it and make sure that it also gets any updates that reach production (not only in application terms but also any configuration changes).
Two more effective ways of using a staging environment are the following:
- Create a staging environment on-demand each time you deploy by cloning the production environment
- Use as staging a special part of production (sometimes called shadow production)
The first approach is great for small/medium applications and involves cloning the production environment right before a deployment happens in a similar (but possibly smaller) configuration. This means that you can also get a subset of the database and a lower number of replicas/instances that serve traffic. The important point here is that this staging environment only exists during a release. You create it just before a release and destroy it once a release has been marked as “successful”.
The main benefit of course is that cloning your production right before deployment guarantees that you have the same configuration between staging and production. Also, there is nothing to maintain or keep up-to-date because you always discard the staging environment once the deployment has finished.
This approach however is not realistic for large applications with many microservices or large external resources (e.g., databases and message queues). In those cases, it is much easier to use staging as a part of the production. The important point here is that the segment of production that you use does NOT get any user traffic, so in case of a failed deployment, your users will not be affected. The advantage again is that since this is part of the production you have the same guarantee that the configuration is the most recent one and what you are testing will behave in the same way as “real” production.
Applying these Best Practices to Your Organization
We hope that now you have some ideas on how to improve your CI/CD process. Remember however that it is better to take gradual steps and not try to change everything at once.
Consult the first section of this guide where we talked about priorities. Focus first on the best practices that are marked as “critical” and as soon as you have conquered them move to those with “high” importance.
We believe that if you adopt the majority of practices that we have described in this guide, your development teams will be able to focus on shipping features instead of dealing with failed deployments and missing configuration issues.
Cover photo by Unsplash.