
This is the second part in our “Enterprise CI/CD best practices” series. See also part 1 for for the previous part and part 3 for the next part. You can also download all 3 parts in a PDF ebook.
Best Practice 8 – Automate All your Tests
The main goal of unit/integration/functional tests is to increase the confidence in each new release that gets deployed. In theory, a comprehensive amount of tests will guarantee that there are no regressions on each new feature that gets published.
To achieve this goal, tests should be fully automated and managed by the CI/CD platform. Tests should be run not only before each deployment but also after a pull request is created. The only way to achieve the level of automation is for the test suite to be runnable in a single step.
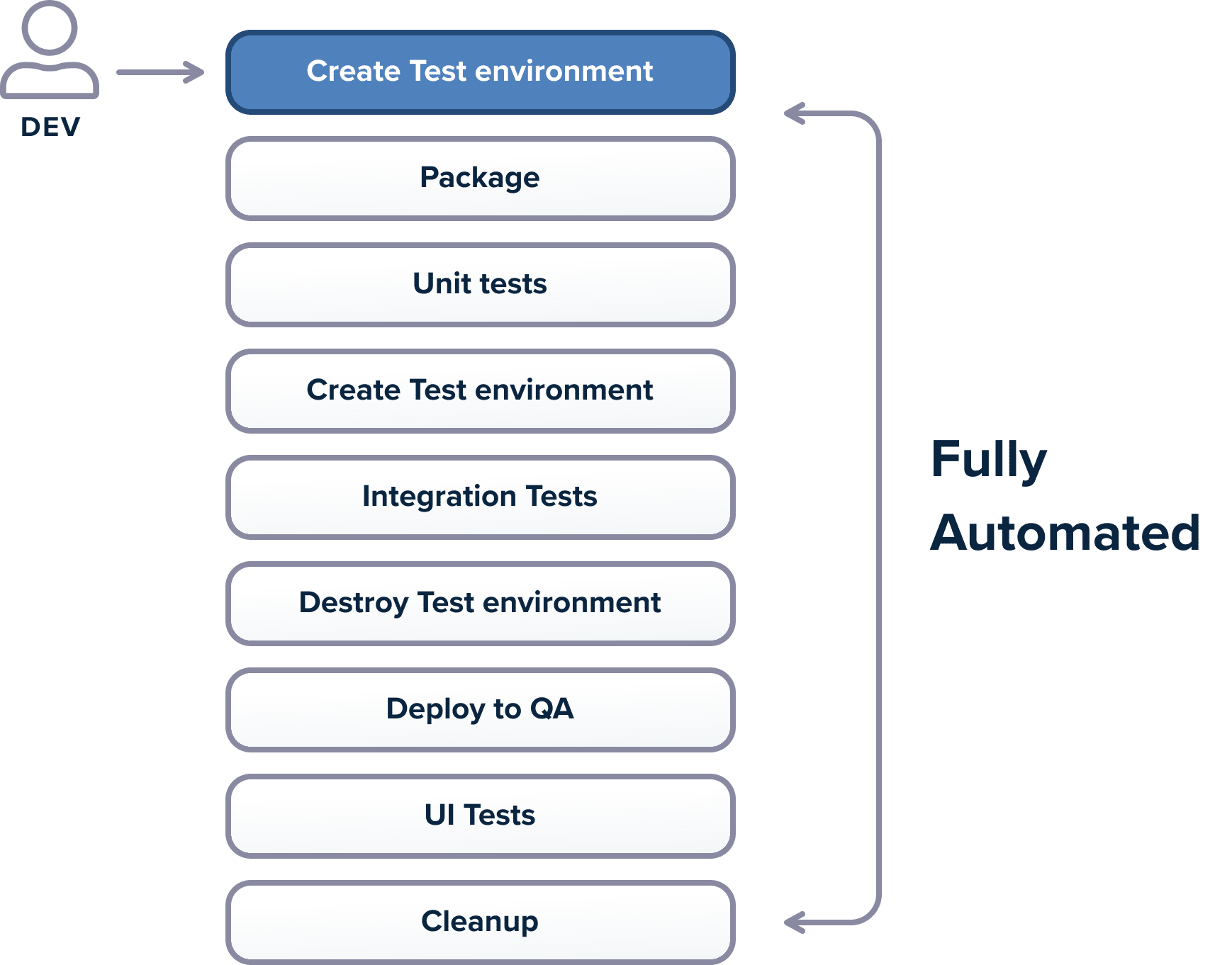
Unfortunately, several companies are still creating tests the old-fashioned way, where an army of test engineers is tasked with the manual execution of various test suites. This blocks all new releases as the testing velocity essentially becomes the deployment velocity.
Test engineers should only write new tests. They should never execute tests themselves as this makes the feedback loop of new features vastly longer. Tests are always executed automatically by the CI/CD platform in various workflows and pipelines.
It is ok if a small number of tests are manually run by people as a way to smoke test a release. But this should only happen for a handful of tests. All other main test suites should be fully automated.
Best Practice 9 – Make Your Tests Fast
A corollary of the previous section is also the quick execution of tests. If test suites are to be integrated into delivery pipelines, they should be really fast. Ideally, the test time should not be bigger than the packaging/compilation time, which means that tests should finish after five minutes, and no more than 15.
The quick test execution gives confidence to developers that the feature they just committed has no regressions and can be safely promoted to the next workflow stage. A running time of two hours is disastrous for developers as they cannot possibly wait for that amount of time after committing a feature.
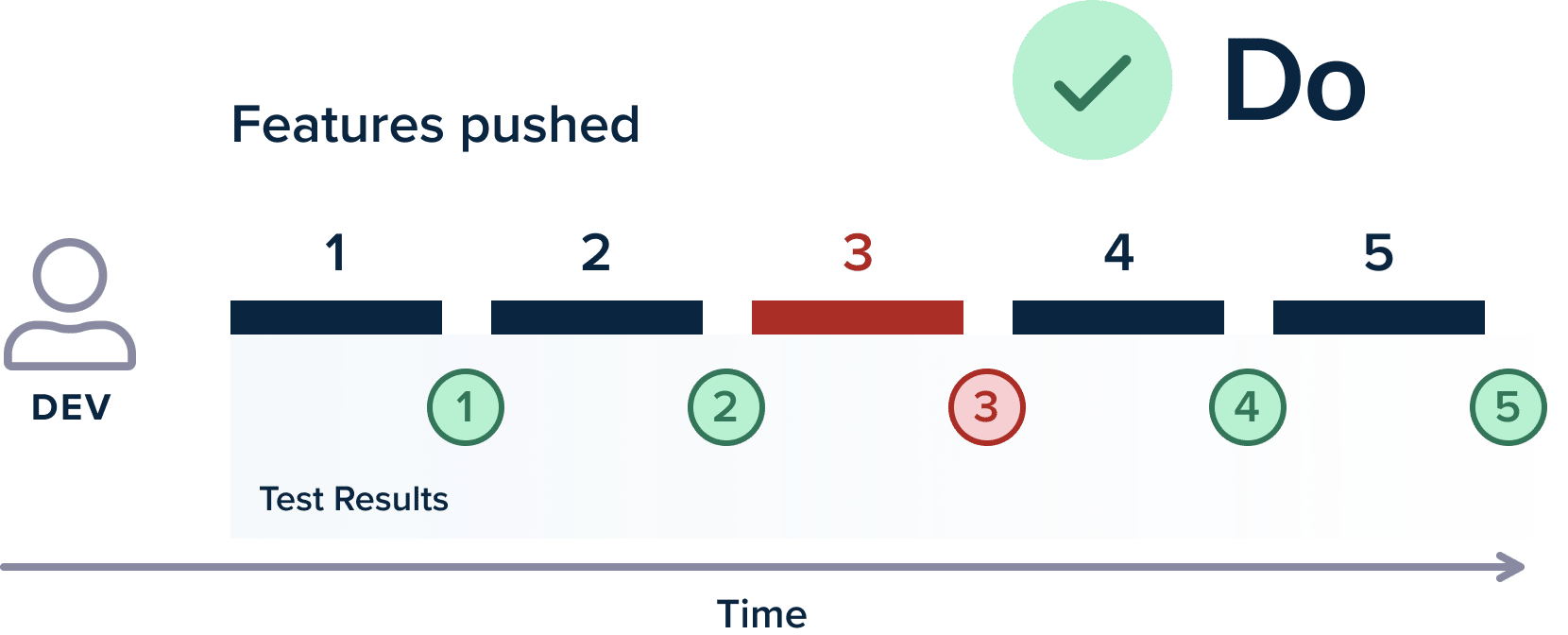
If the testing period is that large, developers just move to their next task and change their mind context. Once the test results do arrive, it is much more difficult to fix issues on a feature that you are not actively working on.
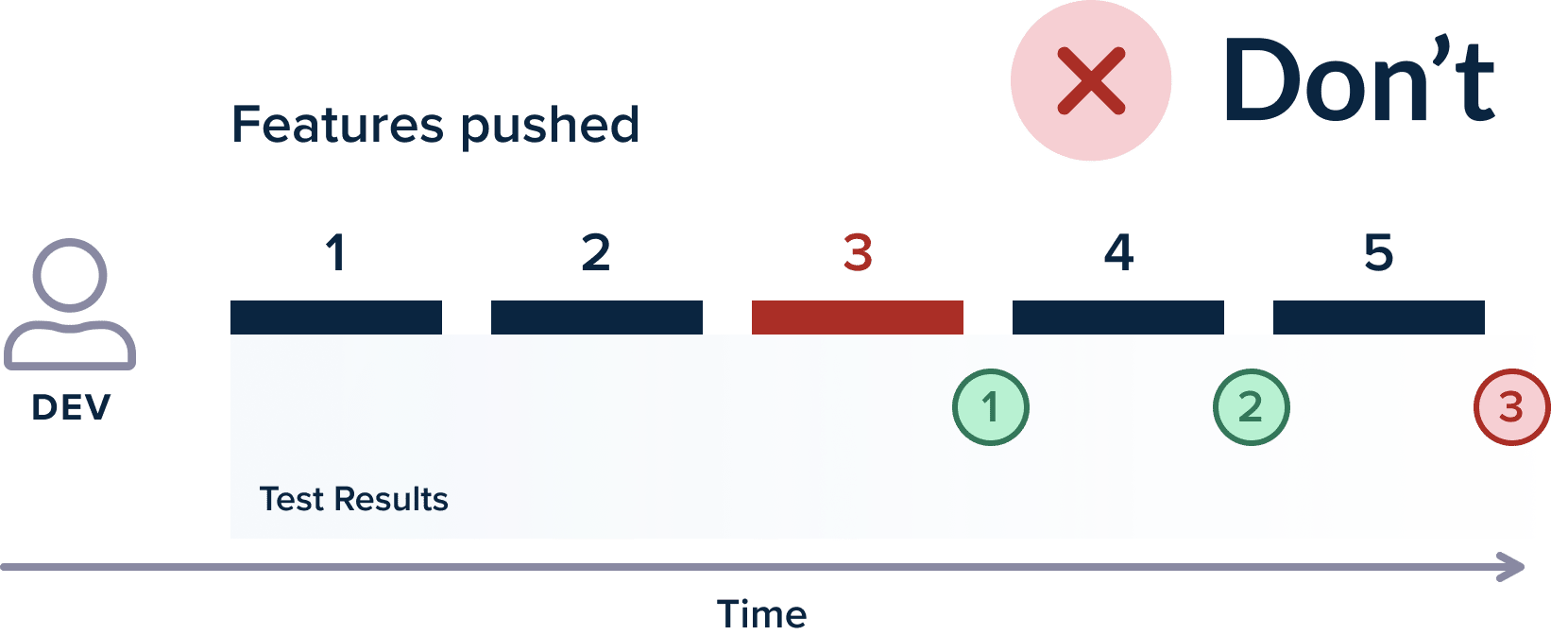
Unfortunately, the majority of time waiting for tests steps from ineffective test practices and lack of optimizations. The usual factor of a slow test is code that “sleeps” or “waits” for an event to happen, making the test run longer than it should run. All these sleep statements should be removed and the test should follow an event-driven architecture (i.e., responding to events instead of waiting for things to happen)
Test data creation is also another area where tests are spending most of their data. Test data creation code should be centralized and re-used. If a test has a long setup phase, maybe it is testing too many things or needs some mocking in unrelated services.
In summary, test suites should be fast (5-10 minutes) and huge tests that need hours should be refactored and redesigned.
Best Practice 10 – Each test auto-cleans its side effects
Generally speaking, you can split your unit tests is two more categories (apart from unit/integration or slow and fast) and this has to do with their side effects:
- Tests that have no side effects. They read only information from external sources, never modify anything and can be run as many times as you want (or even in parallel) without any complications.
- Tests that have side effects. These are the tests that write stuff to your database, commit data to external systems, perform output operations on your dependencies, and so on.
The first category (read-only tests) is easy to handle since they need no special maintenance. But the second category (read/write tests) is more complex to maintain as you need to make sure that you clean up their actions as soon as the tests finish. There are two approaches to this:
- Let all the tests run and then clean up the actions of all of them at the end of the test suit
- Have each test clean-up by itself after it runs (the recommended approach)

Having each test clean up its side-effects is a better approach because it means that you can run all your tests in parallel or any times that you wish individually (i.e., run a single test from your suite and then run it again a second or third time).
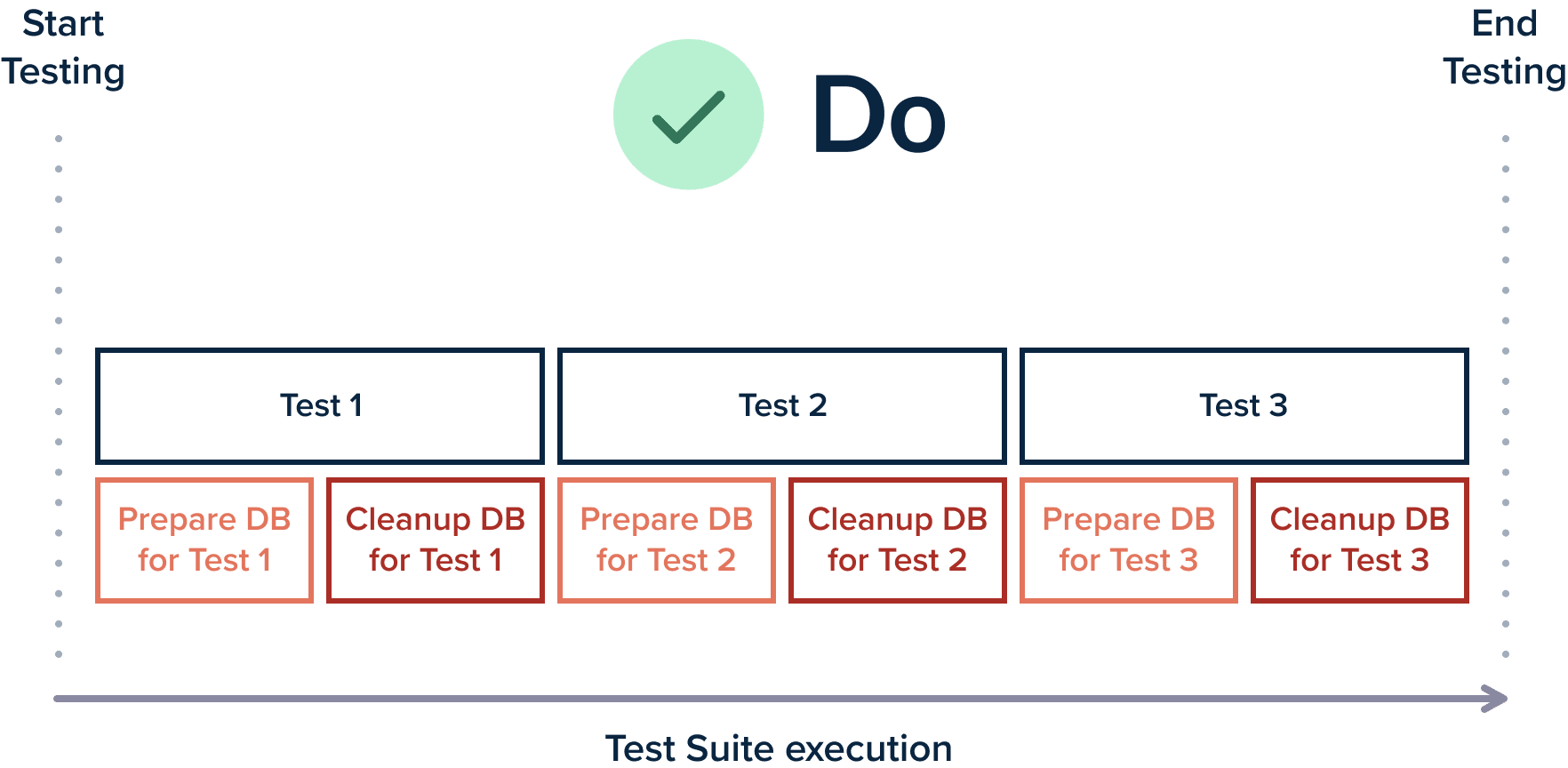
Being able to execute tests in parallel is a prerequisite for using dynamic test environments as we will see later in this guide.
Best Practice 11 – Use Multiple Test Suites
Testing is not something that happens only in a single step inside a CI/CD pipeline. Testing is a continuous process that touches all phases of a pipeline.
This means that multiple test types should exist in any well-designed application. Some of the most common examples are:
- Really quick unit tests that look at major regressions and finish very fast
- Longer integrations tests that look for more complex scenarios (such as transactions or security)
- Stress and load testing
- Contract testing for API changes of external services used
- Smoke tests that can be run on production to verify a release
- UI tests that test the user experience
This is just a sample of different test types. Each company might have several more categories. The idea behind these categories is that developers and operators can pick and choose different testing types for the specific pipeline they create.
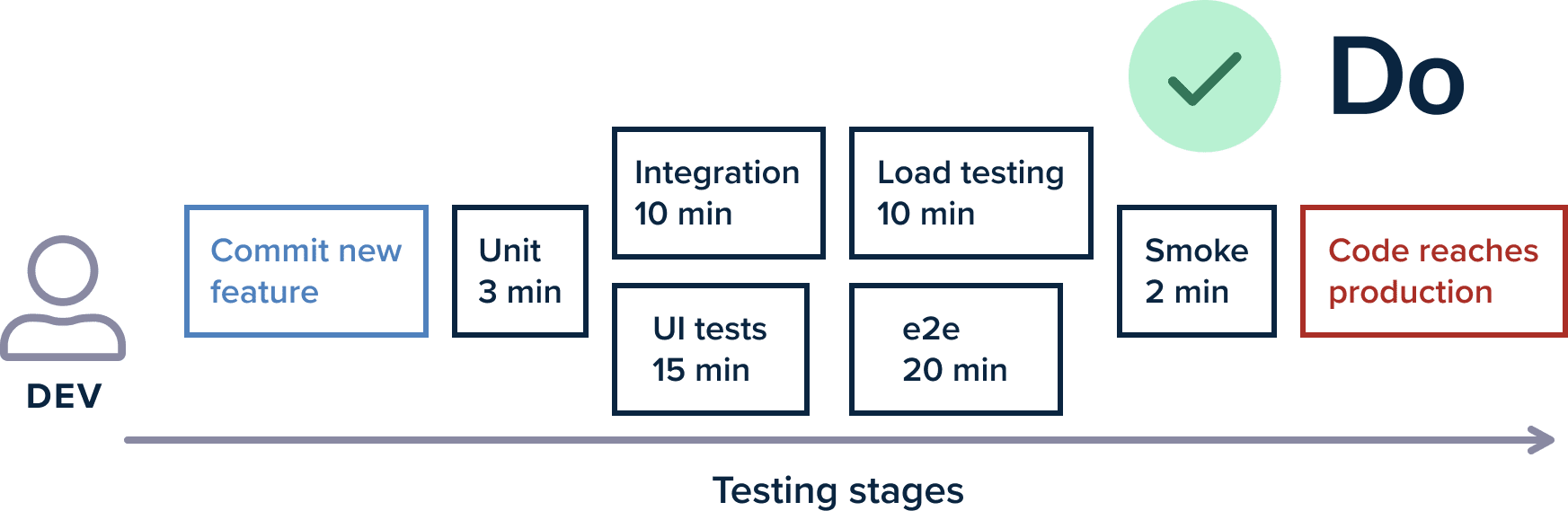
As an example, a pipeline for pull requests might not include stress and load testing phases because they are only needed before a production release. Creating a pull request will only run the fast unit tests and maybe the contact testing suite.
Then after the Pull Request is approved, the rest of the tests (such as smoke tests in production) will run to verify the expected behavior.
Some test suits might be very slow, that running them on demand for every Pull Request is too difficult. Running stress and load testing is usually something that happens right before a release (perhaps grouping multiple pull requests) or in a scheduled manner (a.k.a. Nightly builds)
The exact workflow is not important as each organization has different processes. What is important is the capability to isolate each testing suite and be able to select one or more for each phase in the software lifecycle.

Having a single test suite for everything is cumbersome and will force developers to skip tests locally. Ideally, as a developer, I should be able to select any possible number of test suites to run against my feature branch allowing me to be flexible on how I test my feature.
Best Practice 12 – Create Test Environments On-demand
The traditional way of testing an application right before going into production is with a staging environment. Having only one staging environment is a big disadvantage because it means that developers must either test all their features at once or they have to enter a queue and “book” the staging environment only for their feature.
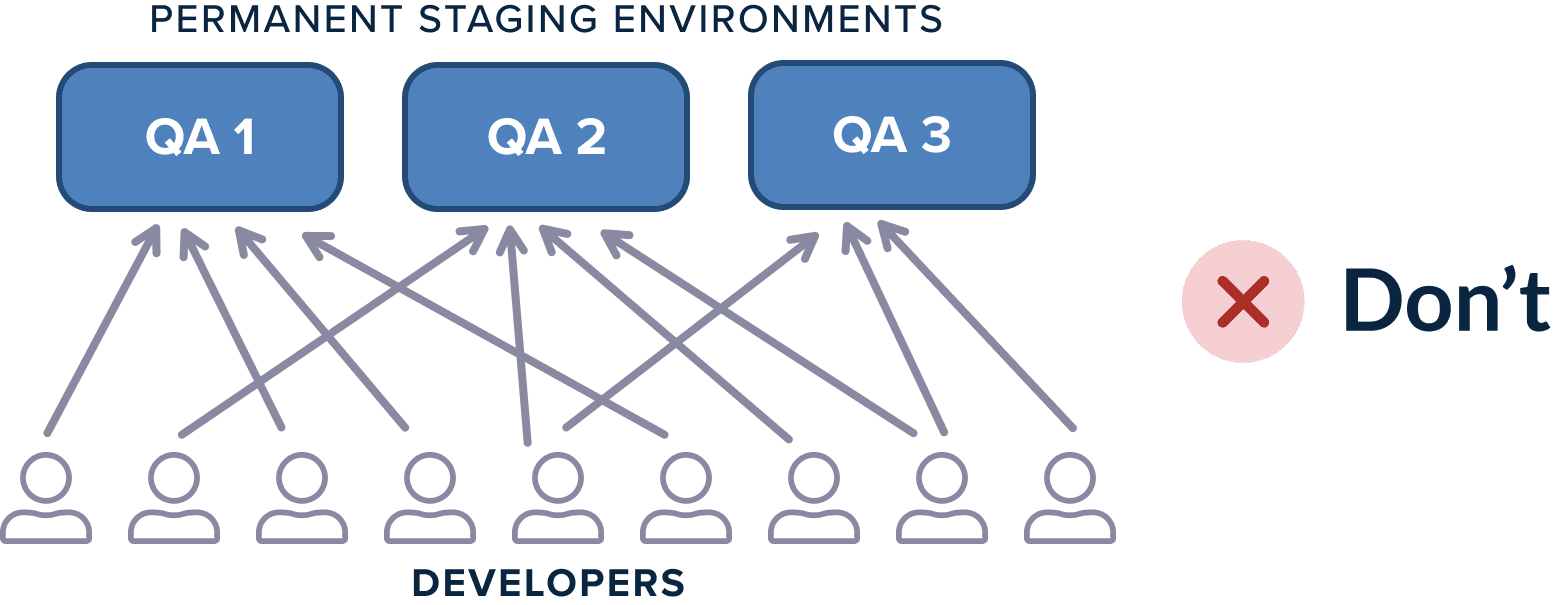
This forces a lot of organizations to create a fleet of test environments (e.g., QA1, QA2, QA3) so that multiple developers can test their features in parallel. This technique is still not ideal because:
- A maximum of N developers can test their feature (same as the number of environments) in parallel.
- Testing environments use resources all the time (even when they are not used)
- The static character of environments means that they have to be cleaned up and updated as well. This adds extra maintenance effort to the team responsible for test environments
With a cloud-based architecture, it is now much easier to create test environments on-demand. Instead of having a predefined number of static environments, you should modify your pipeline workflow so that each time a Pull Request is created by a developer, then a dedicated test environment is also created with the contents of that particular Pull Request.
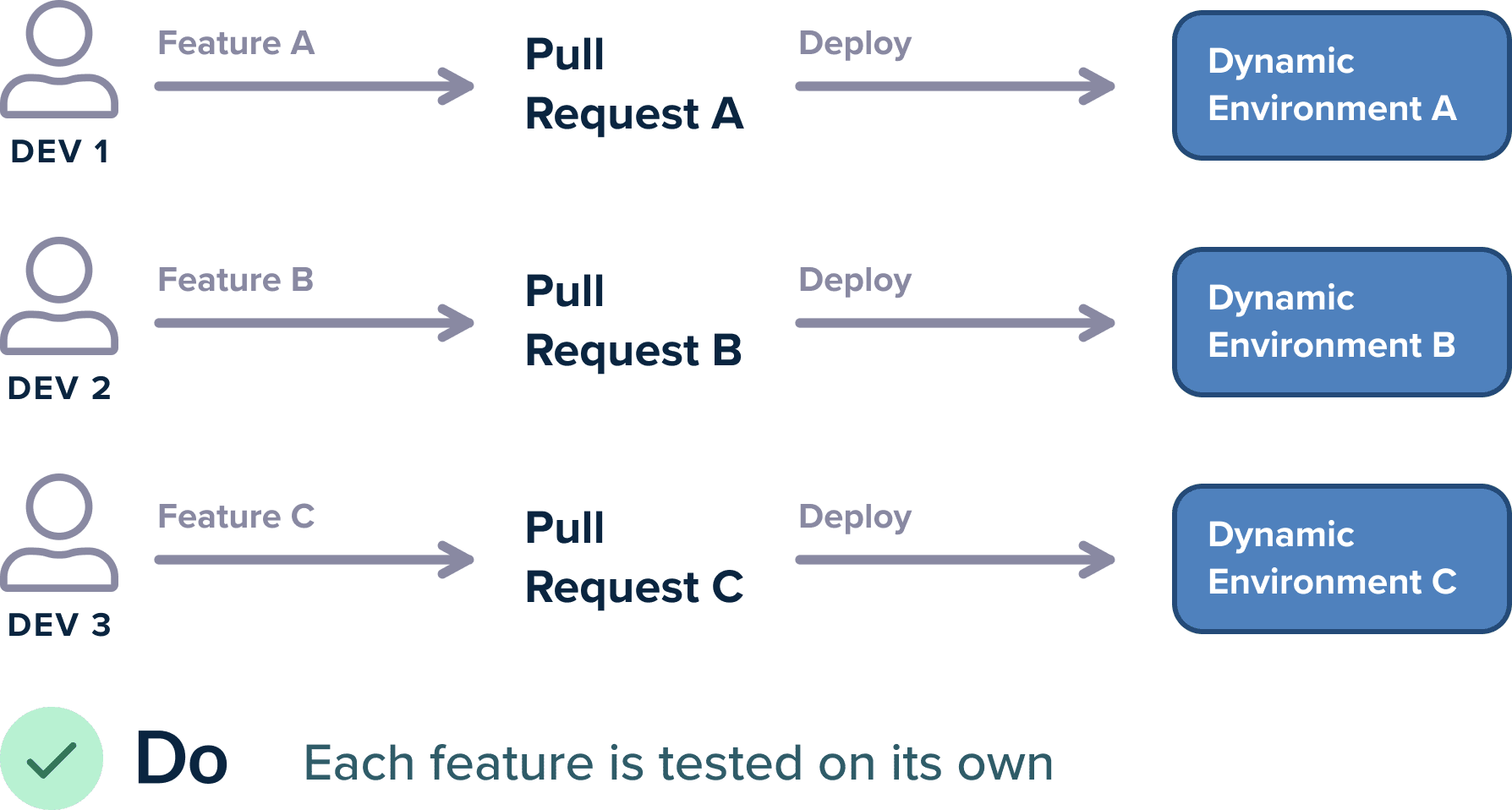
The advantages of dynamic test environments cannot be overstated:
- Each developer can test in isolation without any conflicts with what other developers are doing
- You pay for the resources of test environments only while you use them
- Since the test environments are discarded at the end there is nothing to maintain or clean up
Dynamic test environments can shine for teams that have an irregular development schedule (e.g., having too many features in flight at the end of a sprint)
Best Practice 13 – Run Test Suites Concurrently
This is a corollary of the previous best practice. If your development process has dynamic test environments, it means that different test suites can run at any point in time for any number of those environments even at the same time.
If your tests have special dependencies (e.g., they must be launched in a specific order, or they expect specific data before they can function) then having a dynamic number of test environments will further exacerbate the pre-run and post-run functions that you have for your tests.

The solution is to embrace best practice 10 and have each test prepare its state and clean up after itself. Tests that are read-only (i.e., don’t have any side-effects) can run in parallel by definitions.
Tests that write/read information need to be self-sufficient. For example, if a test writes an entity in a database and then reads it back, you should not use a hardcoded primary key because that would mean that if two test suites with this test run at the same time, the second one will fail because of database constraints.
While most developers think that test parallelism is only a way to speed up your tests, in practice it is also a way to have correct tests without any uncontrolled side effects.
Best Practice 14 – Security Scanning is part of the process
A lot of organizations still follow the traditional waterfall model of software development. And in most cases, the security analysis comes at the end. The software is produced and then a security scan (or even penetration test) is performed on the source code. The results are published and developers scramble to fix all the issues.
Putting security scanning at the end of a release is a lost cause. Some major architectural decisions affect how vulnerabilities are detected and knowing them in advance is a must not only for developers but also all project stakeholders.
Security is an ongoing process. An application should be checked for vulnerabilities at the same time as it is developed. This means that security scanning should be part of the pre-merge process (i.e as one of the checks of a Pull Request). Solving security issues in a finished software package is much harder than while it is in development.
Security scans should also have the appropriate depth. You need to check at the very least:
- Your application source code
- The container or underlying runtime where the application is running on
- The computing node and the Operating System that will host the application
A lot of companies focus only on two (or even one) of these areas and forget the security works exactly like a chain (the weakest link is responsible for the overall security)
If you also want to be proactive with security, it is best to enforce it on the Pull Request level. Instead of simply scanning your source code and then reporting its vulnerabilities, it is better to prevent merges from happening in the first place if a certain security threshold is not passed.
Best Practice 15 – Quality Scanning/Code reviews are part of the process
Similar to security scans, code scans should be part of the day-to-day developer operations. This includes:
- Static analysis of code for company-approved style/formatting
- Static analysis of code for security problems, hidden bugs
- Runtime analysis of code for errors and other issues
While there are existing tools that handle the analysis part, not all organizations execute those tools in an automated way. A very common pattern we see is enthusiastic software teams vowing to use these tools (e.g., Sonarqube) for the next software project, only to forget about them after some time or completely ignoring the warning and errors presented in the analysis reports.
In the same manner as security scans, code quality scanning should be part of the Pull Request process. Instead of simply reporting the final results to developers, you should enforce good quality practices by preventing merges if a certain amount of warning is present.
Continued on part3. You can download all 3 parts in a single PDF as an ebook.
Cover photo by Unsplash.