Article Content
What is Canary Deployment?
A canary deployment is a method that exposes a new feature to an early sub-segment of users. The goal is to test new functionality on a subset of customers before releasing it to the entire user base.
You can choose randomly or a specific group of users and roll back if anything breaks. If everything works as intended, you can gradually add more users while monitoring logs, errors, and software health.
The origin of the name
Canary birds are sensitive to gas and show visible distress when detecting it. In the past, coal miners in Australia, the UK, the US, and Canada used canary birds as an early warning system for harmful gasses like carbon monoxide (CO) and methane (CH4). Canary birds alerted the miners of danger before they recognized it.
This is part of our series of articles about software deployment.
Canary Release vs. Canary Deployment
A canary release enables you to test an early build of an entire application by splitting stable and development branches. Many open source projects use an odd/even numbering scheme to separate a stable version from a non-stable one.
Organizations often publish canary versions of a product to let tech-savvy, or early adopter users download and try it. For example, Mozilla released nightly and beta versions of Firefox, and Google uses a canary release channel for Chrome.
A canary deployment involves installing the update in a system and splitting users into two groups. A small percentage uses the canary version, while the rest of the users continue using the old version. After evaluating the canary version, you can migrate all users to the canary or roll back to the old version.
How Canary Deployments Work
Here is a general process for canary deployments:
- In the beginning, the current version receives 100% of user traffic
- A new deployment, the “canary” is performed with brand new pods and only a small amount of traffic, e.g. 5% while maintaining 95% of users on the older version.
- Different types of tests (e.g. smoke tests) can be performed on the new version with no impact on the bulk of the users.
- A decision regarding the current canary/subset of traffic takes place in an automated manner.
- If the new version works as expected, a larger portion of live traffic is sent to the new version and the process repeats again for different percentages of canary traffic (e.g. 5%, 25%, 50%, 75%, 100%).
- If the new version has issues, the service is switched back to the original version. This has minimal impact on most users. The canary version is destroyed and everything is back to the original state.
5. In the end, 100% of traffic goes to the new version and the old version can be discarded.
A Visual Example of Canary Deployments
With canaries, the new version of the application is gradually deployed, initially receiving a small subset of live traffic. Only a small number of live users view the new version while the rest continue using the current version.
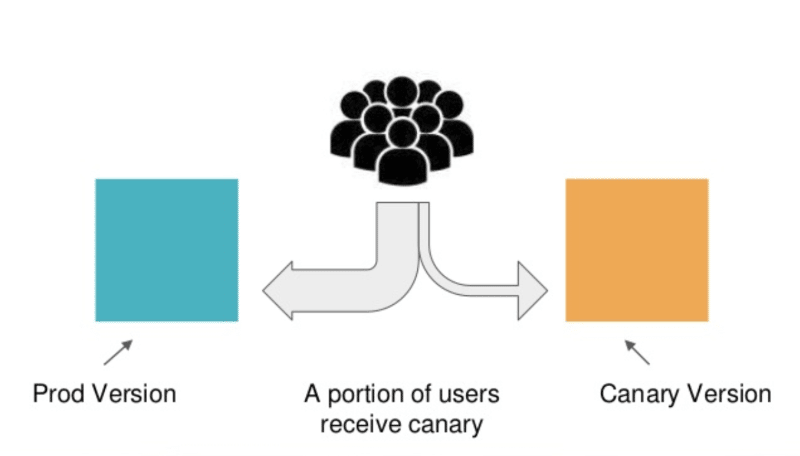
The small subset of live users acts as an early warning for potential problems in the new version. As confidence increases, the canary version is scaled up and more users are allowed to view the new version. Eventually, all live traffic goes to the new version, and thus the canary version becomes the new production version.
Canary Deployment Benefits
Here are three key benefits of canary deployments:
- Capacity testing – when deploying a new microservice to replace a legacy system, it is useful to be able to test in a production environment how much capacity you’ll need. By launching a canary version and testing it on a small fraction of your users, you can predict how much capacity you’ll need to scale the system to full size.
- Early feedback – many issues that affect end-users only occur in a production environment. Canary deployments can expose features to users in a realistic environment, to observe errors or bugs and obtain user feedback. This allows quick feedback from users, allowing developers to add new features and deliver what the end-user needs. This helps improve the software and the user experience.
- Easy rollback – in a canary deployment, if any severe issues are detected, rollback is instantaneous. It is just a matter of switching traffic back to the primary version or adjusting a feature flag.
Canary vs. Blue/Green Deployment: What is the Difference?
Both canary and blue/green deployments run two different versions of the application in parallel. The key difference is that a blue/green deployment shows only one version to users at a time, while a canary shows both in parallel, gradually exposing the canary version.
Blue/green deployments are more appropriate than canary deployments for smaller, low-risk deployments that need to be released quickly and more frequently.
How do blue/green deployments work?
Blue/green deployment is a release strategy for updating production applications without downtime. It creates two identical production application instances behind a load balancer or service mesh. At any given time, one application responds to user traffic and the other application continuously receives updates from the team’s continuous integration (CI) server.
When a new version of the environment (green) is deployed, all traffic from the user base continues going to the production environment (blue). The green version undergoes testing, and when completed, users are switched over to the green environment. The blue environment serves as a backup, enabling easy rollback in case of any problems with the green version.
Can You Do Canary Deployments in Kubernetes?
Kubernetes does not provide canary deployment functionality out of the box. What it does provide is the Deployment object which lets you do a “rolling update”. This allows you to update an application with zero downtime, by gradually replacing pods with the new version of an application.
Rolling updates are useful but the problem is that it’s difficult to roll back if something is wrong with the new version. Also, it doesn’t let you fine-tune the deployment. It is difficult to define exactly what percentage of traffic will be exposed to your canary, and you cannot define an automated process for gradual switchover from current version to the canary.
You can implement canary deployment in Kubernetes using a variety of techniques and tools. Let’s see how to do it with Codefresh, a software delivery platform powered by the Argo project.
Advanced Progressive Delivery in Kubernetes with Argo Rollouts and Codefresh
Codefresh offers advanced progressive delivery methods by leveraging Argo Rollouts, a project specifically designed for gradual deployments to Kubernetes.
Through Argo Rollouts, Codefresh can perform advanced canary deployments that support:
- Declarative configuration – all aspects of the blue/green deployment are defined in code and checked into a Git repository, supporting a GitOps process.
- Pausing and resuming – pausing a deployment and resuming it after user-defined tests have succeeded.
- Advanced traffic switching – leveraging methods that take advantage of service meshes available on the Kubernetes cluster.
- Verifying new version – creating a preview service that can be used to verify the new release (i.e smoke testing before the traffic switch takes place).
- Improved utilization – leveraging anti-affinity rules for better cluster utilization to avoid wasted resources in a canary deployment.
- Easy management of the rollout – view status and manage the deployment via the new Applications Dashboard.

The World’s Most Modern CI/CD Platform
A next generation CI/CD platform designed for cloud-native applications, offering dynamic builds, progressive delivery, and much more.
Check It Out