
GitOps as a practice for releasing software has several advantages, but like all other solutions before it, has also several shortcomings. It seems that the honeymoon period is now over, and we can finally talk about the issues of GitOps (and the current generation of GitOps tools)
In the article we will see the following pain points of GitOps:
- GitOps covers only a subset of the software lifecycle
- Splitting CI and CD with GitOps is not straightforward
- GitOps doesn’t address promotion of releases between environments
- There is no standard practice for modeling multi-environment configurations
- GitOps breaks down with auto-scaling and dynamic resources
- There is no standard practice for GitOps rollbacks
- Observability for GitOps (and Git) is immature
- Auditing is problematic despite having all information in Git
- Running GitOps at scale is difficult
- GitOps and Helm do not always work well together
- Continuous Deployment and GitOps do not mix together
- There is no standard practice for managing secrets
GitOps tools cover only a subset of the software lifecycle
This is the running theme of the current crop of GitOp tools. Even though GitOps (the methodology) has some interesting characteristics and selling points, the current GitOps tools focus only on the deployment part of an application and nothing else. They solve the “I want to put in my cluster what is described in Git” problem, but all other aspects of software development are NOT covered:
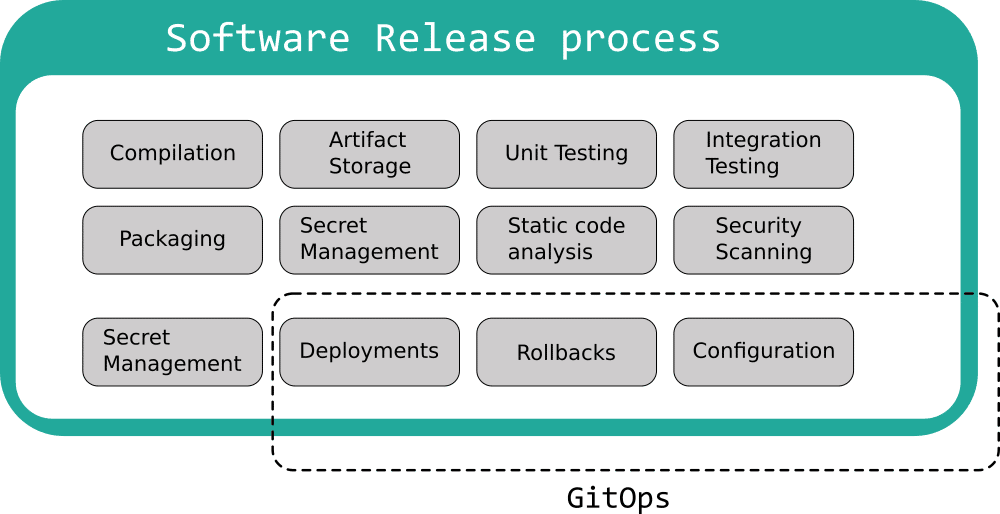
I am mentioning this because GitOps tools are sometimes marketed as the one-size-fits-all solution that will solve all your release problems and this is simply not true. First of all, GitOps requires that your deployment artifacts are already there. This means that tasks such as:
- Compiling code
- Running unit/integration tests
- Security scanning
- Static analysis
are not a concern of GitOps tools and are assumed to already be in place.
Even several deployment concerns (such as promotion between environments, secret handling, smoke testing) are conveniently left out of the GitOps paradigm, and teams that adopt GitOps need to create their own best practices for all aspects of software delivery.
Therefore you cannot simply “adopt a GitOps solution” and call it a day. GitOps is only part of your whole development strategy and you should make sure that all other processes and workflows are ready to work with GitOps.
Splitting CI and CD with GitOps is not straightforward
GitOps has been heralded as a way to decouple CI from deployments. In the classic use of a CI/CD system, the last step in the pipeline is a deployment step.

With GitOps you can keep your CI process pristine (by just preparing a candidate release) and end it with a Git commit instead of a deployment. The Git commit is picked up by a deployment solution that monitors the Git repository and takes care of the actual deployment by pulling changes in your cluster (and thus making the cluster state the same as the Git state).
This scenario is great in theory and is certainly applicable to simple scenarios, but it quickly breaks down when it comes to advanced deployments adopted by big organizations.
The canonical example of mixing CI and CD is with smoke testing. Let’s say that you want to run some smoke tests AFTER a deployment has finished and the result of the tests will decide if a rollback will take place or not.
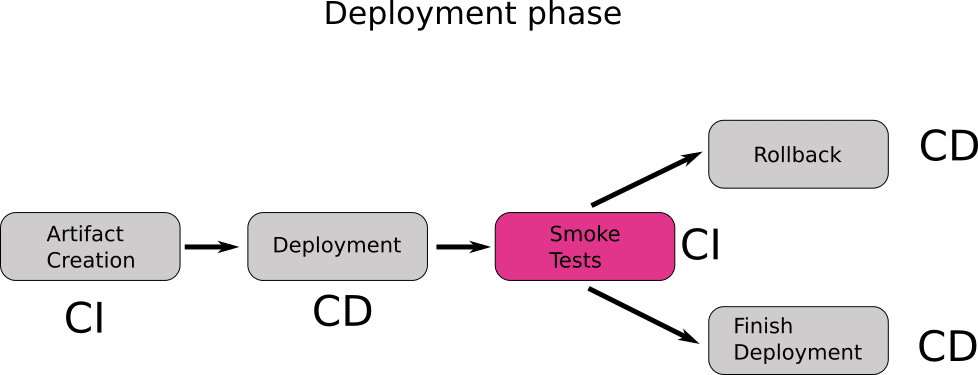
As I said in the previous point, GitOps deals only with deployment artifacts and normally does not touch (or know about) source code. But in most cases, in order to run unit tests, you need access to the source code of the application.
The current crop of GitOps tools cannot run unit/integration tests. That would require visibility in the source code along with all the testing frameworks and libraries needed for the tests. This means that you are forced to use your CI solution again in order to run the smoke tests.
The end result is a mixture of CI-CD-CI-CD components that goes against the main spirit of GitOps. There are also several underlying issues such as not knowing exactly when your environment has finished with the deployment in order to trigger the tests.
The same scenario is trivial to execute with a traditional CI/CD pipeline.
GitOps doesn’t address promotion of releases between environments
This is probably one of the most well-known issues with GitOps and one of the first topics discussed when it comes to how GitOps can work in big organizations.
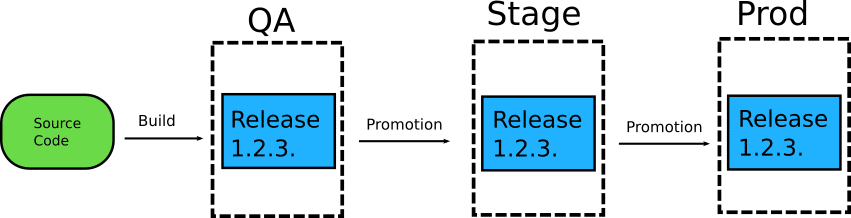
The basic scenario for one environment is obvious. You merge (or create a commit) in Git, and your cluster for environment X is now getting the new version. But how do you promote this release to environment Y?
Every time somebody declares that adopting GitOps is an easy process, I always ask how promotion between different environments works in their case. And I always get different answers:
- “We use our CI system to do this.” This means that you are again mixing CI with CD and you admit that GitOps does not cover this scenario.
- “We open a new pull request to the other environment.” This means that you are forced to have different Git branches for each environment (more on this later) and you also introduce further manual steps just for release promotion.
- “We only have one environment.” Great for small companies, but not feasible in other cases.
I am really disappointed that even the page specifically created for addressing GitOps questions says:
“GitOps doesn’t provide a solution to propagating changes from one stage to the next one. We recommend using only a single environment and avoid stage propagation altogether.”
The most popular way of handling different environments seems to be by using different Git branches. This solution has several disadvantages:
- It opens the gates for people to do commits to specific branches and include environment-specific code.
- It makes your project coupled to specific environments (instead of being generic).
- It requires extra effort to keep all branches in sync (in case of hotfixes or configuration changes).
- It puts unnecessary strain on the CI system that has to check/rebuild/unit test each individual branch.
Also, if you have a large number of environments, handling multiple branches can get quickly out of hand.
There is no standard practice for modeling multi-environment configurations
A corollary to the previous point is that if your software strategy requires multi-environment deployments, GitOps cannot help you in any way. In fact, it will make things harder for you by forcing you to adopt a specific Git branching pattern (branch per environment).
A classic example is when you have different environments per geographical region (per continent or per country).
Let’s say that my application is deployed to 10 countries and I want to promote a release to one after the other. What is the GitOps solution?
- A single repository with 10 branches. This means that you need to open/close 10 pull requests each time you do a release.
- 10 Git repositories. This means that you need to write your own solution that copies commits between the repositories (or uses Pull Requests between them).
- A single Git repository with 10 subfolders. Again you need an external solution to make sure that changes are propagated between folders.
In all cases, the promotion process is very cumbersome and current GitOps tools do not have an easy answer on what is the correct approach.
GitOps breaks down with auto-scaling and dynamic resources
One of the critical points in GitOps is that after a deployment has finished the cluster state is EXACTLY the same as what is described in the Git repository.
This is true in most simple cases, but as soon as you have dynamic values in your manifests, your GitOps tool will start fighting against you. Some classic examples are:
- The replica count if you have an autoscaler in your cluster
- The resource limits if you have an optimizer in your cluster
- Several other extra properties added by external tools (especially values with dates or timestamps)
As soon as your cluster state changes, your GitOps tool will try to sync the initial value from Git and in most cases, this is not what you want.
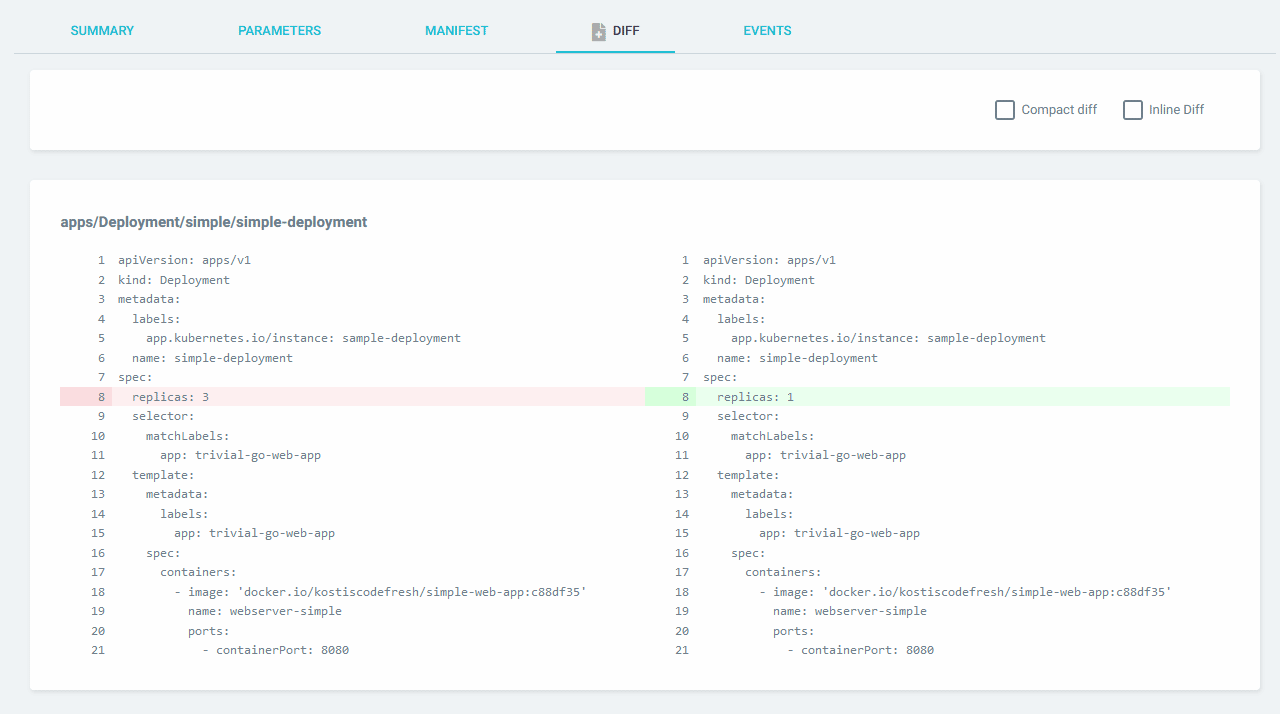
Argo supports custom diffs and Flux has a recommendation but I consider these workarounds as simple hacks that move away from the main GitOps promise and create several other issues in the long run.
There is no standard practice for GitOps rollbacks
The fact that all your cluster history is in Git makes rollbacks in GitOps (supposedly) very easy.
If you want to rollback to a previous version, you simply use a past commit for your sync operation.
In practice, however, it is not entirely clear what exactly we mean by “use a previous commit”. Different people use different ways to rollback:
- You can simply point your cluster to a previous Git hash and let your GitOps tool sync that hash. This is the fastest way to rollback, but by definition leaves your cluster in an inconsistent state as the cluster does not contain what is described in the last Git commit.
- You can use the standard Git reset, Git revert commands, and again let your GitOps tool perform the sync operation as usual. This keeps the GitOps promise (of having in the cluster what is in the Git repo) but of course, requires manual intervention.
- You can have a combination where the GitOps tool itself both syncs a previous Git hash to the cluster and auto-commits (or reverts) to the git repo in order to keep the consistency. This is very complex to accomplish and not all teams want to let their deployment solution have write access to their Git repo.
It goes without saying that different people might want a completely different approach for rollbacks. At the time of writing, however, the present GitOps tools have very little support and guidance on how you perform a rollback in a standard way.
Observability for GitOps (and Git) is immature
GitOps is great for looking at your cluster state having the guarantee that it matches your Git state. Git hashes and commits however are only useful to developers and operators. Business stakeholders have no interest in which Git hash is now deployed at the cluster.
Therefore, while GitOps is great for observability on a technical level, it is important to remember that some of the most useful questions in a software team are the following:
- Does our production environment contain feature X?
- Has feature X cleared our staging environment?
- Are bugs X, Y present only in staging or also in production as well?
These kinds of questions are pretty important for most product owners and project managers and finding an answer should be as quick as possible.
Currently, GitOps tools work at the lowest level (i.e. Git hash) and don’t have any connections to the business value of each deployment. It is up to developers/operators to find the correlation between a production deployment and the value it brings to the business.
At their current state, GitOps tools are great for observing the content of a cluster on a technical level but fail miserably on monitoring the business metrics of each deployment.
Auditing is problematic despite having all information in Git
A corollary to the previous point is that just because you have access to the whole deployment history of a cluster in the form of Git commits, doesn’t mean that you can easily audit its functionality.
The current crop of Git tools are great for managing Git hashes but when it comes to searching and understanding business value, they can only provide simple free-text search capabilities as Adam mentioned already in Lack of Visibility.
Let’s say that you are using GitOps for a specific project and you know that the Git history matches your cluster history. How quickly can you answer the following questions just by looking at the Git History?
- How long did feature X stay in the staging environment before going to production?
- What is the worst, best, and average lead time (period starting from a developer performing a commit until the time it actually reached production) of the previous 2 months?
- What percentage of deployments to environment X were successful and what had to be rolled back?
- How many features exist in environment X but are not in environment Y yet?
These questions are very common in a large software team and unless you have a specialized tool on top of your deployment platform, it is very hard to answer them by only having access to a Git repository and its history.
Running GitOps at scale is difficult
This point was also touched by Adam in the part “the proliferation of Git repositories”. If you adopt GitOps in a large company with a big number of environments and applications, the number of Git repositories quickly skyrockets.
This makes it very hard to keep track of what is going on in each environment and can quickly lead to configuration duplication or people making commits to specific environments (instead of using shared configuration).
For example, if you have 20 git repositories with Kubernetes manifests and you need to make a central change (e.g. adding a new company-wide label on each deployment) you need to manually make 20 Git commits or create some glue code that does it for you.
On the other end of the spectrum, you could have a single Git repository for all environments (or clusters) where all people collaborate along with the CI/CD systems.
This creates the problem of Git conflicts (where your git repos are touched by many CI processes and pushes are failing because the git repository was changed in between) as already explained by Adam.
Having also a single gigantic Git repository can quickly become a bottleneck in your GitOps processes introducing performance issues when the repository is scanned for changes.
GitOps and Helm do not always work well together
Helm is the package manager for Kubernetes and is typically seen as the de-facto standard for deploying 3rd party applications in your cluster. It can also be used for your own deployments.
Helm works by marrying a set of templates for Kubernetes manifests along with their runtime values that are merged to create the end result of what is deployed in the cluster.
While you can provide a values.yml file on the fly when a Helm release is installed, a best practice is to also commit the values file to Git. You can have different value values for each environment (e.g. qa/staging/production).
Helm on its own does not dictate where those 3 components (source code, manifests, values) should reside. You can keep all of them in the same Git repository or 3 different repositories. The accepted practice however is that if you have values for different environments, you don’t keep them in the same place as the templates. The templates (the chart itself) is stored in a chart repository and the specific values for each environment are stored in a git repository.
This means that during a deployment the following must happen:
- The chart should be downloaded from the chart repository
- The values should be fetched from a Git repository
- The values and the chart should be merged in order to create a set of Kubernetes manifests
- The manifests should be applied to the cluster.
This is only for the initial deployment. Following the GitOps paradigm, the Git repository that contains the values file should be monitored along with the chart that exists in the chart repo. If their merge result is different from the cluster state a new deployment should take place.
At the time of writing, neither Flux nor ArgoCD support this basic Helm scenario. There are several workarounds and limitations that you have to accept if you wish to use GitOps with Helm charts making the process much more complex than needed.
Continuous Deployment and GitOps do not mix together
GitOps is great as a Continuous Delivery solution, where each commit results in a release candidate ready to be pushed in production. Continuous deployment on the other hand is the full journey of a commit straight into production without any human intervention.
You are practicing Continuous Deployment if as a developer you can commit something Friday afternoon and then immediately start your weekend. In a few minutes, your commit should land in production after it passes all quality gates and tests.
GitOps by definition is powered by Pull requests on a repository that contains your manifests. And in most cases, a human needs to look and approve these pull requests. This means that practicing GitOps involves at least some manual steps for handling these Pull requests.
In theory, one could practice Continuous Deployment while still adopting GitOps by fully automating the Pull request part. Current GitOps (and Git) tools are not however created with this automation in mind, so you are on your own if you want to take this route.
Remember that Continuous Deployment is not the holy grail. For several organizations, Continuous Delivery is already enough and in some cases, you might even be bound by legislation and have to specifically disallow fully automated deployments.
But if you want to have the faster lead time possible, GitOps is not the best solution out there.
There is no standard practice for managing secrets with GitOps
This is a very well known problem with GitOps, so I am including it for completeness. Secret handling is one of the most important aspects of software deployment and yet, GitOps does not address them.
There is no single accepted practice on how secrets should be managed. If they are stored in Git, they need to be encrypted and thus have their own workflow process during a deployment. If they are not stored in Git, then the whole idea of having your cluster state the same as Git is not true anymore.
Secrets management is one of those areas where each company does their own thing, so at the very least I would expect GitOps tools to offer an out of the box solution for them.
Moving to GitOps 2.0
You might have noticed the version at the title of this article. GitOps in its present state is affected by all issues we outlined. But it doesn’t have to be this way forever!
As with normal software releases, we can continuously iterate on our approach and improve the shortcomings in subsequent versions. This is why we (at Codefresh) already envision a new version of GitOps (named 2.0) which will become the next chapter in the GitOps saga and address all the present issues.
Cover photo by Unsplash.
