
In our big guide for GitOps problems, we briefly explained (see points 3 and 4) how the current crop of GitOps tools don’t really cover the case of promotion between different environments or how even to model multi-cluster setups.
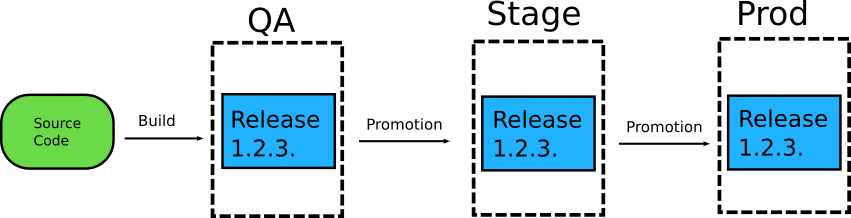
The question of “How do I promote a release to the next environment?” is becoming increasingly popular among organizations that want to adopt GitOps. And even though there are several possible answers, in this particular article I want to focus on what you should NOT do.
You should NOT use Git branches for modeling different environments. If the Git repository holding your configuration (manifests/templates in the case of Kubernetes) has branches named “staging”, “QA”, “Production” and so on, then you have fallen into a trap.
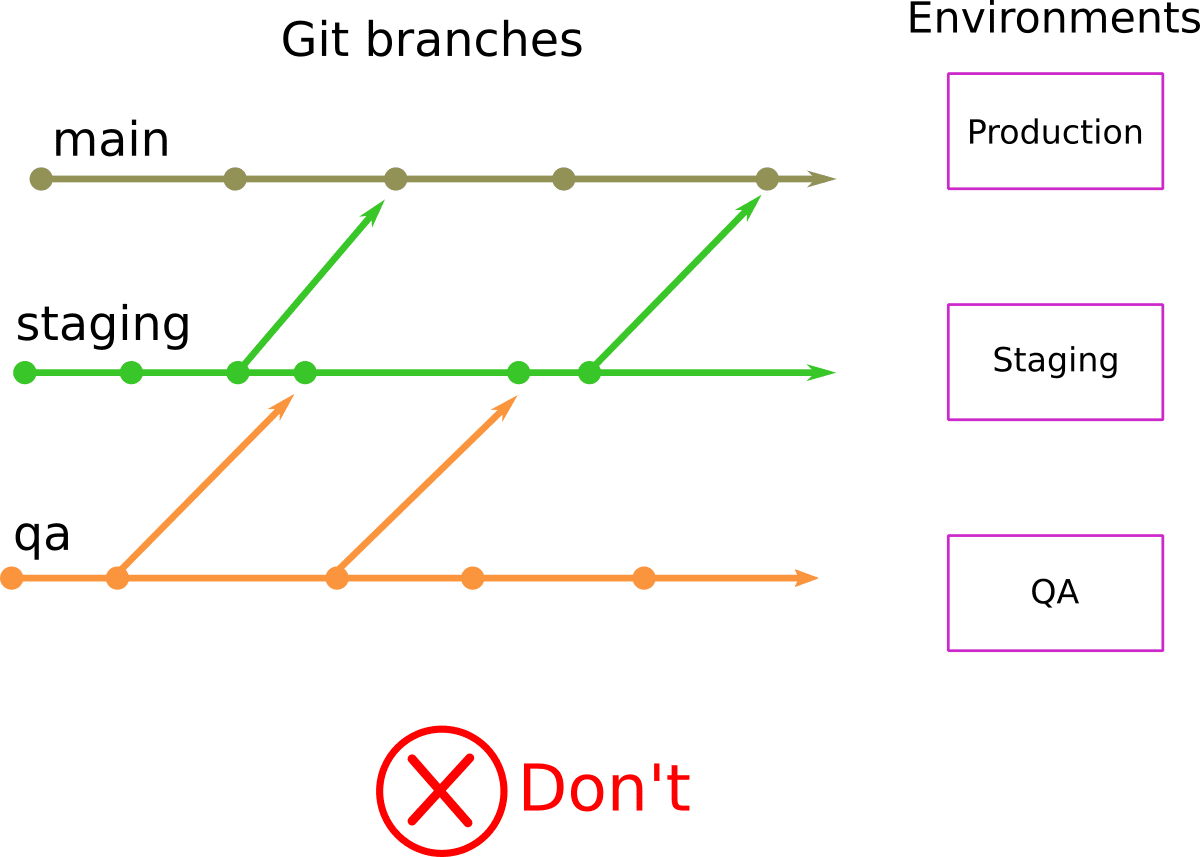
Let me repeat that. Using Git branches for modeling different environments is an anti-pattern. Don’t do it!
We will explore the following points on why this practice is an anti-pattern:
- Using different Git branches for deployment environments is a relic of the past.
- Pull requests and merges between different branches is problematic.
- People are tempted to include environment specific code and create configuration drift.
- As soon as you have a large number of environments, maintenance of all environments gets quickly out of hand.
- The branch-per-environment model goes against the existing Kubernetes ecosystem – see GitOps Kubernetes for more info.
Using branches for different environments should only be applied to legacy applications.
When I ask people why they chose to use Git branches for modelling different environments, almost always the answer is a variation of “we’ve always done it that way,” “it feels natural,” “this is what our developers know,” and so on.
And that is true. Most people are familiar with using branches for different environments. This practice was heavily popularized by the venerable Git-Flow model. But since the introduction of this model, things have changed a lot. Even the original author has placed a huge warning at the top advising people against adopting this model without understanding the repercussions.
The fact is that the Git-flow model:
- Is focused on application source code and not environment configuration (let alone Kubernetes manifests).
- Is best used when you need to support multiple versions of your application in production. This happens, but is not usually the case.
I am not going to talk too much about Git-flow here and its disadvantages because the present article is about GitOps environments and not application source code, but in summary, you should follow trunk-based development and use feature-flags if you need to support different features for different environments.
In the context of GitOps, the application source code and your configuration should also be in different Git repositories (one repository with just application code and one repository with Kubernetes manifests/templates). This means that your choice of branching for the application source code should not affect how branches are used in the environment repository that defines your environments.
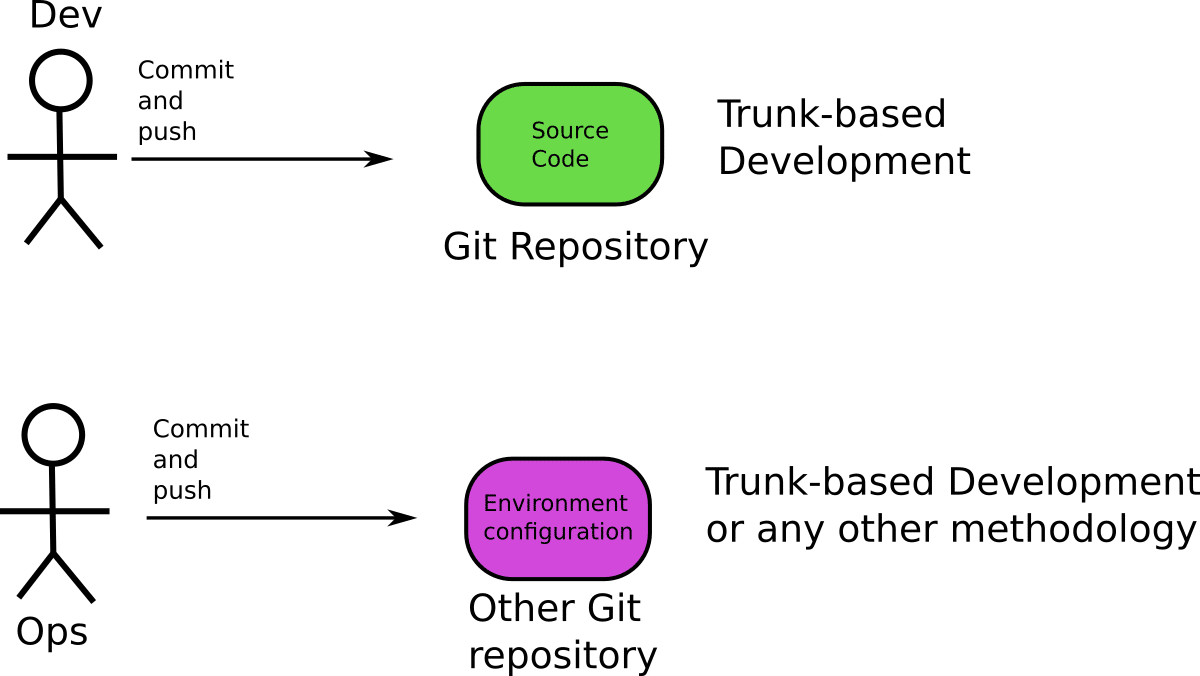
When you adopt GitOps for your next project, you should start with a clean slate. Application developers can choose whatever branching strategy they want for the application source code (and even use Git-flow), but the configuration Git repository (that has all the Kubernetes manifests/templates) should NOT follow the branch-per-environment model.
Promotion is never a simple Git merge
Now that we know the history of using a branch-per-environment approach for deployments, we can talk about the actual disadvantages.
The main advantage of this approach is the argument that “Promotion is a simple git merge.” In theory, if you want to promote a release from QA to staging, you simply merge your QA branch into the staging branch. And when you are ready for production, you again merge the staging branch into the production branch, and you can be certain that all changes from staging have reached production.
Do you want to see what is different between production and staging? Just do a standard git diff between the two branches. Do you want to backport a configuration change from staging to QA? Again, a simple Git merge from the staging branch to qa will do the trick.
And if you want to place extra restrictions on promotions, you can use Pull Requests. So even though anybody could merge from qa to staging, if you want to merge something in the production branch, you can use a Pull Request and demand manual approval from all critical stakeholders.
This all sounds great in theory, and some trivial scenarios can actually work like this. But in practice, this is never the case. Promoting a release via a Git merge can suffer from merge conflicts, unwanted changes, and even the wrong order of changes.
As a simple example, let’s take this Kubernetes deployment that is currently sitting in the staging branch:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-deployment
spec:
replicas: 15
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: backend
image: my-app:2.2
ports:
- containerPort: 80
Your QA team has informed you that version 2.3 (which is in the QA branch) looks good, and it is ready to be moved to staging. You merge the QA branch to the staging branch, promoting the application and think that everything is good.
What you didn’t know is that somebody also changed the number of replicas in the QA branch to 2 because of some resource limitations. With your Git merge, you not only deployed 2.3 to staging, but you also scaled the replicas to 2 (instead of 15), and that is probably something that you don’t want.
You might argue that it would be easy to look at the replica count before merging, but remember that in a real scenario you have a large number of applications with a big number of manifests that are almost always templated (via Helm or Kustomize). So understanding what changes you want to bring and what to leave behind is not a trivial task.
And even if you do find changes that should not be promoted, you need to manually choose the “good” parts using git cherry-pick or other non-standard methods which are a far cry from the original “simple” Git merge.
But even if you are aware of all the changes that can be promoted, there are several cases where the order of promotion is not the same as the order of committing. As an example, the following 4 changes happen to the QA environment.
- The ingress of the application is updated with an extra hostname.
- Release 2.5 is promoted to the QA branch and all QA people start testing.
- A problem is found with 2.5 and a Kubernetes configmap is fixed.
- Resource limits are fine-tuned and committed to QA.
It is then decided that the ingress setting and the resource limits should move to the next environment (staging). But the QA team has not finished testing with the 2.5 release.
If you blindly merge the QA branch to the staging branch, you will get all 4 changes at once, including the promotion of 2.5.
To resolve this, again you need to use git cherry-pick or other manual methods.
There are even more complicated cases where the commits have dependencies between them, so even cherry-pick will not work.
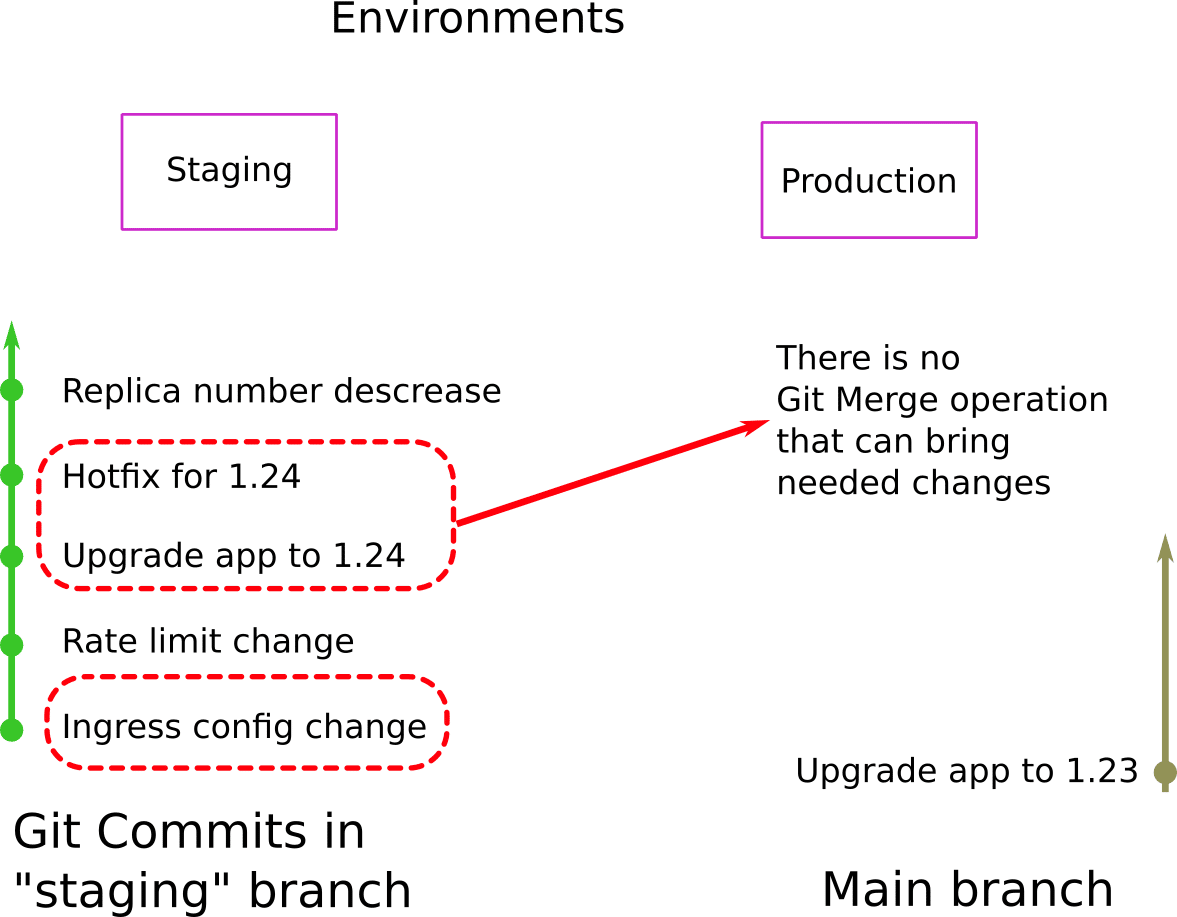
In the example above, release 1.24 must be promoted to production. The problem is that one of the commits (the hotfix) contains a multitude of changes where some of them depend on another commit (the ingress config change) which itself cannot be moved to production (as it only applies only to staging). So even with cherry-picks, it is impossible to bring only the required changes from staging to production.
The end result is that promotion is never a simple Git merge. Most organizations will also have a large number of applications that go on a large number of clusters, composed by a large number of manifests. Manually choosing commits is a losing battle.
Configuration drift can be easily created by environment-specific changes
In theory, configuration drift should not be an issue with Git merges. If you make a change in staging and then merge that branch to production, then all your changes should transfer to the new environment.
In practice, however, things are different because most organizations only merge to one direction, and team members are easily tempted to change upstream environments and never back-port the changes to downstream environments.
In the classic example with 3 environments for QA, Staging, and Production, the direction of Git merges only goes to one direction. People merge the qa branch to staging and the staging branch to production. This means that changes only flow upwards.
QA -> Staging -> Production.
The classic scenario is that a quick configuration change is needed in production (a hotfix), and somebody applies the fix there. In the case of Kubernetes, this hotfix can be anything such as a change in an existing manifest or even a brand new manifest.
Now Production has a completely different configuration than staging. Next time a release is promoted from Staging to Production, Git will only notify you on what you will bring from Staging. The ad hoc change on production will never appear anywhere in the Pull Request.
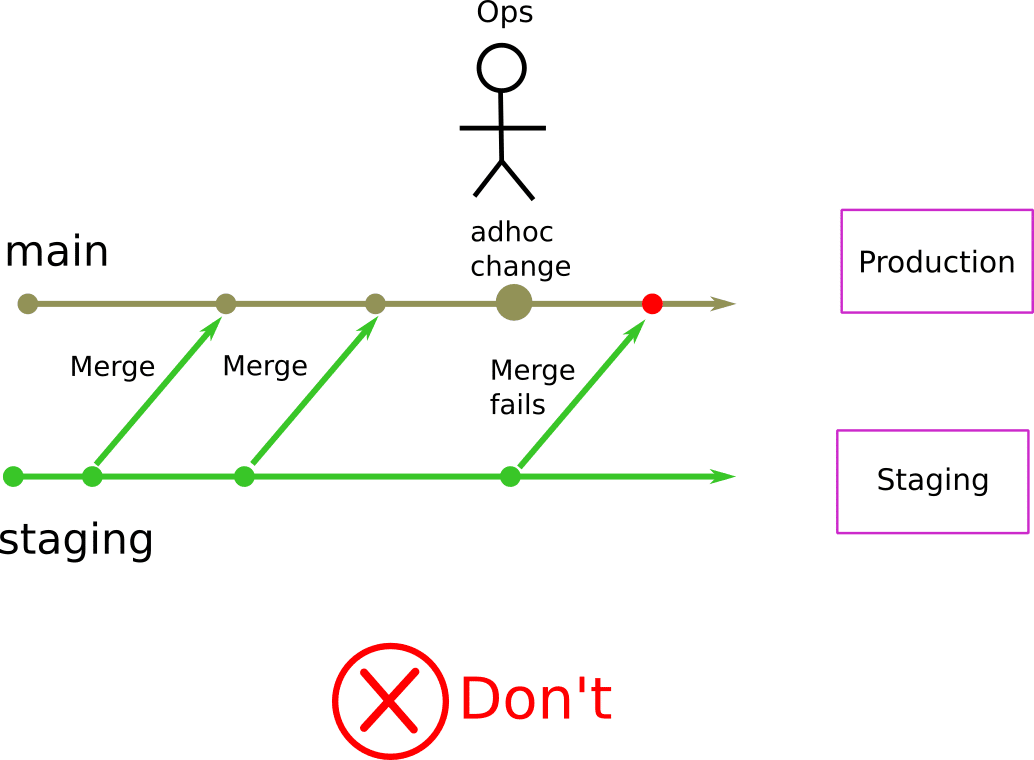
This means that all subsequent deployments can fail, as production now has an undocumented change that will never be detected by any subsequent promotions.
In theory, you could backport such changes and merge periodically all commits from production to staging (and staging to QA). In practice, this never happens due to the reasons outlined in the previous point.
You can imagine that a large number of environments (and not just 3) further increases the problem.
In summary, promoting releases by Git merges does not solve configuration drift and in fact makes it even more problematic as teams are tempted to make ad hoc changes that are never promoted in sequence.
Managing different Git branches for a large number of environments is a losing battle
In all the previous examples, I only used 3 environments (qa-> staging-> production) to illustrate the disadvantages of branch-based environment promotion.
Depending on the size of your organization, you will have many more environments. If you factor in other dimensions such as geographical location, the number of environments can quickly skyrocket.
For example, let’s take a company that has 5 environments:
- Load Testing
- Integration testing
- QA
- Staging
- Production
Then let’s assume that the last 3 environments are also deployed to EU, US, and Asia while the first 2 also have GPU and Non-GPU variations. This means that the company has a total of 13 environments. And this is for a single application.
If you follow a branch-based approach for your environments:
- You need to have 13 long living Git branches at all times.
- You need 13 pull requests for promoting a single change across all environments.
- You have a two dimensional promotion matrix with 5 steps upwards and 2-3 steps outwards.
- The possibilities for wrong merges, configuration drift and ad-hoc changes is now non-trivial across all environment combinations.
In the context of this example organization, all previous issues are now more prevalent.
The branch-per-environment model goes against Helm/Kustomize
Two of the most popular Kubernetes tools for describing applications are Helm and Kustomize. Let’s see how these two tools recommend modeling different environments.
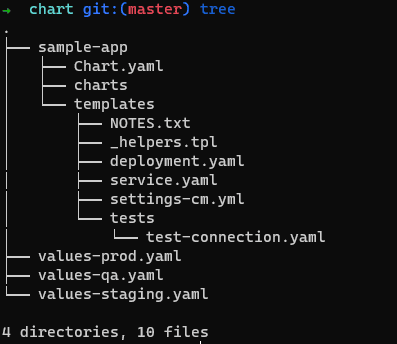
For Helm, you need to create a generic chart that itself accepts parameters in the form of a values.yaml file. If you want to have different environments, you need multiple values files.
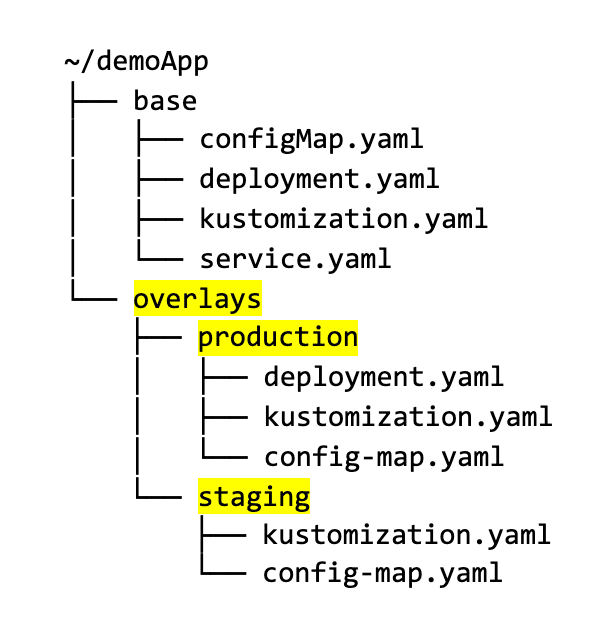
For Kustomize, you need to create a “base” configuration, and then each environment is modeled as an overlay that has its own folder:
In both cases, different environments are modeled with different folders/files. Helm and Kustomize know nothing about Git branches or Git merges or Pull Requests. They use just plain files.
Let me repeat that again: Both Helm and Kustomize use plain files for different environments and not Git branches. This should be a good hint on how to model different Kubernetes configurations using either of these tools.
If you introduce Git branches in the mix, you not only introduce extra complexity, but you also go against your own tooling.
The recommended way to promote releases in GitOps environments
Modeling different Kubernetes environments and promoting a release between them is a very common issue for all teams that adopt GitOps. Even though in DevOps (see GitOps vs DevOps) a very popular method is to use Git branches for each environment and assume that a promotion is a “simple” Git merge, we have seen in this article that this is an anti-pattern.
In the next article, we will see a better approach to model your different environments and promote releases between your Kubernetes cluster. The last point of the article (regarding Helm/Kustomize) should already give you a hint on how this approach works.
Stay tuned!
