Containers, containers, and once again containers. That’s the typical life of a modern-era software application. It’s hard to imagine a person from the world of software engineering that hasn’t heard about containers- specifically, Docker. Since its inception some 4 years ago, Docker rapidly became a synonym to containerization. In such a short span of time, the project grew from a promising tool to a huge ecosystem, rich in all kinds of integrations and customizations, and even mature enough to be run in production. In this article, we’re gonna talk about container orchestration tools and in particular, Docker Swarm, one of the tools we use at Codefresh.
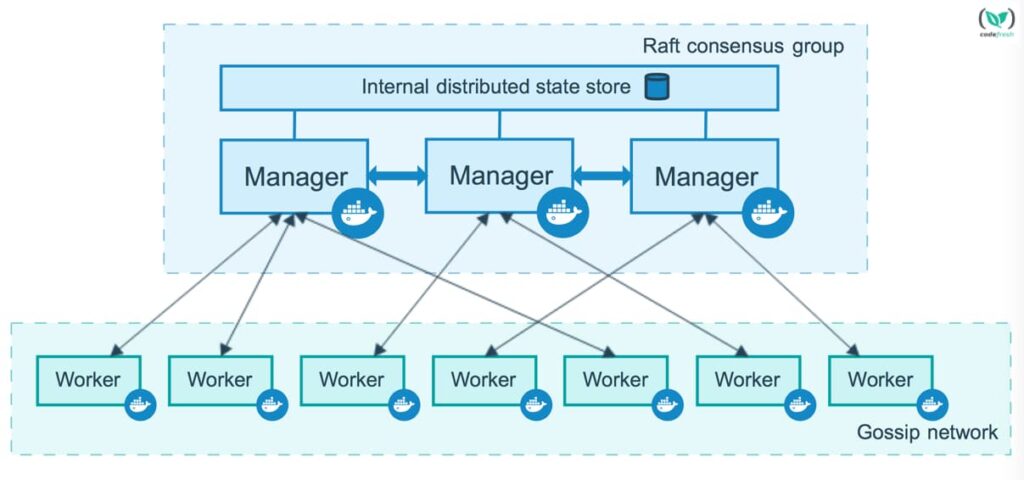
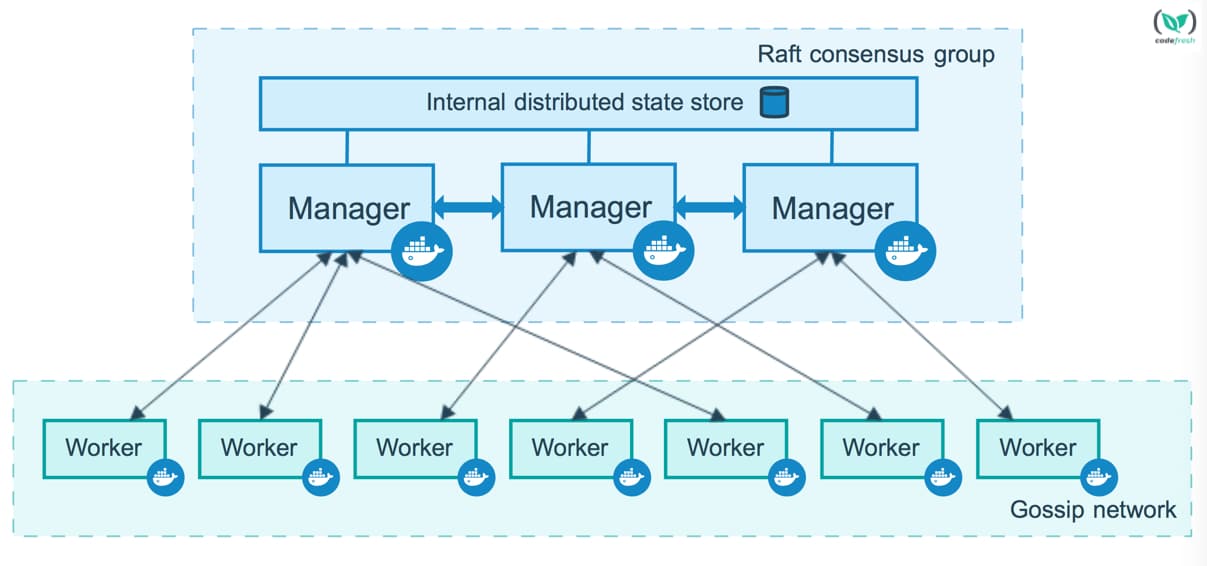
Picture 1 – Typical Docker Swarm Cluster
It’s almost impossible to run any decent amount of containerized applications without utilizing orchestration tools. No matter how small your scale is, you better have some orchestration present, so you don’t end up with containers roaming around unattended. Orchestration tools simplify container management; they provide a way to define a state and top-level architecture of your deployment, and it allows you to treat containers and groups of containers as single entities.
Nowadays, it seems to be a must for companies that offer container services to have their own orchestration tool. This is beneficial since it brings a diverse set of features and customizations and can fit almost every possible use case. On the other hand, many find this diversity detrimental- since it doesn’t help the unification of technologies. Currently, there are at least 3 key players in a world of orchestration, that have been around for quite a while, including Docker Swarm, Kubernetes, and Apache Mesos. Each tool has its own pros and cons, depending on how opinionated one wants to be. We will now take a closer look at Docker Swarm.
Since it’s inception in 2014, Docker Swarm was considered somewhat lacking in terms of built-in core features. For example, you had to use Docker Compose to describe services and relations between them. However, since the release of Docker version 1.12, everything has changed. Docker went down the direction of other competing tools and introduced built-in Swarm functionality, also known as “Swarm mode” or “Swarmkit”. It brought built-in native orchestration support, scaling and load balancing, service registration, support for declarative stack definitions (formerly known as aforementioned Compose), and many more features. This consolidation definitely allowed Docker to win some love from IT folks. Now let’s take a look at key features Swarm mode offers, and how they can be leveraged in real life (and yes, it can also run in production!).
Running a Service the Swarm Way
There are 2 ways to deploy something on Docker Swarm: using docker service create or docker stack deploy command. The first one allows you to create a single service (which is basically a set of containers), while the other allows you to leverage the Docker Compose format for declarative definition and run a service (or a multitude of them). Either way, you are able to specify lots of parameters for your deployment: replica numbers, networks to be used, ports to be exposed, environment variables to set, volumes to use, and many other things.
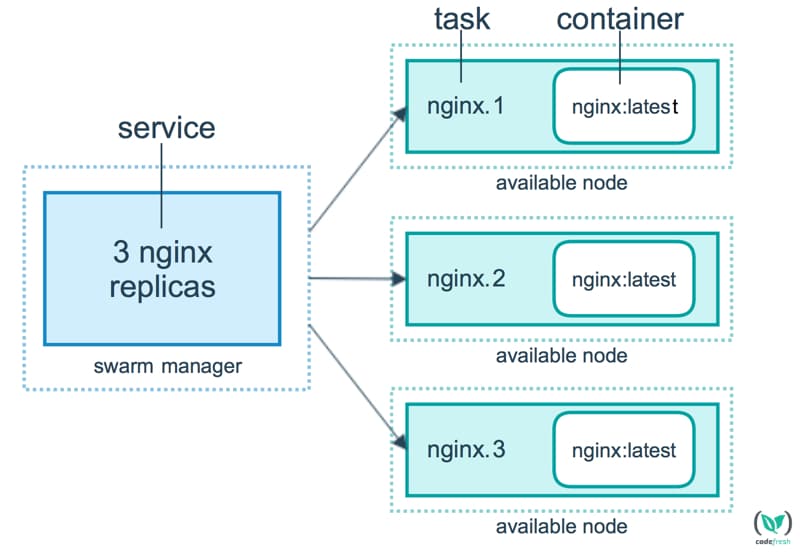
Picture 2 – Docker Service layout
Service Registration and Discovery
Each and every time you create or change a service in Docker Swarm, a series of events happen. Docker accepts the details of your service, allocates resources across a cluster, schedules and runs containers on nodes. But most importantly, it registers information about each service internally. At a later stage, these details are used to register the service with your internal DNS server and build the routing mesh for load balancing.
Scaling and Load Balancing
A pretty straightforward feature. Leveraging docker service scale command you are able to scale up/down and even put a service in a sort of disabled way, by setting scaling factor to 0. Behind the scenes, the Docker daemon will schedule an X amount of containers (also known as tasks) across the cluster and adjust a balancing mechanism (routing mesh) to include/exclude IP addresses of containers. By default, load balancing is done using a round robin algorithm.
Declarative Stack Definitions
You can provide definitions in a form of either DAB (Distributed Application Bundle) or Docker Compose file (supported versions are v2 and v3). The latter is much more popular since it presents the well known Compose files, but are rich with service-specific features. It provides the ability to define a wide variety of deployment-related settings (number of replicas, rolling update settings, placement constraints, etc), alongside with the usual things, like entrypoint, healthchecks, and networks. The full reference of available features can be found here and it keeps growing.
That being said, these key features are only the tip of the iceberg. There are many other things that Swarm mode brings to the table. For example, there have been a lot of improvements in their security model (enforcing TLS mutual authentication and encryption), along with an ever-growing amount of supported plugins (networking and volumes). So, if you want to consider using Docker Swarm (also in production), first you’ll have to assess how ready you are for containers. To help you with it, we have a blog which describes major things you have to consider. If you’ve already started your journey into a containerized world, you’ll face fewer challenges. There will be a need to adapt to the Swarm way of things, leverage the way it discovers services, the way its networking works, and how you can provide dynamic configuration to your applications. There’s definitely a good amount of features for every flavor of application. Upon more in-depth research, you’ll find things like built-in healthchecks, simple secret management, and a wide variety of network and volume drivers. If your application is crafted in a way that these features can be properly leveraged, you will definitely see no problem in doing it the Swarm way. Buckle up and enjoy your ride!
